从锅炉工到AI专家(10)
TensorFlow实务
RNN循环神经网络(Recurrent Neural Network)
如同word2vec中提到的,很多数据的原型,前后之间是存在关联性的。关联性的打破必然造成关键指征的丢失,从而在后续的训练和预测流程中降低准确率。
除了提过的自然语言处理(NLP)领域,自动驾驶前一时间点的雷达扫描数据跟后一时间点的扫描数据、音乐旋律的时间性、股票前一天跟后一天的数据,都属于这类的典型案例。
因此在传统的神经网络中,每一个节点,如果把上一次的运算结果记录下来,在下一次数据处理的时候,跟上一次的运算结果结合在一起混合运算,就可以体现出上一次的数据对本次的影响。
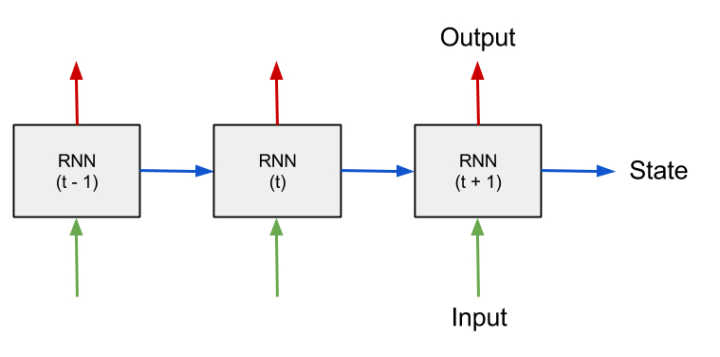
如上图所示,图中每一个节点就相当于神经网络中的一个节点,t-1 、 t 、 t+1是指该节点在时间序列中的动作,你可以理解为第n批次的数据。
所以上面图中的3个节点,在实现中实际是同1个节点。
指的是,在n-1批次数据到来的时候,节点进行计算,完成输出,同时保留了一个state。
在下一批次数据到来的时候,state值跟新到来的数据一起进行运算,再次完成输出,再次保留一个state参与下一批次的运算,如此循环。这也是循环神经网络名称的由来。
RNN算法存在一个问题,那就是同一节点在某一时间点所保存的状态,随着时间的增长,它所能造成的影响就越小,逐渐衰减至无。这对于一些长距离上下文相关的应用,仍然是不满足要求的。
这就又发展出了LSTM算法。
LSTM长短期记忆网络(Long Short-Term Memory)

如图所示:LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。
一个cell当中被放置了三个“门电路”,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。
- 遗忘门决定让哪些信息继续通过这个cell。
- 输入门决定让多少新的信息加入到 cell状态中来。
- 输出门决定我们要输出什么样的值。
通过这样简单的节点结构改善,就有效的解决了长时序依赖数据在神经网络中的表现。
LSTM随后还出现了不少变种,进一步加强了功能或者提高了效率。比如当前比较有名的GRU(Gated Recurrent Unit )是2014年提出的。GRU在不降低处理效果的同时,减少了一个门结构。只有重置门(reset gate)和更新门(update gate)两个门,并且把细胞状态和隐藏状态进行了合并。这使得算法的实现更容易,结构更清晰,运算效率也有所提高。
目前的应用中,较多的使用是LSTM或者GRU。RNN网络其实已经很少直接用到了。
实现一个RNN网络
官方的RNN网络教程是实现了一个NLP的应用,技术上很切合RNN的典型特征。不过从程序逻辑上太复杂了,而且计算结果也很不直观。
为了能尽快的抓住RNN网络的本质,本例仍然延续以前用过的MNIST程序,把其中的识别模型替换为RNN-LSTM网络,相信可以更快的让大家上手RNN-LSTM。
本例中的源码来自aymericdamien的github仓库,为了更接近我们原来的示例代码,适当做了修改。在此对原作者表示感谢。
官方的课程建议在读完这里的内容之后再去学习,并且也很值得深入的研究。
源码:
#!/usr/bin/env python
# -*- coding=UTF-8 -*-
""" Recurrent Neural Network.
A Recurrent Neural Network (LSTM) implementation example using TensorFlow library.
This example is using the MNIST database of handwritten digits (http://yann.lecun.com/exdb/mnist/)
Links:
[Long Short Term Memory](http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf)
[MNIST Dataset](http://yann.lecun.com/exdb/mnist/).
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
"""
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
#这里指向以前下载的数据,节省下载时间
#使用时请将后面的路径修改为自己数据所在路径
mnist = input_data.read_data_sets("../mnist/data", one_hot=True)
'''
To classify images using a recurrent neural network, we consider every image
row as a sequence of pixels. Because MNIST image shape is 28*28px, we will then
handle 28 sequences of 28 steps for every sample.
'''
# Training Parameters
#训练梯度
learning_rate = 0.001
#训练总步骤
training_steps = 10000
#每批次量
batch_size = 128
#每200步显示一次训练进度
display_step = 200
# Network Parameters
#下面两个值实际就是28x28的图片,但是分成每组进入RNN的数据28个,
#然后一共28个批次(时序)的数据,利用这种方式,找出单方向相邻两个点之间的规律
#这种方式当时不如CNN的效果,但我们这里是为了展示RNN的应用
num_input = 28 # MNIST data input (img shape: 28*28)
timesteps = 28 # timesteps
#LSTM网络的参数,隐藏层数量
num_hidden = 128 # hidden layer num of features
#最终分为10类,0-9十个字付
num_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
#训练数据输入,跟MNIST相同
X = tf.placeholder("float", [None, timesteps, num_input])
Y = tf.placeholder("float", [None, num_classes])
# Define weights
#权重和偏移量
weights = tf.Variable(tf.random_normal([num_hidden, num_classes]))
biases = tf.Variable(tf.random_normal([num_classes]))
def RNN(x, weights, biases):
# Prepare data shape to match `rnn` function requirements
# Current data input shape: (batch_size, timesteps, n_input)
# Required shape: 'timesteps' tensors list of shape (batch_size, n_input)
# Unstack to get a list of 'timesteps' tensors of shape (batch_size, n_input)
#进入的数据是X[128(批量),784(28x28)]这样的数据
#下面函数转换成x[128,28]的数组,数组长度是28
#相当于一个[28,128,28]的张量
x = tf.unstack(x, timesteps, 1)
# Define a lstm cell with tensorflow
#定义一个lstm Cell,其中有128个单元,这个数值可以修改调优
lstm_cell = rnn.BasicLSTMCell(num_hidden, forget_bias=1.0)
# Get lstm cell output
#使用单元计算x,最后获得输出及状态
outputs, states = rnn.static_rnn(lstm_cell, x, dtype=tf.float32)
# Linear activation, using rnn inner loop last output
#仍然是我们熟悉的算法,这里相当于该节点的激活函数(就是原来rule的位置)
return tf.matmul(outputs[-1], weights) + biases
#使用RNN网络定义一个算法模型
logits = RNN(X, weights, biases)
#预测算法
prediction = tf.nn.softmax(logits)
# Define loss and optimizer
#代价函数、优化器及训练器,跟原来基本是类似的
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model (with test logits, for dropout to be disabled)
#使用上面定义的预测算法进行预测,跟样本标签相同即为预测正确
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
#最后换算成正确率
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, training_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
#首先把数据从[128,784]转换成[128,28,28]的形状,这跟以前线性回归是不同的
batch_x = batch_x.reshape((batch_size, timesteps, num_input))
# Run optimization op (backprop)
#逐批次训练
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
#每200个批次显示一下进度,当前的代价值机正确率
loss, acc = sess.run([loss_op, accuracy], feed_dict={X: batch_x,
Y: batch_y})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
# Calculate accuracy for 128 mnist test images
#训练完成,使用测试组数据进行预测
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, timesteps, num_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: test_data, Y: test_label}))
跟原来的MNIST代码对比,本源码有以下几个修改:
- 常量在前面集中定义,这是编程习惯上的调整,跟TensorFlow及RNN-LSTM无关
- 核心算法替换成了RNN,在RNN函数中实现,其中主要做了3个动作:
- 首先把数据切成28个数据一个批次。原来从训练集中读取的数据是[128批次,784数据]的张量。
随后在主循环中改成了:[128,28,28]的张量喂入RNN。注释中有说明,这是利用RNN的特征,试图寻找每张图片在单一方向上相邻两个点之间是否存在规律。
RNN中第一个动作就是按照时序分成28个批次。变成了[28,128,28]的样式。 - 随后定义了一个基本的LSTM Cell,包含128个单元,这里可以理解为神经网络中的隐藏层。
- 最后使用我们熟悉的线性回归作用到每一个输出单元中去,在这里,这个线性回归也相当于神经网络中每个节点的激活函数。
- 首先把数据切成28个数据一个批次。原来从训练集中读取的数据是[128批次,784数据]的张量。
- 交叉熵的计算又换了一种算法:softmax_cross_entropy_with_logits,同我们前面用过的sparse_softmax_cross_entropy功能是接近的,基本可以互相代换。
- 随后的训练和预测,基本同原来的算法是相同。
运算结果:
Step 9000, Minibatch Loss= 0.4518, Training Accuracy= 0.859
Step 9200, Minibatch Loss= 0.4717, Training Accuracy= 0.852
Step 9400, Minibatch Loss= 0.5074, Training Accuracy= 0.859
Step 9600, Minibatch Loss= 0.4006, Training Accuracy= 0.883
Step 9800, Minibatch Loss= 0.3571, Training Accuracy= 0.875
Step 10000, Minibatch Loss= 0.3069, Training Accuracy= 0.906
Optimization Finished!
Testing Accuracy: 0.8828125
训练的结果并不是很高,因为对于图像识别,RNN并不是很好的算法,这里只是演示一个基本的RNN-LSTM模型。
自动写诗
上面的例子让大家对于RNN/LSTM做了入门。实际上RNN/LSTM并不适合用于图像识别,一个典型的LSTM应用案例应当是NLP。我们下面再举一个这方面的案例。
本节是一个利用唐诗数据库,训练一个RNN/LSTM网络,随后利用训练好的网络自动写诗的案例。
源码来自互联网,作者:斗大的熊猫,在此表示感谢。
为了适应python2.x+TensorFlow1.4.1的运行环境,另外也为了大家读起来方便把训练部分跟生成部分集成到了一起,因此源码有所修改。也建议大家去原作者的博客去读一读相关的文章,会很有收获,在引文中也有直接的链接。
源码讲解:
- 首先是唐诗的数据库,可以在此链接下载到:全唐诗(43030首)
- readPoetry()函数中,读取了全部的唐诗,分离并抛弃掉标题部分,因为这部分往往不符合诗词的一般格式,参与诗词的训练没有意义。
随后对诗词进行基本的归一化,诸如剔除空格、根据字数分类。原诗中包含说明、介绍、引用等不署于诗词的部分,因为这部分数据完全不规范不能自动处理,所以这样的诗词干脆剔除掉不参与训练。
最后得到的样本集,每首诗保持了中间的逗号和句号,用于体现逗号、句号跟之前的字的规律。此外认为在开头和结尾增加了”[“和”]”字符。用于体现每首诗第一个字和最后一个字跟相邻字之间的规律。 - 接着把诗文向量化,就是上一篇word2vec的工作。但这个源码估计为了降低工作量,没有进行分词,程序假定每个字就是一个词,多字词的关系会被丢失,但这在后面“自动写诗”的环节会比较容易处理,否则可能造成每句诗中因为词语的存在而字数不同。另外一点就是没有把同义词在向量空间中拉近相关的距离,这里也是为了简化操作。也可以说还存在改进的空间。
- genTrainData()以64首诗为一个批次,生成了训练数据集x_batches/y_batches,因为总体算诗词的数据集比较小。这里没有动态逐批次生成,而是一次生成到两个数组中去。在训练结束生成古诗的时候,这部分实际是没有用的,但训练跟生成集成在同一个程序中,就忽略这点工作了。需要注意的是,生成古诗的时候,批次会设定为1,因为是通过一个汉字预测下一个汉字。
- neural_network()函数中定义了RNN/LSTM网络,实际上这个主函数考虑了使用RNN / LSTM / GRU三种网络的构建选择,可以任意选择其一。在这里使用了python函数可以跟变量一样赋值并调用的特性,读源码的时候可以注意一下。
与上一个例子还有一点不同,就是这里使用了两层的RNN网络,回忆一下多层神经网络,理解这个概念应当不难。这项工作是由tf.nn.rnn_cell.MultiRNNCell函数完成的。
tf.get_variable()函数也是定义TensorFlow变量,我们之前一直使用tf.Variable(),两者功能类似,前者更适合在作用域的管理下共享变量。
接着要介绍的是个重点:tf.nn.dynamic_rnn,我们前面说过,因为是时序输入的计算模式,所以输入数据可以是不等长的,这是RNN网络的特征之一。我们之前所有的案例,每个训练批次的数据必须是定长,上一个RNN案例中也使用了rnn.static_rnn,这表示使用定长的数据集。
后面的激活函数再次是我们熟悉的softmax,这次等于是把上面数字化之后的唐诗中的汉字做成一个库,分类到其中之一,即为推测出的下一个字。
总结一下模型部分:唐诗数字化的时候,完整的保留了每首诗开头文字、结尾文字、每句的结尾文字之间的关系。所建立的RNN模型,实际上会以上一个文字,预测下一个文字,甚至标点符号都是预测而得到的。 - 随后的训练部分train_neural_network()没有太多新概念,要注意的是每次调用模型的训练,会保留其last_state,并在下个批次训练的时候,迭代进去。这是我们前面讲RNN模型的时候说过的。而这种模式,是在之前的各种模型中没有出现过的。
- gen_poetry()自动生成诗句是一个很完整的预测,初始的值会是一个字符”[“,表示一个诗的开始,我们样本中,每首诗的开始都是人为增加的“[”字符。RNN模型肯定不会对这么高频的规律搞错。这种模式生成的古诗虽然远远比不上人的作品,但可读性还是比较好的。
- 藏头诗部分gen_poetry_with_head(),这部分生成的会比较牵强。原因是,人为指定的藏头诗第一个字,不可能刚好吻合唐诗数据库中每句第一个字的规律,因此直接预测出来,很可能没有完成一句话,就已经是句号或者逗号。
程序只能根据预置的句长(这里指定七言),跳过逗号、句号以及结束符号“]”,跳过之后再次重新生成,其实已经不符合一句话中的规律,但为了达到藏头诗的效果,也只能如此。 - 训练模型使用的批次是64。生成时候所使用的预测模型批次是1,因为使用一个汉字去预测后一个。这个在main()中会自动调整。
其余的部分相信凭借注释和以前的经验应当能看懂了:
#!/usr/bin/env python
# -*- coding=UTF-8 -*-
# source from:
# http://blog.topspeedsnail.com/archives/10542
# poetry.txt from:
# https://pan.baidu.com/s/1o7QlUhO
# revised: andrew
# https://formoon.github.io
# add python 2.x support and tf 1.4.1 support
#------------------------------------------------------------------#
import collections
import numpy as np
import tensorflow as tf
import argparse
import codecs
import os,time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#-------------------------------数据预处理---------------------------#
poetry_file ='poetry.txt'
# 诗集
poetrys = []
def readPoetry():
global poetrys
#with open(poetry_file, "r", encoding='utf-8',) as f:
with codecs.open(poetry_file, "r","utf-8") as f:
for line in f:
try:
content = line.strip().split(':')[1]
#title, content = line.strip().split(':')
content = content.replace(' ','')
if '_' in content or '(' in content or '(' in content or '《' in content or '[' in content:
continue
if len(content) < 5 or len(content) > 79:
continue
content = '[' + content + ']'
poetrys.append(content)
except Exception as e:
pass
# 按诗的字数排序
poetrys = sorted(poetrys,key=lambda line: len(line))
#for item in poetrys:
# print(item)
# 统计每个字出现次数
readPoetry()
all_words = []
for poetry in poetrys:
all_words += [word for word in poetry]
# print poetry
# for word in poetry:
# print(word)
# all_words += word
counter = collections.Counter(all_words)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
words, _ = zip(*count_pairs)
#print words
# 取前多少个常用字
words = words[:len(words)] + (' ',)
# 每个字映射为一个数字ID
word_num_map = dict(zip(words, range(len(words))))
#print(word_num_map)
# 把诗转换为向量形式,参考word2vec
to_num = lambda word: word_num_map.get(word, len(words))
poetrys_vector = [ list(map(to_num, poetry)) for poetry in poetrys]
#[[314, 3199, 367, 1556, 26, 179, 680, 0, 3199, 41, 506, 40, 151, 4, 98, 1],
#[339, 3, 133, 31, 302, 653, 512, 0, 37, 148, 294, 25, 54, 833, 3, 1, 965, 1315, 377, 1700, 562, 21, 37, 0, 2, 1253, 21, 36, 264, 877, 809, 1]
#....]
# 每次取64首诗进行训练
batch_size = 64
n_chunk = len(poetrys_vector) // batch_size
x_batches = []
y_batches = []
def genTrainData(b):
global batch_size,n_chunk,x_batches,y_batches,poetrys_vector
batch_size=b
for i in range(n_chunk):
start_index = i * batch_size
end_index = start_index + batch_size
batches = poetrys_vector[start_index:end_index]
length = max(map(len,batches))
xdata = np.full((batch_size,length), word_num_map[' '], np.int32)
for row in range(batch_size):
xdata[row,:len(batches[row])] = batches[row]
ydata = np.copy(xdata)
ydata[:,:-1] = xdata[:,1:]
"""
xdata ydata
[6,2,4,6,9] [2,4,6,9,9]
[1,4,2,8,5] [4,2,8,5,5]
"""
x_batches.append(xdata)
y_batches.append(ydata)
#---------------------------------------RNN--------------------------------------#
# 定义RNN
def neural_network(input_data, model='lstm', rnn_size=128, num_layers=2):
if model == 'rnn':
cell_fun = tf.nn.rnn_cell.BasicRNNCell
elif model == 'gru':
cell_fun = tf.nn.rnn_cell.GRUCell
elif model == 'lstm':
cell_fun = tf.nn.rnn_cell.BasicLSTMCell
cell = cell_fun(rnn_size, state_is_tuple=True)
cell = tf.nn.rnn_cell.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [rnn_size, len(words)+1])
softmax_b = tf.get_variable("softmax_b", [len(words)+1])
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [len(words)+1, rnn_size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
outputs, last_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state, scope='rnnlm')
output = tf.reshape(outputs,[-1, rnn_size])
logits = tf.matmul(output, softmax_w) + softmax_b
probs = tf.nn.softmax(logits)
return logits, last_state, probs, cell, initial_state
#训练
def train_neural_network():
global datafile
input_data = tf.placeholder(tf.int32, [64, None])
output_targets = tf.placeholder(tf.int32, [64, None])
logits, last_state, _, _, _ = neural_network(input_data)
targets = tf.reshape(output_targets, [-1])
#loss = tf.nn.seq2seq.sequence_loss_by_example([logits], [targets], [tf.ones_like(targets, dtype=tf.float32)], len(words))
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [targets], [tf.ones_like(targets, dtype=tf.float32)], len(words))
cost = tf.reduce_mean(loss)
learning_rate = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), 5)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.apply_gradients(zip(grads, tvars))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#saver = tf.train.Saver(tf.all_variables())
saver = tf.train.Saver()
for epoch in range(50):
sess.run(tf.assign(learning_rate, 0.002 * (0.97 ** epoch)))
n = 0
for batche in range(n_chunk):
train_loss, _ , _ = sess.run([cost, last_state, train_op], feed_dict={input_data: x_batches[n], output_targets: y_batches[n]})
n += 1
print(epoch, batche, train_loss)
if epoch % 7 == 0:
#保存的数据,文件名中有批次的标志
saver.save(sess, datafile, global_step=epoch)
#-------------------------------生成古诗---------------------------------#
# 使用训练完成的模型
def gen_poetry():
global datafile
input_data = tf.placeholder(tf.int32, [1, None])
output_targets = tf.placeholder(tf.int32, [1, None])
def to_word(weights):
t = np.cumsum(weights)
s = np.sum(weights)
sample = int(np.searchsorted(t, np.random.rand(1)*s))
return words[sample]
_, last_state, probs, cell, initial_state = neural_network(input_data)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
#读取最后一个批次的训练数据
saver.restore(sess, datafile+"-49")
state_ = sess.run(cell.zero_state(1, tf.float32))
x = np.array([list(map(word_num_map.get, '['))])
[probs_, state_] = sess.run([probs, last_state], feed_dict={input_data: x, initial_state: state_})
word = to_word(probs_)
#word = words[np.argmax(probs_)]
poem = ''
while word != ']':
poem += word
if word == ',' or word=='。':
poem += '\n'
x = np.zeros((1,1))
x[0,0] = word_num_map[word]
[probs_, state_] = sess.run([probs, last_state], feed_dict={input_data: x, initial_state: state_})
word = to_word(probs_)
#word = words[np.argmax(probs_)]
return poem
#-------------------------------生成藏头诗---------------------------------#
def gen_poetry_with_head(head,phase):
global datafile
input_data = tf.placeholder(tf.int32, [1, None])
output_targets = tf.placeholder(tf.int32, [1, None])
def to_word(weights):
t = np.cumsum(weights)
s = np.sum(weights)
sample = int(np.searchsorted(t, np.random.rand(1)*s))
return words[sample]
_, last_state, probs, cell, initial_state = neural_network(input_data)
with tf.Session() as sess:
# sess.run(tf.initialize_all_variables())
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, datafile+"-49")
state_ = sess.run(cell.zero_state(1, tf.float32))
poem = ''
i = 0
p = 0
head=unicode(head,"utf-8");
for word in head:
while True:
if word != ',' and word != '。' and word != ']':
poem += word
p += 1
if p == phase:
p = 0
break
else:
word='['
x = np.array([list(map(word_num_map.get, word))])
[probs_, state_] = sess.run([probs, last_state], feed_dict={input_data: x, initial_state: state_})
word = to_word(probs_)
if i % 2 == 0:
poem += ',\n'
else:
poem += '。\n'
i += 1
return poem
FLAGS = None
datafile='./data/module-49'
def datafile_exist():
return os.path.exists(datafile+"-49.index")
def main(_):
# if FLAGS.train or (not datafile_exist()):
if FLAGS.train:
genTrainData(64)
print("poems: ",len(poetrys))
train_neural_network()
exit()
if datafile_exist():
genTrainData(1)
if FLAGS.generate:
print(gen_poetry())
else:
print(gen_poetry_with_head(FLAGS.head,7))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-a','--head', type=str, default='大寒将至',
help='poetry with appointed head char')
parser.add_argument('-t','--train', action='store_true',default=False,
help='Force do train')
parser.add_argument('-g','--generate', action='store_true',default=False,
help='Force do train')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
使用方法:
-a参数是指定藏头诗开始的字;
-g参数直接自动生成;
-t强制开始训练。(注意训练的时间还是比较长的)
生成的效果请看:
> ./poetry.py -g
沉眉默去迎风雪,
江上才风著故人。
手把柯子不看泪,
笑逢太守也怜君。
秋风不定红钿啭,
茶雪欹眠愁断人。
语苦微成求不死,
醉看花发渐盈衣。
#藏头诗
> ./poetry.py -a "春节快乐"
春奔桃芳水路犹,
节似鸟飞酒绿出。
快龟缕日发春时,
乐见来还日只相。
至少有了个古诗的样子了。
(待续…)
引文及参考
TensorFlow练习3: RNN, Recurrent Neural Networks
TensorFlow练习7: 基于RNN生成古诗词
如何用TensorFlow构建RNN?这里有一份极简的教程
(译)理解 LSTM 网络 (Understanding LSTM Networks by colah)
