从锅炉工到AI专家(1)
TensorFlow实务
序言
标题来自一个很著名的梗,起因是知乎上一个问题:《锅炉设计转行 AI,可行吗?》,后来就延展出了很多类似的问句,什么“快递转行AI可行吗?”、“xxx转行AI在线等挺急的”诸如此类。
其实知乎原文是个很严肃的问题,很多回答都详尽、切题的给出了可行的方案。AI的门槛没有很多人想象的那么高,关键在于你是满足于只是看几个概念就惊呼“人工智能将颠覆xxxx行业,xxxx人将失去工作”、“人工智能将会毁灭人类”,还是你真的打算沉下心来学一些人工智能的知识,学习用另外一种方法和视角了解这个世界。
所以本文其实也是一篇很严肃的文章,标题的本意只是想说本文从最基础的概念讲起,即使是非IT技术人员,也应当能看懂。至于网上泛滥的所谓0基础学AI,我敢说,你也不应当相信才对。
我们都知道自从行业意识到人工智能的重要性以来,各大IT巨头都纷纷发布了自己的人工智能技术框架,其中Google发布的TensorFlow算是发表比较早、经过多次迭代也比较成熟的一个框架。目前碰到的问题是,很多人学习了TensorFlow,翻完了所有文档,演练了所有的示例代码,仍然感觉对AI一头雾水,不知道如何入手具体的工作。本文就试图从最初讲起,一开始完全不涉及技术,逐渐在提出问题和解决问题的过程中,将TensorFlow导入,让读者知道来龙去脉,从而可以把人工智能应用到工作中,并且从思路上帮助非IT专业人士,优化自己的工作。
人工智能
人工智能并不是新事物,只是这两年,特别是“阿尔法狗战胜人类”这个热点事件之后才格外的火起来。IT行业和资本领域都属于特别爱炒作概念的行业,随着时间的流逝,有些概念保留了下来,有些则变得无人问津,但大多数,都是在喧嚣过后,才逐渐的回归到本源。等待回归本源的时候,真正抓住核心和本质的人,才能有机会走的更远。
计算机最早发明出来,就有人给它起了一个名字叫“电脑”,实际上从那天开始人们就意识到,计算机是人脑的一个延伸,人们已经试图用计算机实现原有人类智能才能解决的工作,这应当看做“人工智能”实践的标志性起源。
经过几十年的发展,在人工智能方面的技术和理论发展越来越成熟,技术人员已经有了一整套系统和规范的方法来应对此类问题。这些方法,基本是对大量的数据集进行处理,总结和发现规律,并将这些规律应用到新的数据集上。前半部分类似于人的学习过程,后半部分类似于人使用学到的知识解决问题的过程。所以这个过程也被称作“机器学习”,以及延伸而来的“深度学习”、“加强学习”、“迁移学习”等。所以“机器学习”,才是当前“人工智能”热之中的基本研究方向之一。
现状
试图解释AI领域的现状其实是一个比较不讨好的事情,特别是在信息快餐化的时代,真假新闻都已经够让人崩溃了。聊天的时候,经常碰到说不了几句就会被人打断,随后引用几个听起来很神奇,实际上漏洞百出的新闻标题来证明你不过是一无所知。
为了简化问题,这里引用两个概念来做一个澄清:
- 一个概念是“强人工智能”,是指人工智能可能具有人类完整的认知能力,可以推理、感知,并且因为速度和容量方面的优势,将来必将超越人类达到无所不知、无所不能的“类神”的境地,这也是科幻小说的的主要模式之一。
- 另一个概念是“弱人工智能”,这也是当前业界主要的研究方向,弱人工智能不需要具有人类完整的认知能力,甚至是完全不具有人类所拥有的感官认知能力,只需要在某个特定领域具备特定的能力就可以。我们当前所见到的“阿尔法狗”、“人脸识别”、“机器翻译”等,都属于这个领域。
这两个概念,其实最早开始的时候是两个互相争执不下的观点,一派认为人工智能将来必将远胜于人类,甚至取代人类,也就是“强人工智能”派;对应的则是认为人工智能不可能取代人类,人工智能只能在某些领域发挥作用,最终依然会从属和辅助人类,也就是“弱人工智能”派。我们在这里并没打算涉及这两派观点的争论,只是借用这两个概念来说明当前人工智能的现状。
那就是,在当前的技术情况下,“弱人工智能”的发展兴旺蓬勃,在很多领域已经远远的超过了人类,并且的确对该领域的从业人员产生了重大的影响,从技术、理念的革新,到人力资源的岗位转移。
“强人工智能”的发展则应当说仍在探索中,离达到一个正常人基本智力水平的基本目标尚有很大差距,且远远还没有看得到的、令人信服的技术出现。
关于“人工智能最终超过人类”的说法,我个人的观点是比较悲观的,即便从时间跨度上给出一个相当宽松的计划表,人工智能想超过人类的难度也非常大。主要原因来自于我们都知道的《物种起源》,我们知道人类生理方面的进化的主要模式是遗传和变异,在精神方面中则是“传承”和“发展”。这些“变异”或者“发展”其实主要的来源都是“犯错”。有些犯错是好的,加上环境的允许,这些犯过的“错”保留下来,成为新的知识。而有些错则是致命的,即便其中有可取之处,但可能个体都无法存续,更无法发展和传承。
而“机器”则很难或者说远远低于正常人类可能有的“犯错”水平,从某种角度说,这正是人们喜欢用电脑的原因之一,电脑很少犯错,但也就此失去了很多“进化”的机会。
关于现状,最后一个要说的是,现在人工智能这么火,里面有泡沫吗?这一点我想引用比尔盖茨在1999年达沃斯世界经济论坛期间一个著名的回答,当时正是高科技泡沫的巅峰时期。盖茨一次又一次地被记者们问到相似的问题:“盖茨先生,现在的网络股是泡沫股,对吗?它们难道不是泡沫吗?”最后,有点被激怒得盖茨对记者们说:“他们当然是泡沫,但你们没有问到点子上。泡沫给网络行业带来了很多新资本,这必将更快地推动创新。”
所以,其实我也认为现在的“人工智能”以及“机器人”领域充斥着泡沫,但这同时也引发了全社会的关注和重视,从而推动了这个领域的快速进步,并持续的带来新的人才、新的创新。但是对于有意愿投资在这一行的人来说,你愿不愿意踏踏实实的做事。即便不成功,也在技术上或者经验上留下一些痕迹,才是值得考虑的事情。
机器学习基本假设
好了,下面到了我们的正课时间。
目前的机器学习已经有了多种被证明行之有效的算法,而这些算法都基于一个很重要的假设,那就是这个世界上所有的问题,都是可以用数学来描述的。小到用电脑识别的一副照片,大到用11维空间来描述整个宇宙的弦论,都是有与之对应的数学模型的。通过数学模型来解决问题,大概是这样一个流程:数据输入 -> 数学公式 -> 结果 。
而在机器学习理论之前,我们依赖电脑解决问题,则是通过: 数据输入 -> 计算机程序 -> 结果。
我们都知道,所有数学公式,最终都是可以对应转化成计算机程序的,那这两种方式区别在哪?我们举一个例子:
比如我们可以在屏幕上,显示出 LOVE 这样几个字母,对电脑最简单不过,高级语言就是一行命令。当然背后隐藏的就复杂了,要把这几个字母通过光栅矢量化,然后通过显卡的驱动,把字母的矢量点阵化,然后再绘制到屏幕上去。刚才叙述的这个复杂的过程,都是由程序完成的,程序的主要组成部分是逻辑,虽然“逻辑”也是高等数学重要的一部分,但这里说的“逻辑”更多的则是由人的思维产生,至少首先要由程序员在大脑中先形成并几经反复、修正,然后仿照这个过程形成计算机的程序,这个过程更多的人本身的学习,而不是“机器学习”。
那么这么复杂的“字符”,用数学公式可能描述出来吗?当然是可以的,几乎一切你想的到的东西,都是可以用数学来描述的,这也是这一节开头那个概念的由来。
更复杂一点,三维的图形,也是一样的:
你可能会说,不对啊,怎么感觉用数学的方式来画出几个字符,比原来在屏幕上显示这几个字符的方法麻烦多了?先别急,这里的重点只是想告诉你,用数学方法解决问题同用单纯程序解决问题的区别。机器学习不是万能的,在很多领域,用传统的程序解决会更容易。千万不要成为“只要手里有个锤子,看全世界的问题都像是钉子”。但也有很多领域,用传统的程序,可能根本做不到。
总结一下,我们假设一切问题都是可以用数学来描述的,在很多大神已经发明的公式中找出适合这个问题的那一个,甚至自己改善或者重新研究、发现一个,然后把公式用计算机程序的方式描述出来,也就是算法,就可以解决这个问题。引用某个演讲中的一句话:音乐是感情的语言,数学是科学的语言。
一个最简单的例子
我们都知道,解决一个复杂的问题的方法,是把复杂的问题分解成一连串的简单问题。一个高维数学问题如果想不明白,往往也是降低维度来思考。我们下面先从一个最简单的问题入手,来逐步导入机器学习的算法。
假设你在一个房屋中介工作,你手头有很多房屋租售价格的信息,每天都会有很多客户来咨询你租房或者买房的事情,我们假设是买房,常见的问题会是:在甲地,x平米的房子,多少钱能买下来?
根据需求我们可以列出一个公式:y = a * x + b(仅作示例,请忽略一些不合常理的地方)
这个公式里,y代表我们预测的房价,a是每平米的价格,x是平米数,b是税、手续费等基本的固定费用。
我心中有些忐忑,我觉得会不会很多人都在笑,小学问题是吧?不要急,耐心看下去,“降维”思考,本来就是把复杂的问题简单化。
比如在某个地区,我们手头有多套房屋信息,售价、面积我们都知道,简单把公式变换一下, a = (y-b)/x,把我们手头的信息代入进去,很容易就能算出来该地区每平米的单价。以后碰到客户咨询的时候,利用这个公式,我们就能预测出来用户想要的房子,大概需要多少钱买到。
太简单了是吧?好像看不到什么“机器学习”的东西在里面啊?就是简单的解方程嘛,虽然要求解的变量从“x”变成了“a”。
的确是这样的, 机器学习根本的目的,就是解方程 。对于简单的方程,比如刚才的方程,因为只有两个要求得的变量a和b,根据解方程的知识,我们只要有两组已知的x和y,就可以准确的求出这个方程的解。别扭一点的无非是我们上学的时候习惯用x/y/z代表未知数,a/b/c代表常数。
现在反了过来,我们手头的数据集给出了x/y的值,原来的常数反而成了未知数。原因是,求得这些常数并不是目的,目的是利用这些常数,补全了公式,在以后我们就可以利用这个完整的公式和给定的x,去预测y的值。
总结这一节:利用已知数据求解这些常数的过程,就是“机器学习”的过程;利用补全的公式,对新数据预测结果的过程,则是“人工智能”。这个公式则是我们“机器学习”的工作重点:数学模型。
解方程
最简单的方程可以手工求解,就像上一节中房价的例子,只有两个变量。而且房价嘛,常见的不过几十平米、一、二百平米的数量级,小学毕业之后的水平,心算足够了。
再复杂一点,有多个变量,就需要一些解方程的公式,或者也可以叫算法。为什么会有多个变量?我们上一节为了简化问题,只考虑了面积、税费这些基本要素,一套房子,朝向、楼层、物业、学区等等,显然都会成为影响房价的因素。真得严谨考虑,这里面可变的因素真的很多的。关于这些变量的问题,我们留给下一节,这里继续说解方程的问题。
我们知道,通常情况下,多元方程,需要方程组来求解。有n个未知数,就要列出n个方程构成的方程组,并且利用n组已知的数据来解方程组获得答案。恐怕当未知数达到了4、5个,心算已经不够了。好在当前已经有很多数学工具帮助我们做这样的事情。比如在斯坦福《机器学习》课程中,吴恩达教授使用Octave来全程讲解机器学习。Octave是著名数学软件MatLab的社区开源版本,如果没有接触过的读者,你可以把它理解成一个比较专业的大计算器,Octave长于数值计算(对应的还有Mathematica,长于符号计算),内置有自己的编程语言,在很多的机器学习场景中,研究人员都是利用这样的软件进行算法原型的研究和设计。验证成功后,才由计算机方面的专家把公式转换成计算机的编程语言,成为算法。
下面举一个五元一次方程组的例子:
(备注,这些内容,不需要你动手实验,只是希望你延续并加深理解这个思路,明白是什么和为什么就好,最终我们肯定会回归到TensorFlow的学习上。)
2a+b+c+d+e=6 a+2b+c+d+e=12 a+b+2c+d+e=24 a+b+c+2d+e=48 a+b+c+d+2e=96
仅是一个例子,这样的方程你用手工解估计也很快啦,这里用Octave演示一个有限元的方程组解法,大概这样几步:
- 首先规范化方程,让每一行的方程左侧,具有相同的变量数,没有的变量用“0*变量”的形式来替代;右侧,则是统一只有1个常数,不是单一常数的,则要通过简化,成为仅有一个常数。好在我们举的例子很规范,没有这样的情况。
- 在Octave中,把式子左侧的所有系数提取出来,每个方程式占独立一行,所有方程式形成一个“矩阵”,假设矩阵叫A。
- 在Octave中,把式子右侧的常数输入成为另外一个矩阵,因为只有一列,实际也可以称为“向量”,我们假设这个向量叫B。
- 使用Octave内置函数求解:ans=pinv(A)*B,此时得到一个1维矩阵,也就是向量,每一行是一个未知数的解。a=-25;b=-19;c=-7;d=17;e=65。
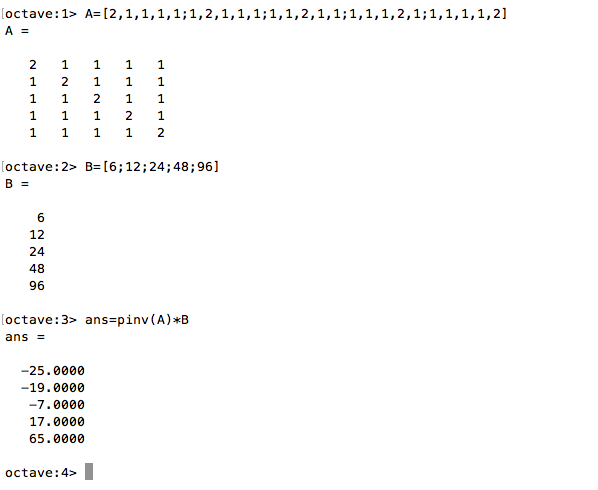
其实Octave对于解方程还提供了一个简写的方式:在Octave命令行直接键入A \ B,也可以得到答案。
(python也有对应的矩阵运算库,也提供同样的方程求解的功能,我们到后面再说,就让这第一部分保持一个写给非IT专业人员的状态吧。)
注:在我们后面将要学习的TensorFlow中,“矩阵”也称为张量(tensor)。处理过程是数据的流动(flow),这也是TensorFlow名称的由来。但为了描述语言更通用,以后我们仍然称为矩阵。
总结一下这一节:
- 简单的方程有成熟的公式或者工具帮你解,但重点你肯定意识到了,复杂方程这些方法就不灵了,这引出了机器学习的重点之一,就是如何解复杂的方程,我们后续会讲到。
- 为了应对新的AI问题,我们可能需要研究新的机器学习算法。研究这些算法的工具是数学公式,研究数学公式的工具,Octave算一个,可能经常会用在新算法的原型研究。这只是指出一个学习的方向,至少现在,会走之前,先不用考虑跑的事情。当然也有很多数学专家,只研究公式和算法,从来不进行TensorFlow编程和应用,Octave用的很熟练,这类用户不是本文的重点。
- 我们手工计算一些方程,通常都是一组一组的数据逐个代入,这很容易理解。但是在大规模计算的时候,类似刚才Octave这样的做法,把数据集矩阵化才是通常的模式,这样可以充分的利用计算机规模化和并行的优势,所以搞机器学习,矩阵运算不熟悉的,最好抽时间去补一下。
(待续…)
