从一到万的运维之路
说一说VM/Docker/Kubernetes/ServiceMesh
摘要:本文从单机真机运营的历史讲起,逐步介绍虚拟化、容器化、Docker、Kubernetes、ServiceMesh的发展历程。并重点介绍了容器化阶段之后,各项重点技术的安装、使用、运维知识。可以说一文讲清楚服务器端运维的热点技术。

序
文章的名字起的有点纠结,实际上这是一篇真正从基础开始讲解,并试图串联起来现有一些流行技术的入门文章。
目前的企业级运营市场,很有点早几年前端工程师所面临的那样的窘境。一方面大量令人兴奋的新技术新方案层出不穷;另外一方面运维人员也往往陷入了选择困局,艰于决策也疲惫于跟踪技术的发展。
目前的网络上已经有很多新技术的介绍文章和培训资料——绝大多数讲的比我要好得多。
因为工作原因,我有比较多的用户服务经验。所以我要说的是,写这篇文章的原因,不是因为现有资料不够好。而是这些资料大多都是从技术本身出发,不断的说“我可以提供A、我可以提供B、还有我的特征C也不错”。而忘记了问,用户想要的是什么,用户想解决的问题是什么。
所以不同于通常的技术文章使用技术本身串起来所有的内容,本文试图通过需求和技术的互动发展来串起来运维技术的发展历程。
在整体系统中,开发和运维都是很重要的,所以现在DevOps的理念早已深入人心。但本文并不讲解开发部分的内容,这里只集注在运维架构的演进方面。
即便如此,运维也是非常大的一个话题,所以我的目标再缩小一些,只限定在基础系统软件的领域。
一切都始于单机
最早的时候,一切程序还都很简单,一台电脑已经足够运行。对比起来看,就好像现在单机版的游戏。程序的执行不需要有网络,不需要有服务器,只要保证电脑本身正常,程序就能跑的很好。企业中的运维人员,大多也是会装电脑系统就够。因此往往是由开发人员兼任,完全不用像现在的网管一样睡一觉起来似乎就已经落伍了。
因为信息共享的需求,在一般企业中,最先独立出去的是两种应用:数据库服务器和文件服务器。特点是,工作人员的电脑上,安装软件的客户端。而数据和资源、信息文件,保存在文件服务器上。你肯定看出来了,这既是共享的需求,也是负载均衡的需求。
即便在今天,仍然有很多应用采用这种模式,比如很多的银行、火车站售票窗口、还有常见的一些大规模网游。当然这些系统也沿着不同的道路演进着,比如大多银行仍然喜欢使用大型机系统。这种模式通常称为“客户端-服务器”模式,简称C/S模式。
在这个阶段中,对于一些大型企业和学校,无盘工作站是很流行的一种部署架构。在工作站上有显示器、键盘、CPU、内存,没有硬盘。系统的启动由服务器提供,由客户端网卡完成虚拟硬盘和系统引导的过程。 这样的系统并不完全是为了节省硬盘的费用,在系统的维护上也方便很多,比如杀毒,也只要在服务器的文件区完成杀毒即可。安装软件,在一台工作站安装完,在其它工作站上就可以直接共享使用。
在那个时代,Novell是最风靡的网络系统。当前风靡的Windows Server和Linux在服务器端尚且式微。
由C/S至B/S
在客户端安装一个程序并且保证程序的长期正常运行是挺费劲一个事情。特别是随着Windows系统快速的升级,和客户端可能安装的软件数量增加带来的运行环境复杂性增加,兼容性问题成为另外一个麻烦。
 所以从用户、开发人员到运维人员,都开始将程序从客户端(Client)的方式,转移到了浏览器(Browser)的方式。
所以从用户、开发人员到运维人员,都开始将程序从客户端(Client)的方式,转移到了浏览器(Browser)的方式。
这其实就是我们使用电脑浏览互联网的方式,习惯了手机上网的我们,可能已经忘记了一个域名就卖出天价的时代。
浏览器“开箱即用”的特性很快就风靡业界。Google公司甚至专门为此研发了只支持浏览器环境的Chromebook上网笔记本。在深圳的华强北,大量的轻薄短小的迷你上网本也快速出货。
因为B/S模式的开发需求快速增加,服务器有了内置WEB服务的要求。所以大量的Linux服务器和WindowsNT/200x服务器开始占领市场。
在开发语言上,也在短期内出现了一批适应互联网编程的开发语言或技术,比如LAMP(XAMP)/C#.net+IIS/Java+Tomcat。
虚拟化
很多人认为现代的虚拟化技术起源于早期大型机时代的分时系统或者硬件虚拟化技术。其实严格讲并非如此,上面两项技术只是提供了一个重要的思路,比如资源共享、比如API向上层稳定兼容。从技术的演进上而言,现代所流行的虚拟化技术跟这些技术都没有关系。
现在我们使用的虚拟化技术,主要功能是在一台电脑中模拟出来完整的另外一台或者几台电脑。从而支持另外的、完整的操作系统在其中运行。这另外执行的操作系统,看起来就像是电脑上运行的客户端程序一样的效果。但在其中运行的程序,表现跟运行在独立主机上的程序并无不同。
在CPU厂商尚未给CPU内置虚拟化(比如VT)技术之前,这种模拟器就已经出现了。我所考证最早使用这种方式工作的软件是一款分析、破解应用软件的软件。是一个重要的黑客工具,因此软件的名字在这里不提。这款软件完整的模拟操作系统的执行,在其中运行的应用软件完全意识不到自己是在一个虚拟的环境中执行。在这种状态下,软件的一切动作都可以被跟踪、记录而无所遁形,甚至随时被中断运行切换到代码分析模式,从而快速的被破解。
这种工作方式完整的模拟一切,可以达成工作,但是因为使用了大量的CPU调试中断,软件模拟和监控,导致运行效率非常低。所以在生产环境中并不流行,通常主要用户是开发部门。时至今日,仍然有一些应用采用这种方式工作,比如Android的模拟器,就是基于QEMU的虚拟化技术。不仅可以模拟x86系列CPU,还可以模拟ARM/MIPS等。
直到从CPU硬件层级实现了对虚拟化的支持之后,配合上软件的进步,在虚拟计算机中的程序的运行效率才得到了大幅度提高。在不需要大量显示资源的后端应用中,运行速度已经无限接近实体真机运行同样应用的速度。而这恰恰是服务器端软件所需要的,至此,虚拟化的推广扫清了障碍。
 虚拟化的出现大幅提高了运维效率,也大幅的提高了硬件服务器的利用率,带来了运维的革命性变化。其实就是从这个时期开始,运维部门才逐渐同研发部门互相比肩,脱离了长期从属的尴尬地位。
虚拟化的出现大幅提高了运维效率,也大幅的提高了硬件服务器的利用率,带来了运维的革命性变化。其实就是从这个时期开始,运维部门才逐渐同研发部门互相比肩,脱离了长期从属的尴尬地位。
在这一时代,VMWare几乎一家独大。服务器端采用 VMware ESXi, 客户端使用VMware Workstation。盗版的数量恐怕更是正版采购量的十倍以上。
即便在微服务如此普及的今天,很多企业的基础硬件环境也会首先部署VMware ESXi,再由其中划分所需资源供微服务架构来使用。
尽管如此,在开源软件领域,KVM、OpenStack以及其它类似衍生类应用仍然占领着不大不小但是稳定发展的一块阵地。
原因很简单,虚拟化实际是前几年火热的概念“云服务”的基本基石。为了提供计算资源给客户,云服务厂商基本都需要定制功能、界面给用户完成大量的自主操作。
这些需求,显然是VMWare这样的商业软件难以实现的。因此在开源系统的基础上进行延伸开发就成为了云服务厂商的必由之路。
因此尽管感觉上身边的同事、朋友都在使用VMWare系列产品,但毕竟很多企业已经选择租用云服务器而不建设自己的机房。可想而知,这样的用户数量还是很惊人的。
值得一提的是,原来C/S时代的无盘工作站也与时俱进,以“瘦客户机”的身份在很多企业广泛应用。这时候的瘦客户机,并不一定没有硬盘,重点瘦客户端启动之后就会执行“远程桌面客户端”程序,连接到服务器上虚拟化的桌面系统。从而在表现上如同一个真正的桌面电脑一样完成正式的工作。
运维人员在这种方式下可以节省大量客户端维护的精力。比如某个终端操作系统崩溃,可以简单备份一下数据(数据在服务器上的,甚至无需备份),删除这个客户端,另外从标准模板执行一个实例出来就完成了新系统的部署。这个过程完全不需要离开座位,点击几下鼠标,操作就完成了。
资源复用
原本需要对大量实体服务器进行管理,网管跑机房跑断腿。有了虚拟化之后,运维人员只要坐在电脑前点点鼠标就可以完成工作。配合上远程管理卡(当前的品牌服务器基本已经内置),运维人员已经很少需要进机房了。而且响应速度,比跑机房直接操作实体机快了不知多少。这是上面所说,虚拟化对于运维效率的提升。
更主要的作用,是虚拟化对于服务器资源复用的帮助,这才是用“革命性”一词来形容虚拟化的主要原因。
我们经常见到,很多应用,实际上对CPU/内存等资源的消耗并不大。比如执行WORD编辑文本的时候,CPU占用率往往不超过20%,内存用的更是很少。
对于某些最终客户相关的应用,高峰期和低谷期的设备利用率差别巨大。
因此利用虚拟化技术,在实体机上虚拟多台服务器,分别执行应用,合理调配各应用的高峰和低谷,对于设备利用率的提高作用非常显著。
这一简单的理念贯穿着基础系统软件运维技术演进的全部历史,今天流行的微服务,究其根本,也是在颗粒度上对应用进行了更细致的划分,从而更精确、高效的利用计算资源。
容器(Container)、LXC、Docker
虚拟化的市场巨大,虽然VMWare吃到了最大的一口。但业界的竞争从来没有停止。
很快容器技术就脱颖而出,成为业界新宠。成功的原因是多方面的,但最硬核的一条,是对系统运行效率的提升。
 在上一章我们说过,虚拟化会在一台电脑上,虚拟出1台或多台电脑,运行另外的操作系统。比如执行了2台Windows,1台Ubuntu,1台Centos。随后在这些操作系统上,再执行具体的应用。
在上一章我们说过,虚拟化会在一台电脑上,虚拟出1台或多台电脑,运行另外的操作系统。比如执行了2台Windows,1台Ubuntu,1台Centos。随后在这些操作系统上,再执行具体的应用。
应用在执行的过程中,大量的硬件调用通过虚拟主机的操作系统,被虚拟化系统比如VMWare所截获,再转换到实体主机的硬件层执行。这个过程已经成为执行效率进一步提升的瓶颈。
而对于大多数应用来说,其规模远远小于操作系统本身,往往是为了执行一个只有几十M容量的应用,首先要部署一个上G容量的操作系统。系统启动过程所耗费的时间也是远超应用本身。这种情况下,虚拟化对于计算资源的消耗更是变得尤为突出。
容器则是使用了完全不同的思路,在容器中,每个应用都共享了实体主机的操作系统本身。只是利用内核提供的隔离技术,完全无法发现其它应用的存在,同样实现了“独占”的效果。
在容器中执行的应用,所有操作实际上并不是被虚拟化的,跟直接在实体机上的执行从效率上说没有区别。
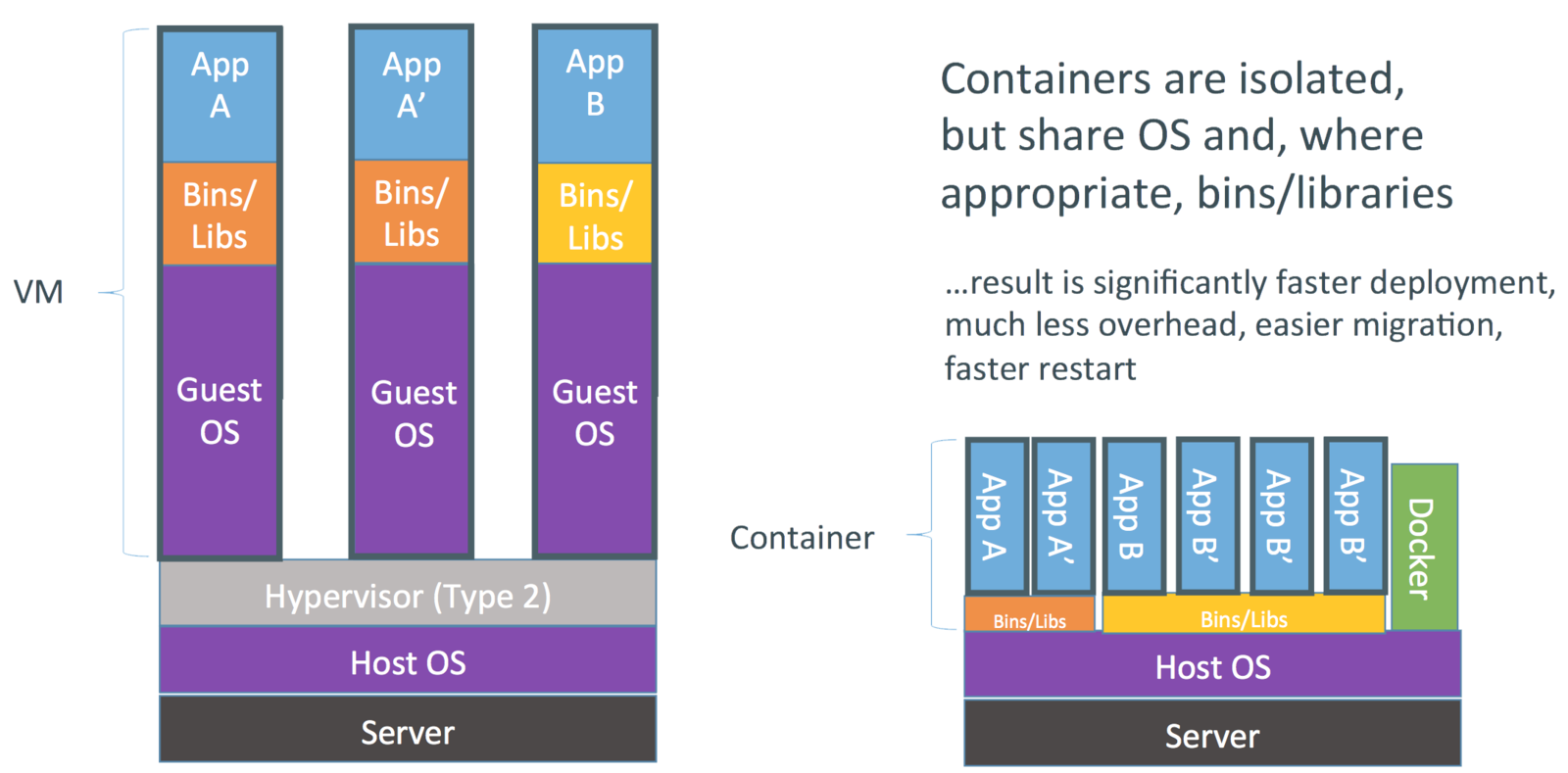 容器技术的缺点也是明显的,就是容器无法支持实体主机上的多种操作系统,容器中的操作系统,跟宿主机上的操作系统必须是一致的。
容器技术的缺点也是明显的,就是容器无法支持实体主机上的多种操作系统,容器中的操作系统,跟宿主机上的操作系统必须是一致的。
比如在Ubuntu主机上的容器中,可能出现Centos/Ubuntu,但不可能出现Windows容器。
容器技术发展迅猛,即便系统软件巨头微软也无法忽略,传闻微软在Windows的容器化上投入了巨大的资源,但截至今日,尚未有说服力的产品出现。
因此实际上我们提起来容器,在今天说就是Linux容器(LXC)。
Linux容器的雏形是于1979就出现了的chroot,相信很多Unix类用户都用过。执行chroot之后,用户的环境会切换到指定目录的架构环境之中,只有内核跟宿主机共用,通常是用于解决大量的版本库兼容性上的问题。
chroot现在也有一个很流行的典型应用可能你知道,就是Android手机上的Linux For Android。众所周知的,Android系统使用的内核就是Linux,而Linux For Andoird实际上就是首先构建一个完整的Linux文件系统,mount到指定的目录,然后用chroot将系统切换到这个目录,从而在手机上得到了完整的Linux功能。
2006年,Google工程师Paul Menage和Rohit Seth提出了用于进程间隔离的Process Container技术,并在Linux内核中实现,就此奠定了当前Linux容器技术的基础。次年,为了避免用词上的误解,更名为Control Groups,简称cgroups。
当今Linux容器系统层出不穷、百团大战的盛况,基本都是基于这些技术。因为主要技术难题在内核端已经解决,大大的降低了实现门槛,所以当前多种容器技术的比拼,都是在易用性、自动化和持续集成、以及已经容器化的资源数量上做文章。
在这些竞品中,Docker是应用最为广泛的一个,应当算是事实上的工业标准。后续很多流行的容器技术,往往是基于Docker的进一步创新。
Docker的安装
从本小节开始,会介绍一些安装、使用的具体知识,但本文主要目的仍然是串起来运维的知识体系。所以详细的内容,建议到本文提供的链接或者参考资料中继续学习。
Docker官网地址:https://www.docker.com
Docker最初只有一个开源免费的版本,现在Docker已经分为社区版(CE)和企业版(EE),后者功能更强,但是收费的版本。通常没有特殊需求的情况下,使用社区版本已经足够了。
如果只是想简单学习、实验,或者基于Docker的开发、测试,Docker还提供有一个桌面版。可以根据自己操作系统不同,在这里选择下载:https://www.docker.com/products/docker-desktop,下载需要提前在网站注册用户。
桌面版在Mac或者Windows的执行,实际上也是使用虚拟化的方法,首先运行一个Linux的虚拟机,然后在虚拟机中使用Docker的容器功能。并且有Mac/Windows的命令行程序配合Docker的操作。原因前面已经说了,目前来讲,容器技术还只能在Linux中使用。
Docker的生产环境,当然就只能选择Linux系统。通常如果是研发人员主导的项目,较多会选用Ubuntu系统。因为Ubuntu系统默认配置客户端工具丰富,桌面绚丽多彩,好看又好用。各组件的升级包发布非常快,能够快速接触新的技术和解决存在的Bug。不过对于运维来讲,快速发布的补丁包实际上代理了额外的工作量,所以在此建议使用Ubuntu系统作为生产环境的话,一定要使用长期支持的LTS版本。
如果是运维人员主导的项目,大多还是会选择Centos。Centos相当于RedHat的社区免费版本。系统稳定可靠,较少的默认工具也让系统占用较少的资源。对于系统各组件来讲,Centos更新会比较慢,每次的更新也会经历认真、全面的测试,适合于生产环境的稳定、安全需求。
除此之外,因为容器主机对主机本身并没有多少操作的需求和工具的要求,所以现在还有很多极简定制版本的Linux用于Docker的容器主机,比如CoreOS,以及各大IT厂商自己定制的版本。在这些系统中,大多都已经预置了Docker系统,基础Linux环境往往只有几十M的容量;使用BusyBox替代大量的Linux基础命令库;只保留必要的管理工具和Docker启动所使用的基本依赖库。从而把宝贵的内存和硬盘留给容器使用。这种方式很类似于VMware ESXi所使用的方式,可见,各技术之间也在互相的学习和互相的启发。
Ubuntu和Centos虽然没有默认安装Docker,但新本版的系统,比如Ubuntu14.04、Centos7之后,在软件仓库中都已经有了Docker的安装包。简单几行命令就能完成Docker的安装配置。
Centos之下安装Docker:
//更新软件源的索引
sudo yum update
//安装Docker
sudo yum install docker
//启动Docker服务
sudo systemctl start docker
Ubuntu下面安装Docker:
//更新软件源
sudo apt update
//安装Docker
sudo apt install docker.io
这种情况下安装的Docker一般都不是最新的版本,但通常都是够用的。所以如果没有特殊的需求,我建议直接这样安装、使用就好。
如果希望安装最新的版本,可以添加Docker官方源,然后安装最新的CE版本。这方面请参考官方文档:https://docs.docker.com/install/overview/。官方文档中,左侧的目录里,有针对不同操作系统的安装方法,请自行学习。
对于大多数应用,我非常建议的学习方式是以阅读官方的文档为主。如果因为英语水平问题希望阅读中文资料,也尽量同官方文档对照着看。因为软件版本更新快速和翻译中的错误问题,仅仅阅读中文翻译文档往往会有一些让你费解的问题存在。
Docker典型使用
完整的学习Docker建议参考官方文档:https://docs.docker.com/get-started/
文档写的非常棒,图文并茂,清晰易懂。下面只对典型的应用场景做一个串讲。
首先是基本概念:
Container: 容器,相当于一台虚机,可能正在执行,也可能执行结束已经退出(关机)。
Image: 映像。这个是新手容易困惑的。因为在VMWare中没有这个概念,比较接近的,可以理解为已经安装好的操作系统模板,每次启动一个容器(虚机),实际是复制一份映像,然后在映像上执行。前面已经说过,容器本质上是跟宿主机共享内核,映像则相当于硬盘的文件系统,当然是建立在某目录下的根文件系统,只是文件本身,并不是磁盘的克隆。
Docker: Docker是这套容器系统的产品名称,也是命令行管理工具的名称(命令行工具要使用全小写字符)。所有对Docker系统的操作,都可以通过命令行完成。直接执行docker,可以得到概要帮助文档。
(本文的代码块中,命令前面的#符号是系统root状态的提示符,不需要用户输入)
# docker
Usage: docker [OPTIONS] COMMAND
A self-sufficient runtime for containers
Options:
--config string Location of client config files (default "/Users/andrew/.docker")
-D, --debug Enable debug mode
-H, --host list Daemon socket(s) to connect to
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
--tls Use TLS; implied by --tlsverify
--tlscacert string Trust certs signed only by this CA (default "/Users/andrew/.docker/ca.pem")
--tlscert string Path to TLS certificate file (default "/Users/andrew/.docker/cert.pem")
--tlskey string Path to TLS key file (default "/Users/andrew/.docker/key.pem")
--tlsverify Use TLS and verify the remote
-v, --version Print version information and quit
Management Commands:
builder Manage builds
checkpoint Manage checkpoints
config Manage Docker configs
container Manage containers
image Manage images
manifest Manage Docker image manifests and manifest lists
network Manage networks
node Manage Swarm nodes
plugin Manage plugins
secret Manage Docker secrets
service Manage services
stack Manage Docker stacks
swarm Manage Swarm
system Manage Docker
trust Manage trust on Docker images
volume Manage volumes
Commands:
attach Attach local standard input, output, and error streams to a running container
build Build an image from a Dockerfile
commit Create a new image from a container's changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
deploy Deploy a new stack or update an existing stack
diff Inspect changes to files or directories on a container's filesystem
events Get real time events from the server
exec Run a command in a running container
export Export a container's filesystem as a tar archive
history Show the history of an image
images List images
import Import the contents from a tarball to create a filesystem image
info Display system-wide information
inspect Return low-level information on Docker objects
kill Kill one or more running containers
load Load an image from a tar archive or STDIN
login Log in to a Docker registry
logout Log out from a Docker registry
logs Fetch the logs of a container
pause Pause all processes within one or more containers
port List port mappings or a specific mapping for the container
ps List containers
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rename Rename a container
restart Restart one or more containers
rm Remove one or more containers
rmi Remove one or more images
run Run a command in a new container
save Save one or more images to a tar archive (streamed to STDOUT by default)
search Search the Docker Hub for images
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop one or more running containers
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
top Display the running processes of a container
unpause Unpause all processes within one or more containers
update Update configuration of one or more containers
version Show the Docker version information
wait Block until one or more containers stop, then print their exit codes
Run 'docker COMMAND --help' for more information on a command.
需要注意的是,因为容器的特征,Docker大多数用法都需要在Linux的root权限下执行,所以请提前使用sudo su进入到root状态。Windows/Mac的桌面版因为实际使用的是虚机执行,当前本机的Windows/Mac只是一个显示终端,所以不需要。像上面一样只显示帮助文档,是少数几个不需要root权限执行的用法之一。
命令行管理工具虽然是所有docker功能的执行起点,但docker本身实际是一个后台的服务。这个服务可以运行在任意电脑上。只要docker命令行管理工具配置后能够同后端服务连接、通讯就可以完成管理工作。这也是Mac/Windows版本的Docker桌面版本管理工具的运行模式,后端服务运行于虚机中的Linux中,真正在Mac/Windows操作系统执行的是这个命令行管理工具。
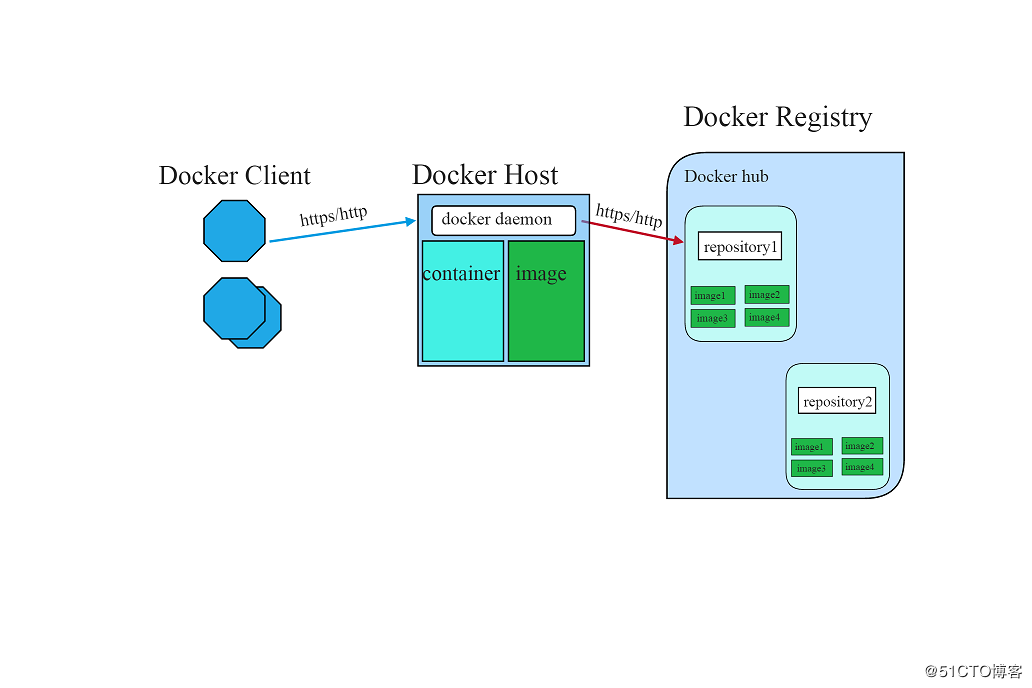
执行一个容器,当然是从准备容器的映像文件开始。映像文件或者自己制作(相当于在VMWare在虚机中安装操作系统),或者使用别人制作完成的。Docker提供了制作工具,我们后面再讲。
获取别人制作的映像文件通常两个办法:一是从映像仓库直接下载;二是导入他人导出的映像文件包。
比如我们想运行一个Ubuntu容器,首先在官方的容器仓库搜索:
# docker search ubuntu
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
ubuntu Ubuntu is a Debian-based Linux operating sys… 9298 [OK]
dorowu/ubuntu-desktop-lxde-vnc Docker image to provide HTML5 VNC interface … 279 [OK]
rastasheep/ubuntu-sshd Dockerized SSH service, built on top of offi… 205 [OK]
consol/ubuntu-xfce-vnc Ubuntu container with "headless" VNC session… 158 [OK]
ansible/ubuntu14.04-ansible Ubuntu 14.04 LTS with ansible 96 [OK]
ubuntu-upstart Upstart is an event-based replacement for th… 96 [OK]
neurodebian NeuroDebian provides neuroscience research s… 56 [OK]
1and1internet/ubuntu-16-nginx-php-phpmyadmin-mysql-5 ubuntu-16-nginx-php-phpmyadmin-mysql-5 49 [OK]
ubuntu-debootstrap debootstrap --variant=minbase --components=m… 40 [OK]
nuagebec/ubuntu Simple always updated Ubuntu docker images w… 23 [OK]
tutum/ubuntu Simple Ubuntu docker images with SSH access 19
i386/ubuntu Ubuntu is a Debian-based Linux operating sys… 16
1and1internet/ubuntu-16-apache-php-7.0 ubuntu-16-apache-php-7.0 13 [OK]
ppc64le/ubuntu Ubuntu is a Debian-based Linux operating sys… 12
eclipse/ubuntu_jdk8 Ubuntu, JDK8, Maven 3, git, curl, nmap, mc, … 8 [OK]
codenvy/ubuntu_jdk8 Ubuntu, JDK8, Maven 3, git, curl, nmap, mc, … 5 [OK]
darksheer/ubuntu Base Ubuntu Image -- Updated hourly 5 [OK]
pivotaldata/ubuntu A quick freshening-up of the base Ubuntu doc… 2
1and1internet/ubuntu-16-sshd ubuntu-16-sshd 1 [OK]
paasmule/bosh-tools-ubuntu Ubuntu based bosh-cli 1 [OK]
smartentry/ubuntu ubuntu with smartentry 1 [OK]
ossobv/ubuntu Custom ubuntu image from scratch (based on o… 0
1and1internet/ubuntu-16-healthcheck ubuntu-16-healthcheck 0 [OK]
pivotaldata/ubuntu-gpdb-dev Ubuntu images for GPDB development 0
1and1internet/ubuntu-16-rspec ubuntu-16-rspec 0 [OK]
Docker默认的仓库是官方的Docker Hub,包含了大量的官方映像和社区贡献的映像。出于安全和稳定性方面的原因,再加上访问国外网站的速度问题,通常稍有规模的公司都会建立自己的映像仓库,这方面的内容请参考官方文档。
上面的命令执行后,可以搜索到大量的Ubuntu相关映像。如果你已经知道你需要使用哪一个,比如相关文档中已经说明了,可以直接使用。如果不了解,可以按照这样的原则来选择:
- 尽可能选择官方出品的,也就是OFFICIAL一栏标注了OK的。
- 选择推荐度比较高的,也就是STARS的值比较高的。
- 在名称和描述中查看符合自己需要的特征。比如我经常给开发人员推荐dorowu/ubuntu-desktop-lxde-vnc,这个是内置了桌面图形界面环境的一个Ubuntu影响,不仅可以使用VNC客户端直接访问,还内置了一套web版本的vnc客户端。直接使用浏览器访问就能得到一个全功能的桌面Ubuntu环境。
假设我们希望使用第一个官方出牌,推荐度最高的映像,可以使用下面命令将映像从官方仓库下载到本地电脑:
# docker pull ubuntu
Using default tag: latest
latest: Pulling from library/ubuntu
6cf436f81810: Pull complete
987088a85b96: Pull complete
b4624b3efe06: Pull complete
d42beb8ded59: Pull complete
Digest: sha256:7a47ccc3bbe8a451b500d2b53104868b46d60ee8f5b35a24b41a86077c650210
Status: Downloaded newer image for ubuntu:latest
pull是docker命令的子命令,表示从仓库中下拉映像,后面的ubuntu是搜索到的映像名称。
映像的下载时间依赖网络速度,通常都非常快,主要原因是容器的映像,远远小于VMWare的虚机容量。比如这个Ubuntu的映像,通常是88M左右(因版本变化会有不同)。Docker的映像文件是分层增量存储的,所以在上面的下载过程中,能看到多个独立的下载进度。
现在流行的微服务概念,是从研发端架构设计开始就遵循的一系列方法的统称。“微”这个字在其中有很多含义。但大多资料做概念解释的时候,都忽略了容器虚拟化本身的“微”。其实稍微多了解一点就会知道,如果没有容器本身的轻量、高效,很多后续的手段根本就用不上。
映像包下载完成后,可以使用下面命令列表显示:
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/ubuntu latest 47b19964fb50 4 weeks ago 88.1MB
这表示我们本地有了一个映像,名称为“ubuntu”。
本地的映像文件,可以使用save子命令保存为一个tar文件,用于备份或者提供给其他网络不方便的用户使用:
# docker save ubuntu -o ~/Downloads/docker.ubuntu.tar
load子命令可以将一个docker存储的tar文件载入到本地的映像仓库,如果本地仓库中已经有了同名的映像文件,则仓库中的映像文件会被覆盖:
# docker load -i ~/Downloads/docker.ubuntu.tar
这也是刚才提到的,第二种获取映像文件的方法。因为国内的网络情况,很多国外的映像资源,无法直接使用pull子命令获取。往往需要别人帮助,然后load到本地映像仓库。
有了映像文件,可以使用下面的命令启动一个容器,也就是相当于VMWare中的启动一个虚机:
# docker run -it ubuntu /bin/bash
root@519279bc7105:/#
run是docker的另外一个子命令,表示执行一个容器映像。-it是命令行参数,表示分配一个终端用互动的方式执行。docker run --help可以更详细的显示有关run子命令的文档。接下来的ubuntu就是刚才下载的映像文件名称。
最后的“/bin/bash”是容器启动后,在给定的根文件系统中,执行的程序入口。这个可能会让VMWare用户费解,原因依旧是VMWare中没有这个概念,VMWare虚机启动时候当然是如同一台真正的电脑一样从头开始启动一个操作系统。
而Docker容器我们刚才说了,实际上是跟宿主机共享内核,然后部署一个完整的根文件系统,这个环境实际上是静态的。只有在这个环境中真正运行起来一个程序,才代表了容器的运行。上例中,/bin/bash这个外壳交互程序,就是作为了我们这个容器的执行入口。
这时候如果另外开一个命令行窗口,执行容器列表子命令ps,可以观察到ubuntu映像的执行:
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abae98b3ba33 ubuntu "/bin/bash" 11 seconds ago Up 10 seconds inspiring_lalande
在ubuntu的执行窗口,你可以试着做一些操作。如果对Ubuntu足够熟悉的话,你会发现,这是一个高度精简的Ubuntu系统,通常称为Ubuntu core,提供用户在其上部署自己的应用。这是微服务系统的一个重要理念–每个微服务的设计中,尽力只包含最必须的那些文件系统和库。从而节省空间、提高效率、更提高了安全性和稳定性。我见过几个印象深刻的系统,其中连bash外壳程序都没有,即便程序中有未测出的漏洞被黑客利用,因为缺乏大量基本必须的系统操作工具,配合上只读的文件系统,黑客什么也做不了。
在容器内的操作完成后,ctrl+d或者exit可以退出容器的bash环境,回到宿主机的命令行。
这时候再次查看容器列表,你会发现刚才的容器已经消失了:
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
这是因为,默认情况下,ps子命令只列出正在运行中的容器。增加-a参数可以列出所有的容器,包括已经执行结束退出的:
#docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abae98b3ba33 ubuntu "/bin/bash" 8 minutes ago Exited (0) 14 seconds ago inspiring_lalande
这是容器的另外一个重要特征,当指定的程序运行结束后,退出了程序,也就代表了容器的关闭,或者说停止运行。这在VMWare虚机中同样没有相同概念,传统的虚机即便退出了应用程序,除非显式的关机了,否则操作系统还维持着虚机的继续运行。
至此我们完成了一个容器的完整执行流程,对比传统的虚机系统,你可能首先的感觉就是“快”。容器的启动速度快、退出速度更快。现在微服务系统的大规模集群、接近实时的动态部署调整规模等特性都得益于于容器的这种特征。在传统的虚机环境中,这是不可想象的。
重新启动一个已经退出的容器使用start子命令:
# docker start abae98b3ba33
abae98b3ba33
#
参数abae98b3ba33是刚才ps子命令列表中所得到的容器的ID号,这个ID号伴随一个容器的生命期都不会改变。在docker命令行中使用ID号的时候,实际上只需要输入头几位、跟其它ID不会混淆就可以执行。
start子命令执行后,首先返回一个ID号,然后又回到了命令行提示符。这是因为这个镜像是在系统后台执行的。
使用ps子命令查看:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abae98b3ba33 ubuntu "/bin/bash" About an hour ago Up About a minute inspiring_lalande
可以看到容器已经在后台执行了。实际上这才是容器通常的状态,我们刚才使用-it运行bash外壳来执行一个容器,只是为了让你看起来更直观。正常的应用,比如一个web服务器,执行一个命令行外壳出来是没有意义的。
如果想回到容器的命令行,来观察应用的运行状态,这通常是用于调试。可以使用attach子命令:
# docker attach abae
root@abae98b3ba33:/#
注意这次参数使用了容器ID的简写形式:abae。
你肯定注意到了,从容器的bash使用ctrl-d或者exit退出后,容器再次退出了。原因是attach子命令实际上是附着到容器的执行进程上去了,跟我们开始使用-it执行bash是完全相同的。
这显然不适合出于调试目的进入容器的操作。况且,一个容器启动的时候,执行的往往也不是bash外壳程序,而是应用的启动程序。attach到应用的启动程序,往往也达不到调试的目的。
在这种情况下,使用exec子命令,另外执行一个shell才是合理的选择:
(代码块中的//符号是注释的意思,该行信息并不需要输入,也不是系统给出的提示信息)
//当然首先还是要把停止的容器启动起来,不然exec子命令是无法执行的
# docker start abae
//因为通常/bin目录都在PATH环境变量中,所以实际上只执行bash就等于执行了/bin/bash
# docker exec -it abae bash
root@abae98b3ba33:/#
这一次,如果你退出了容器的bash,你会发现,容器还正常的在后台运行着:
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abae98b3ba33 ubuntu "/bin/bash" About an hour ago Up 29 seconds
其它几个经常会用到的容器执行方式:
//运行一个ngnix容器,并命名为mynginx
//下次对容器的操作,可以直接使用命名,而不是容器ID,这非常适合写持续集成的批处理
// -d是生产中经常会用到的在后台执行容器,不做互动也不分配终端
# docker run --name mynginx -d nginx
//将容器的80端口映射到宿主机8080端口
//docker有完整的网络组件,可以为容器分配网络地址,请查看相关资料
//但根本上,直接使用宿主机IP,在其中开服务端口才是最高效的方式
# docker run -p 8080:80 -d nginx
//如果宿主机有多个网址,还可以指定端口绑定的IP地址
# docker run -p 211.100.132.14:8080:80 -d nginx
//除了映射端口,另外映射宿主机的/webdata文件夹到容器的/var/www/html文件夹
//作为可负载均衡的集群,文件的持久化及共享,通常都使用宿主机的文件夹映射到容器来完成
# docker run -p 8080:80 -v /webdata:/var/www/html -d nginx
//在前面的基础上,指定容器的重启策略为永远
//这个可以保证当容器意外退出甚至宿主机重启后,容器也会被重启起来
# docker run -p 8080:80 -v /webdata:/var/www/html -d --restart=always nginx
当一个容器确定不再需要后,可以使用rm子命令删除,注意如果容器中还有运行所产生的数据,这些数据也会删除,这跟传统虚机是一致的:
//首先要使用stop停止容器的运行,在执行中的容器是不能被删除的
# docker stop abae
abae //这是docker命令执行后的回显
//删除容器及其数据
# docker rm abae
abae
#
映像文件不再使用后,同样也可以删除。注意如果有容器正在使用的映像,是不可以被删除的,这种情况需要停止所有使用到该映像的容器,并删除容器之后,才可以删除映像文件:
docker rmi ubuntu
自己制作容器映像
不同于传统虚机从光盘启动系统开始一个操作系统的安装,当然我们也已经知道了那是很浪费资源而并无意义的一件事情。
容器没有操作系统的启动过程,因此传统的系统部署手段都是不能使用的。所以通常上,容器映像的建立,都是基于某个已有的系统。同样的,我们建立的映像,也可能成为别人,或者我们自己,将来建立映像时候的基础。所以前面所讲Docker映像文件,采用分层增量的组织方式,的确是非常合理的。
如果对于裁剪Linux经验还不足,我很建议你从最常用的centos或者ubuntu映像为基础开始安装自己的应用。
建立映像文件规范的方法是使用docker的build子命令,将编写的Dockerfile建立成映像文件。Dockerfile的内容相当于一组脚本命令。为了描述原理,我们先从更底层的笨办法开始。
因为我们已经下载了ubuntu的映像,所以我们以ubuntu为例来看一个映像的建立过程。
首先是执行一个ubuntu的容器,这个上一小节就见过了:
# docker run -it ubuntu bash
root@bded292dfa72:/#
随后出现了ubuntu容器的提示符,我们接下来的操作都在容器的bash外壳中执行。
//更新软件源
apt update
apt dist-upgrade -y
//安装nodejs和包管理器,nodejs是npm的依赖项,会自动被安装
//另外安装一个vim编辑器,方便编辑测试程序
apt install npm vim
//转换到工作目录
cd /opt
//编辑nodejs的测试程序
vi server.js
测试程序输入以下内容,输入完成后使用:x保存退出:
#!/usr/bin/env node
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World<br>Here is NodeJs in Docker<br>\n');
}).listen(8080, '0.0.0.0');
console.log('Server running at http://127.0.0.1:8080/');
继续后续操作:
//将nodejs程序设置为可执行
chmod +x server.js
至此测试映像所需的安装工作已经完成,可以exit退出容器的bash,同时容器也会停止执行。
接着可以使用commit子命令将一个容器的当前状态,在本地映像仓库保存为一个映像:
# docker commit -m "a nodejs helloworld" --author="andrew" bded292dfa72 nodejshello
sha256:5b486e5ec498739c8c35c36a1c47bab19ca2622846de12ae626cf8a4fc4376bc
#
-m参数之后为映像文件的提交信息,可以理解为映像文件的描述信息;–author是映像的作者信息;接着是容器ID;最后是保存的新映像的名字,注意必须使用小写字母。
commit子命令的执行需要一点时间,这取决于映像的大小,执行完成后会返回映像的sha256哈希值。
此时查看映像列表,可以看到多了一个映像,也就是我们新建的nodejshello:
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nodejshello latest 5b486e5ec498 57 seconds ago 473 MB
docker.io/ubuntu latest 94e814e2efa8 7 hours ago 88.9 MB
我们来执行、测试一下新建立的映像:
# docker run -p 8080:8080 -d --restart=always nodejshello /opt/server.js
e64622cde5124e3fcd70e74a3d687e32f347dfc12f13a55b1f593ee2e7fe4553
容器的启动速度非常快,马上你就可以看到返回的一个hash值,也就是容器的ID。
此时查看容器列表,能看到已经执行的容器,显示的信息中还有端口的映像信息:
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e64622cde512 nodejshello "/opt/server.js" 7 seconds ago Up 6 seconds 0.0.0.0:8080->8080/tcp wizardly_aryabhata
使用curl命令来查看一下执行结果:
# curl 127.0.0.1:8080
Hello World<br>Here is NodeJs in Docker<br>
#
可见,server.js已经正常执行了。
以上是手工建立Docker映像文件的方法。使用build子命令自动化建立映像文件,建议参考一下官方的文档:
https://docs.docker.com/engine/reference/builder/
我们仿照手工建立映像的例子,只展示一个简单的Dockerfile构建映像的过程。
首先需要做一个准备工作。Dockerfile是一个自动化的执行文件,肯定无法像上面一样手工编辑程序。所以这个程序我们需要提前编辑好,方便起见,还要提前放到我们的内部文件服务器上。比如我们最终放置的地址是:http://192.168.1.100/share/nodejs/server.js。
在生产环境中,较多应用是放置在git仓库中,开发团队将代码提交到git仓库;运维人员在Docker映像构建时从仓库中拉出来编译、部署。中间当然还有测试人员的测试过程,这个是由企业的开发流程决定的,此处不谈。
请看我们编写的Dockerfile:
FROM ubuntu
RUN apt update
RUN apt dist-upgrade -y
RUN apt install -y npm wget
WORKDIR /opt
RUN wget http://192.168.1.100/share/nodejs/server.js
RUN chmod +x server.js
EXPOSE 8080
ENTRYPOINT ["/opt/server.js"]
Dockerfile的内容,按照英文字面意思解释应当都可以理解。其中最后一行ENTRYPOINT,我们指定了映像文件的执行入口,这样我们将来执行这个映像的时候,就可以不需要显式的使用run参数给出了。
将Dockerfile保存到一个工作目录,然后在该目录中执行建立映像的命令:
# docker build -t test/hello:v1 .
参数-t之后是将要生成的映像名称,这次我们使用了一个完整的名称,test是仓库名称(可以当做本地的分类名称),斜线之后的hello是映像名称,冒号之后则是版本号,这些必须都是小写。其实只使用一个简写的名称hello,只要没有重名也是可以的。在一个大系统中,规范的命名习惯当然是必要的。最后的参数“.”以当前目录的Dockerfile为模板来生成映像文件。
映像生成的过程视网速不同通常需要执行一定时间,这个过程屏幕的输出能看到,这跟我们刚才手工建立映像文件的过程是完全相同的。
一直到最后几行,会显示类似这样的内容:
...
Step 9/9 : ENTRYPOINT /opt/server.js
---> Running in c10d3d6599dd
---> 74afed533165
Removing intermediate container c10d3d6599dd
Successfully built 74afed533165
大意是,一共9个步骤都执行完成。映像提交到本地仓库后,删除了用于生成映像的临时容器c10d3d6599dd。生成的容器ID是74afed533165。
查看当前的容器列表:
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
test/hello v1 74afed533165 3 minutes ago 426 MB
nodejshello latest 5b486e5ec498 44 minutes ago 473 MB
docker.io/ubuntu latest 94e814e2efa8 8 hours ago 88.9 MB
新生成的映像文件已经存在了,执行容器做一个测试:
// 后台执行容器
# docker run -p 8080:8080 -d test/hello:v1
// 测试服务
# curl http://127.0.0.1:8080
Hello World<br>Here is NodeJs in Docker<br>
#
结果说明,我们制作的映像已经成功执行了。
Dockerfile的编写简单易用,能够将部署和发布流程固化下来,非常方便在devOps和持续集成项目中应用。但也有一些小缺点,一是脚本本身的调试并不算非常方便,通常之前都要手工先仔细验证才能编写到Dockerfile;另外仍然跟我们的网络环境有关,大量的环境安装依赖国外的软件仓库,经常碰到网络超时或者临时性网络故障导致映像构建失败的情况。
通常大一些的公司都会在境外租用服务器,把映像的构建工作在国外完成,随后再下载到本地使用;或者使用Docker Hub配合github的自动构建功能在云端完成构建过程。这个超出本文的范围,请在有需求的时候在网上搜索相关介绍资料。
Docker是一个功能丰富的容器系统,这里只介绍了最常用的部分。应用场景比较复杂的用户建议尽早阅读官方文档,深入了解Docker的使用。
容器编排和管理
Docker的命令行方式当然很方便自动化运维,但对普通用户讲并不友好。
此外当Docker宿主机多起来的时候,管理起来显然很不方便。
还有就是随着微服务理念的大量应用,Docker基本系统对于批量的启动容器、负载均衡、健康检查、服务发现都非常无力。
这些问题在运维的历史上其实都有对应的解决方案的。比如负载均衡可以用Nginx代理、HaProxy甚至硬件的负载均衡器。
从一台主机出发,对所有的宿主机集中管理也可以采用常用的“堡垒机”方式配合大量脚本。
但这些方案看上去都很有“补丁”的感觉,用起来并不方便,更不友好。
所以一时间,大量基于Docker容器的管理系统层出不穷。当然这也有内核解决了主要的关键技术问题,使得开发门槛较低的因素。
这些系统集中解决了多宿主机集群情况下的统一管理和容器动态编排方面的问题。因为Linux本身就是开源软件,这些系统大量的采用了开源软件资源,加上自主开发的部分代码。所以实际上看起来很多部分都是雷同或者类似的。
从软件工程的角度来看,VMWare模式是典型的“教堂模式”,容器当然就是“集市”模式。如果说Linux作为集市模式的代表,其领导地位还存在争议的话。在虚拟化平台的生产应用方面,“集市”模式已经显著领先了。
经过了2年左右的竞争、淘汰,已经有很多平台人气不在了,国内我也知道几家创业公司悄然倒闭。对用户来讲,最可惜的是付出的学习成本。

当前用户比较多的系统中,比较有名的是Rancher、Kubernetes、Swarm。
Swarm是Docker官方推出,可惜推出的比较晚,很多用户已经有了自己的选择,不愿意付出迁移的成本。否则本来Swarm是最有机会一统天下的。
Kubernetes今天看起来似乎已经成为了业界领袖,占有最多的用户群。毕竟Google这么多年最大规模的服务器集群运营经验不可小视。所以接下来我们就看看Kubernetes的解决方案。
Kubernetes的基本概念
Kubernetes(以下简称k8s)已经开始了文档的中文化工作,截至本文成稿的时间,大多数基本的文档都已经有了对应的中文版。并且得益于容器技术的成熟和辅助工具的完善,新版本的安装、使用也更容易。
官方文档位于:https://kubernetes.io/zh/docs/ 建议及早阅读。
本文还是立足串讲最常用的使用场景和相关知识。这部分的概念介绍比起Docker来要多了很多。并且没有采用通常的技术文章使用的分类办法,很多相邻概念也并不是同一个层次。但原则上,是需要使用者了解和操作的会多介绍。虽然可能很重要,但通常用户日常根本用不到的,就少介绍或者不介绍。
额外再强调一下前面说过的,k8s同其它很多容器管理平台类似,都大量的采用了社区贡献的成熟组件。Google自主开发的部分所占比例并不大。从这个角度上说,学习一种新的容器管理平台并不会有很多瓶颈,因为很可能大多数功能、用法,你都已经接触过了,并不陌生。
k8s运行的硬件环境:
Linux类操作系统。2G以上内存;主节点需要至少2个CPU。集群内的机器必须有完全的网络链接。如果使用k8s的辅助工具协助安装,建议是Debian/Ubuntu或者Redhat/Centos服务器,以便使用APT或者YUM工具。
k8s需要至少一台主节点(master),用于进行集群管理。k8s支持高可用模式,这种方式可以支持多台服务器共同做master节点。
经过设置,k8s可以只有一台服务器,同时做主节点和工作节点,通常是用于学习和测试。但默认设置工作节点是需要其它的服务器。
k8s的组成比较复杂,如果在虚拟化的初期,用户维护这样一个系统恐怕需要一个小团队。现在官方把所有组件都合理打包成了几个Docker映像文件。部署k8s系统实际就是下载和启动相应的Docker容器。即便这样,手工安装依然有不小的工作量。很幸运官方又推出了专门的集群管理工具:kubeadm,这个命令行工具进一步简化了k8s部署的工作。当前如果在已有的Linux服务器上部署一套k8s只要一名工程师不超过10分钟的操作。
kubeadm帮助集群管理员简化集群的安装、维护工作。对于k8s容器的用户,则是使用kubectl。这同样是一个命令行工具,帮助容器用户完成几乎所有容器相关的操作。这样分别的提供管理工具,也有利于企业在运维层面更精细的权限管控。
还有一个模块是我们在集群搭建的时候会安装的kubelet,这个应用通常不需要k8s用户自己直接执行。这相当于一个后台服务,运行在所有k8s节点上,进行底层的通讯和根据通讯对所在的节点进行所需操作。
除了这三个组件,还需要手工安装的是网络插件。这个网络不是Linux本身已经包含的网络支持。这里指的是容器之间为了通讯而需要的虚拟网络设备。我们前面一再提到过,容器技术实际上基于chroot和cgroups。这些技术其实并不包含网络。早期的Docker本身的确也并不提供网络支持。你可以想象原本运行在一台电脑上的两个程序,有大把的手段进行数据共享。而现在隔离成了两台虚拟电脑上运行的两个独立程序,网络交互就是必须品了。
随后因为需求一直都在,大量支持容器的网络功能包出现。这样多不同团队开发的网络包组件,完成的都是同样的功能,各自有自己的粉丝群体。所以现在k8s允许用户自行选择喜欢的网络插件,以提供容器间的网络通讯。
你可以理解为,有了网络插件,容器虚机中才能有自己独立的ip地址,才能进行虚拟服务器之间的数据交换。k8s支持的网络插件列表可以在这里找到:https://kubernetes.io/docs/concepts/cluster-administration/addons/
以上是k8s的基本组成。
图形界面的粉丝们也可以欢呼了,k8s的Dashboard组件提供了WEB UI功能,容器用户也能像VMWare用户一样靠鼠标完成工作了。我见过好几个用户对于k8s的容器自动编排、负载均衡等并不是很需要,纯粹就为了使用Dashboard而配置k8s集群。Dashboard是单独的一个Pod,没有Dashboard并不影响k8s集群的运行,是在集群安装完成后单独部署执行的。
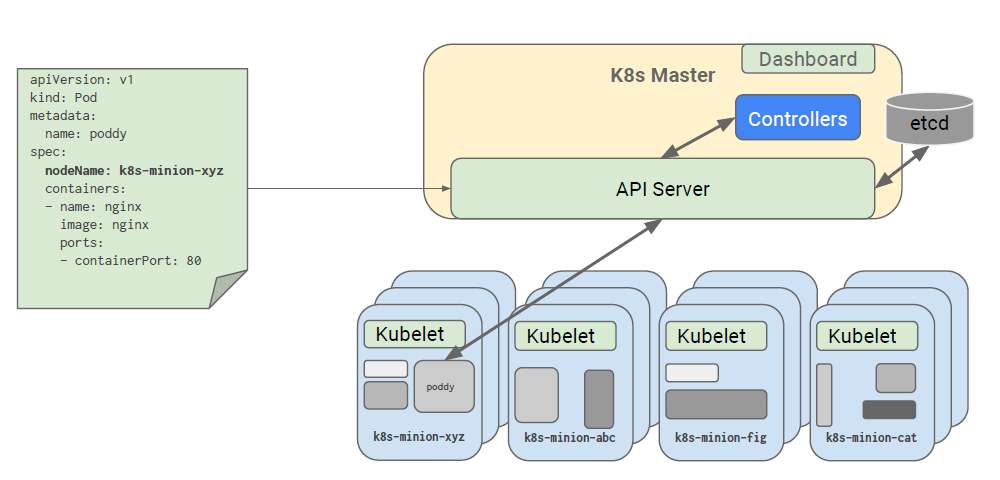
类似于使用Docker的核心就是操作容器。k8s操作的核心单元是Pod。一个Pod是k8s操作的最小单元,包括一个或者多个容器、存储、网络、服务。可能有多个容器的原因是,稍复杂的应用,可能都不是一个容器可以承载的。强制放在一个容器里,往往也增大了粒度,降低了资源使用效率。比如通常一个小网站,可能至少有一个WEB服务器,然后还有一个数据库服务器。这就是两个容器。如果是在Docker中,你可能需要分别启动两次,而在k8s之中,这两个容器可以属于一个Pod,统一进行管理。此外比较重要的一个概念,k8s可以根据要求,一次启动Pod的多个实例,相当于对于某个应用投入了更多的计算资源,从而应对高负荷应用。
Service是k8s管理的另外一个对象,容器的运行,归根结底是对外提供服务。网络服务实际上就是开放某个端口,通过端口对外提供服务。不同于Docker中简单的端口映射。k8s中可以启动某Pod的多个实例,这些Pod中的程序,肯定对外提供了同一个接口进行服务。Service可以提供基本的负载均衡功能,把外部连接进来的访问流量调度到不同的Pod上,让集群的规模化发生作用。而如果在Docker上,则只能自行配置外加的负载均衡方案来达成同样的功能,麻烦就不说了,Docker及负载均衡方案之间的衔接使得容器列表发生变动的时候很可能发生服务的阻塞。k8s的负载均衡是使用内部的DNS服务(用于动态解析Pod的IP地址,相当于服务发现)和Kube-Proxy(将流量动态分配到不同的Pod)共同来完成的。
Volume就是用于映射到容器内工作目录的存储目录或者设备。k8s在Docker的基础上根据需要更加细分了存储设备的类型,包括普通的目录映射、iSCSI之类的硬件存储设备、甚至商业云存储服务。这让容器技术更具有实用性。
Namespace允许为Pod添加更细致的分类管理。这在大的集群中非常必要,想想如果没有Namespace,几千台容器在列表中是怎样恐怖的场景。
k8s集群的安装
前面已经说过生产使用的集群环境最好使用redhat/centos或者专门定制的Linux环境。不过简化操作和保持一致性,这里还是以Ubuntu18.04LTS为例来简单描述一下k8s的安装过程。
步骤一:基本准备工作
1.首先是设置集群中每台设备的IP地址,我们这里使用两台服务器来做集群安装的示范:
master 10.96.200.150
node1 10.96.200.160
IP地址并没有特别要求。但通常上,一个实体机集群的IP地址应当综合考虑,位于独立的地址段。大集群的内部安全问题如果也是重点的话,还应当考虑划分VLAN做内部的IP地址隔离。
考虑到集群可能会逐步扩展,所以在master的地址之后建议空出来部分,以便将来集群增大之后增加master节点的数量。
Ubuntu18.04版本的IP地址设置做了比较大的改变。不再使用/etc/network/interfaces的配置文件。而转为使用/etc/netplan/下的yaml文件。
netplan之下可以有多个yaml文件,用于更精细的管理多种环境、多网卡的应用场景。通常刚安装完系统,默认只有一个文件,这个名字可能因具体版本和设置不同不一样。我们的设置比较简单,就直接在这个文件基础上编辑就好,请参考下面的内容:
//大多的安装工作需要使用root权限,所以先进入root模式
$ sudo su
//显示配置文件内容
# cat /etc/netplan/01-netcfg.yaml
//以下是文件的内容
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses: [10.96.200.150/24]
gateway4: 10.96.200.1
nameservers:
addresses: [10.96.200.1]
这种设置方式很简单,相信你一看就懂。请根据你的网络情况,正确设置这个配置文件。 设置完成后,让配置文件生效:
# netplan apply
2.设置主机名称。k8s集群间的内部通讯是使用主机名完成的,管理的时候也是如此。所以建议首先设置有意义、易识别的主机名称,特别注意集群间不要重名。
在Ubuntu18.04中,主要有两个文件需要设置,一个是/etc/hostnamew文件,其中只有一个主机名。
此外是/etc/hosts文件中,127.0.1.1之后的第二个名字。
比如我为集群主机设置的名称为userver-master,请参考下面两个文件的内容:
# cat /etc/hostname
userver-master
# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 userver.lan userver-master
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
3.关闭系统的swap功能。这个功能相当于Windows下的虚拟内存,当内存不足的时候,系统使用交换分区来把内存中不常用的部分交换到磁盘上去。
对于通常的系统而言,内存交换很重要,很多大型的软件严重依靠虚拟内存机制。
但对于一个容器服务器系统,硬盘参与的内存交换显然降低了效率。是否需要做内存、磁盘的交换,应当由容器内的系统决定,而不是由宿主机。
操作上首先关闭当前系统的交换功能:
# swapoff -a
随后把磁盘交换分区也关闭,防止重启后依然使用交换系统:
# vi /etc/fstab
//将其中交换分区一行使用注释符屏蔽起来,比如:
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
/dev/mapper/userver--vg-root / ext4 errors=remount-ro 0 1
#/dev/mapper/userver--vg-swap_1 none swap sw 0 0
/dev/fd0 /media/floppy0 auto rw,user,noauto,exec,utf8 0 0
4.安装Docker和curl工具:
k8s是基于容器的生产级容器编排、管理工具。当前已经支持多款容器产品,不仅仅是Docker。但当前从行业中看,使用Docker作为基本的容器管理工具还是主流。
# apt-get update
// ... 输出略
# apt-get install -y docker.io curl
// ... 输出略
这里安装的是Ubuntu内置源的Docker,上一小结说过,通常这个版本并不高。但版本高并不一定是好事,大多情况下用户最多的版本往往拥有最好的稳定性。希望安装更新版本Docker的可以参考相关文档使用Docker的官方源安装。
步骤二:安装kubeadm等k8s基本命令行工具:
//安装k8s软件仓库的签名
# curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
注意从这一步开始,我们使用了国内的阿里云镜像服务器,尝试过不少镜像仓库,阿里云的镜像质量还是最好的。一直以来,国内的k8s尝鲜者最大的困难,不是学习、使用k8s,而是获取k8s的软件映像。谁让k8s是Google团队作品呢:(。在此对阿里云镜像团队的帮助表示致敬,建一镜像,胜造七级浮屠。
//添加k8s阿里云软件镜像仓库
# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
//更新仓库索引,让阿里云镜像仓库生效
# apt update
//安装3个基本的命令行组件
# apt install -y kubelet kubeadm kubectl
//设置这三个组件不自动更新,如前所述,稳定才更重要
# apt-mark hold kubelet kubeadm kubectl
步骤三:
使用kubeadm集群管理工具自动安装集群主机:
//参数表示:
//使用阿里镜像仓库,安装版本v1.13.4(成文时最新的版本)
//设置pod工作的网段
kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.13.4 --pod-network-cidr=192.168.0.0/16
因为使用了国内的镜像仓库,网络环境没问题的话,通常几分钟就能完成安装。屏幕上会有比较长的输出,如果中间安装中断,请根据出错信息排查问题。一直到最后,会出现类似如下的信息:
...略...
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 10.96.200.150:6443 --token zh248e.ivkr6ui3oboxzlji --discovery-token-ca-cert-hash sha256:5e67092d5979a189e0dbb9265a616e62a25d949205d208630933d1cc101dc039
请将上面这部分信息拷贝到记事本留存下来,以后对集群的配置管理会用到。
如果安装完成后,需要对主机的设置进行修改,比如修改IP地址、主机名称等,需要对k8s的多个设置文件进行修改。如果修改内容多的话,可能往往不如你删除当前集群,重新进行配置。
这时候可以使用如下命令:
kubeadm reset
千万注意,一个正常使用的集群千万不要使用这个命令,刚才说了,这等于删除当前集群:)
接着设置用户的操作环境。不同于Docker必须使用root执行,其实这也是一直被很多用户诟病的。root操作的隐患有很多,操作不当造成的损失是一方面,因为容器的特征,事实上在宿主机中使用root用户查看当前进程,所有容器中的程序都是无所遁形,这在安全性上也是无法接受的。
k8s部署集群的时候当然必须使用root,但投产后开始运维,允许使用普通用户操作集群。
设置方法也很简单,就是集群初始化时候最后输出信息的部分:
//退出root状态到普通操作用户
# exit
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
此时,在这个用户下,已经可以做基本的k8s操作了,我们来看一下当前有哪些Pods运行着。当然,这些都是k8s本身的,我们自己还没有运行任何Pod。默认情况下k8s自己的Pods是不会被列出的,所以我们这里使用了–all-namespaces参数:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78d4cf999f-6pgfr 0/1 Pending 0 87s
kube-system coredns-78d4cf999f-m9kgs 0/1 Pending 0 87s
kube-system etcd-master 1/1 Running 0 47s
kube-system kube-apiserver-master 1/1 Running 0 38s
kube-system kube-controller-manager-master 1/1 Running 0 55s
kube-system kube-proxy-mkg24 1/1 Running 0 87s
kube-system kube-scheduler-master 1/1 Running 0 41s
列表中是组成k8s的所有组件,希望详细了解k8s内部机理的同学可以按图索骥浏览详细的文档。
注意最上面的两个CoreDNS尚处于Pending状态。这是因为我们还没有配置网络插件。
步骤四:安装网络插件。
前面说过,因为容器技术本身并不包含网络功能。所以社区中自发的为容器开发了多种插件,其中能够被k8s支持的,在前面给出的链接中已经有详细介绍。可以根据自己的习惯选用。这里的安装使用Calico。
功能上,Calico会为每个容器分配一个IP地址,这个地址段是我们前面初始化集群的时候给定的,也就是:–pod-network-cidr=192.168.0.0/16。
每一个k8s节点相当于一个路由器,把不同nodes中的容器连接起来。
安装方法如下:
kubectl apply -f http://mirror.faasx.com/k8s/calico/v3.3.2/rbac-kdd.yaml
kubectl apply -f http://mirror.faasx.com/k8s/calico/v3.3.2/calico.yaml
因为网络原因,我们同样适用了国内镜像,这样速度会非常快。
注意从一步开始,我们已经可以使用普通的操作用户来操作k8s集群。而这两条命令,实际就是执行两个Pod,这两个Pod就赋予了容器网络功能。
这种软件的分发、配置、使用的方法,跟以往的传统虚拟化时代有了本质的不同。
一个大的软件,也会分解成多个小的容器来组装而成,相信你对“微服务”也有了更多感觉。
稍等几十秒,让Calico运行起来,我们可以再查看一下容器的状态:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-node-x96gn 2/2 Running 0 47s
kube-system coredns-78d4cf999f-6pgfr 1/1 Running 0 54m
kube-system coredns-78d4cf999f-m9kgs 1/1 Running 0 54m
kube-system etcd-master 1/1 Running 3 53m
kube-system kube-apiserver-master 1/1 Running 3 53m
kube-system kube-controller-manager-master 1/1 Running 3 53m
kube-system kube-proxy-mkg24 1/1 Running 2 54m
kube-system kube-scheduler-master 1/1 Running 3 53m
可以看到,最上面增加了一个calico的Pod,两个CoreDNS的Pods也执行起来了。
至此一个基本主控节点的k8s已经部署完成。
步骤五:添加工作节点。
工作节点可以有多个,我们这里只演示一个。首先参考前面步骤一和步骤二,如同Master节点一样,完成前两步的各项准备工作。
随后执行如下命令:
//执行拷贝自Master节点初始化的时候输出信息的最后一行
kubeadm join 10.96.200.150:6443 --token zh248e.ivkr6ui3oboxzlji --discovery-token-ca-cert-hash sha256:5e67092d5979a189e0dbb9265a616e62a25d949205d208630933d1cc101dc039
...略去的输出...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
只需要执行这一行命令,就可以完成把工作节点加入到集群。命令的输出信息中,如果显示上面相同的最后几行,则表示加入集群成功了。
上面命令的原型如下:
kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>
其中token和hash值都是由Master节点生成的,如果最初忘记了备份这些信息,都需要到Master节点上去获取:
//在Master节点上执行
//获取token值
$ kubeadm token list
zh248e.ivkr6ui3oboxzlji
//获取hash值
$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
5e67092d5979a189e0dbb9265a616e62a25d949205d208630933d1cc101dc039
token是有时间限制的,默认为24小时。如果超过时限加入工作节点,需要重新生成token:
//在Master节点执行
$ kubeadm token create
现在可以到主控节点上验证一下集群的工作情况:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
userver-master Ready master 17m v1.13.4
userver-node1 Ready <none> 15m v1.13.4
状态都是Ready,表示集群正常工作。注意工作节点加入集群需要一点时间,这跟服务器的运行速度有关,所以有可能需要稍等片刻工作节点才会在列表中出现。
步骤六:其它可选配置。
1.默认安装情况下,主控节点是不参与容器执行,只进行集群管理工作的。这在小的集群中,可能有浪费资源之嫌。这种情况下,可以取消Master节点上的“不可靠”标记,从而主控节点也能参与容器的部署运行。
注意“不可靠”标记是k8s的一种机制,用于标记运行中出现故障的节点,避免新的任务分配到故障节点上去。在这里当然不是指主控节点也故障了,而是不希望主控节点承担容器的工作,专注于对集群的管理。
$ kubectl taint nodes --all node-role.kubernetes.io/master-
node/userver-master untainted
error: taint "node-role.kubernetes.io/master:" not found
上面的执行结果中,第一行是去掉了主控节点的taint标记,第二行是在userver-node1上执行没有找到这个标记,不用去除,所以这个报错是正常的,不用理会。
使用这种方式,也可以在单独一台服务器上体验完整的k8s。Win/Mac版本的桌面版Docker内置了k8s,也是采用了类似的方式在一台电脑上提供出来完整的k8s实验环境。
2.安装Dashboard。
Dashboard是k8s的Web界面的UI系统。这个组件只是为了降低使用难度,提升用户友好度。但是从功能上,并不是必须的。喜欢使用鼠标操作的用户可以自己安装。
Dashboard是以Pod的形式发布的,所以所谓安装,其实就是执行一个Pod,这根前面安装的网络插件方式一样。官方提供了配置文件bernetes-dashboard.yaml可以直接运行。但是由于国内网络的问题和复杂的权限问题,我建议使用修改版。
首先下载阿里云的镜像版本的配置文件:
$ curl -O https://raw.githubusercontent.com/AliyunContainerService/k8s-for-docker-desktop/master/kubernetes-dashboard.yaml
//下载后编辑文件,做我们需要的修改
$ vi kubernetes-dashboard.yaml
//文件的最后,服务设置部分,替换成下面的内容:
# ------------------- Dashboard Service ------------------- #
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 32767
selector:
k8s-app: kubernetes-dashboard
type: NodePort
修改的内容,是将原本只能本机访问的端口映射出来到节点主机的32767端口。
网上大多数资料都是使用kubectl的proxy子命令来做Dashboard服务映射。但问题是大多使用Dashboard的用户都不会满足于只在服务器本机使用浏览器,何况服务器版本的Ubuntu根本没有图形界面。而把端口映射到外面会有很多安全性问题和权限控制问题。所以除非你对k8s非常熟悉,并且有能力自己定制一些安全机制,否则不建议那样使用。
配置文件修改好了之后,使用如下命令执行:
$ kubectl apply -f kubernetes-dashboard.yaml
如果是第一次运行的话,需要下载映像,阿里云的镜像网站还是速度挺快的,应当不用等很久。
继续使用kubectl get pods --all-namespaces命令可以查看Pod的执行情况,从而了解Dashboard是否正常运行。
顺便提一句,apply执行Pod只需要运行一次。因为复制器的功能,以后重启系统后,Dashboard也会自动启动起来。这个在概念部分说过了。
接下来还要为Dashboard建立一个管理员用户,系统内置的default用户权限太小,大多信息都无法查询,所以不建议使用default。
请将下面内容保存到一个配置文件,比如叫dashboard-adminuser.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
然后在集群执行:
$ kubectl apply -f dashboard-adminuser.yaml
//用户建立后,获取admin用户的Token
$ kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
//将下面输出的token部分拷贝备份起来,作为将来的登录使用
Name: admin-user-token-snppt
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: 6ec3f9a0-4796-11e9-ade6-000c29dfacdd
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXNucHB0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI2ZWMzZjlhMC00Nzk2LTExZTktYWRlNi0wMDBjMjlkZmFjZGQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.eFIzEuGyY_ipi2bLH7tYbDnkjFmDK_sT1uvAmV7dU2mpxgTptpo7tI2qSNmijRcf5LG02ft5rqq5F_IM3jFHrhhwnMG6wz9ccpABR1oqQE8FYxFo8sflETbeUMFCtbm7uPUMI-H4civ6lA_8hZtNKy4VHUUOlAWGDu1EPUV7RBgmX2a2cbcQLlaUWVS_xAG8A5jSHD_LgWM4GEqN5kq2tNCiVNJkf1FHNx9m9x_BJM4ZJCdhKJdVIjnxORG7gUGQeLXr0Q8iRRi0bFqSoAn213Ml2WQbX2RsB0W1ty144EzSj8KeX6uwhN2n2TGsqXJN5S76AArSl4rxKBk9bInkDg
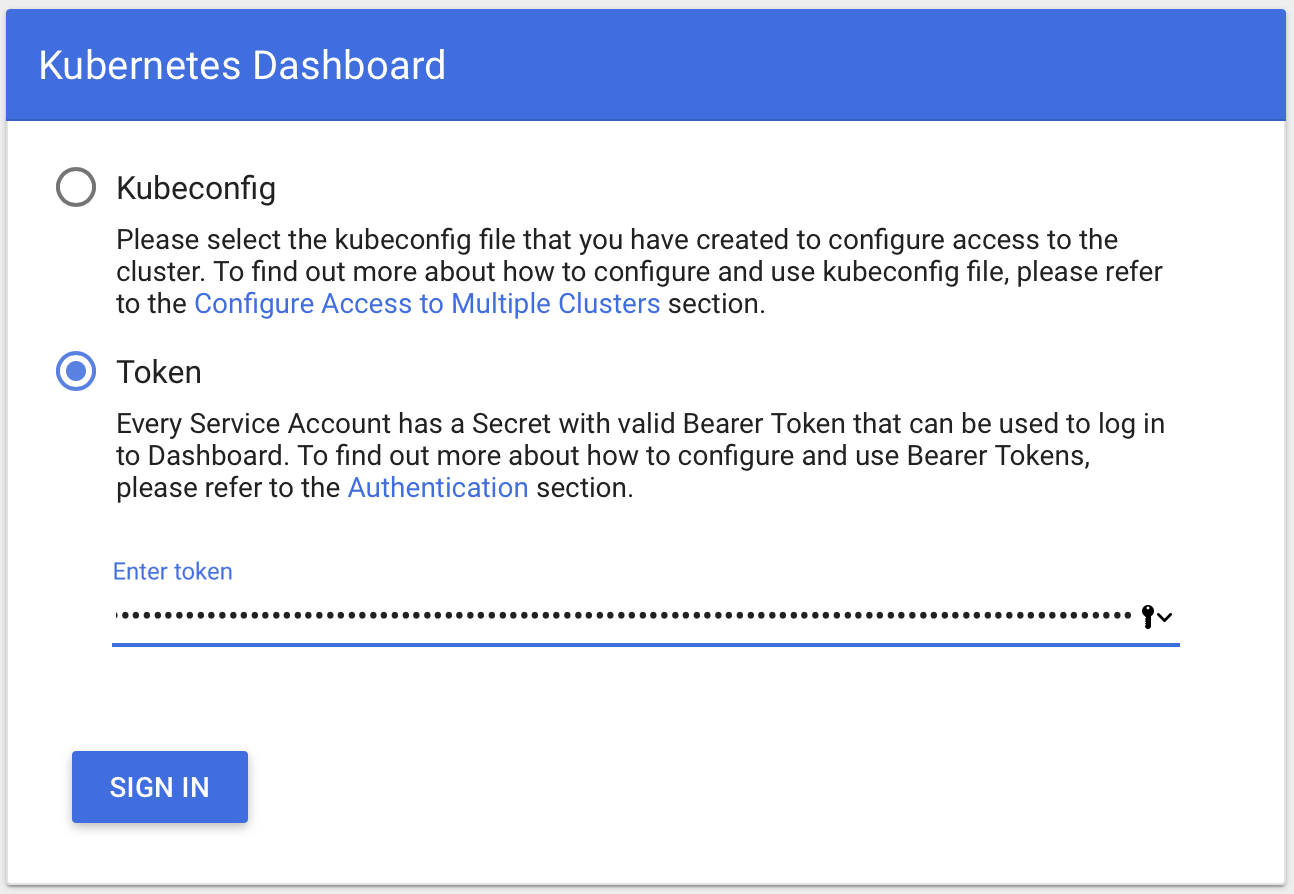
现在使用https协议访问主控节点IP地址的32767端口就能看到控制台登录界面了:https://10.96.200.150:32767,因为使用了私有的证书,所以还要确认忽略掉浏览器的警告信息窗口。
登录Dashboard控制台使用Token模式,这个Token就是我们刚才建立用户的时候所获得的TOKEN,跟前面加入工作节点所使用token的不是同一个东西。
 Dashboard还可以安装一些酷炫的插件,用于图形化的显示系统的负载、使用情况,有兴趣可以参考此文:https://iamchuka.com/install-kubernetes-dashboard-part-iii/
Dashboard还可以安装一些酷炫的插件,用于图形化的显示系统的负载、使用情况,有兴趣可以参考此文:https://iamchuka.com/install-kubernetes-dashboard-part-iii/
至此,集群的安装全部结束。
k8s基本使用
先从执行一个容器开始,当然这个容器在k8s中是以Pod的形式执行的。下面这条命令,将建立并下载、运行一个nginx容器:
$ kubectl create deployment nginx --image=nginx:alpine
deployment.apps/nginx created
执行完成后,查看执行的Pods列表:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-54458cd494-5g5cq 0/1 ContainerCreating 0 14s
这表示nginx部署已经开始建立,实际上因为第一次运行nginx,这个过程主要是从网上下载映像文件的时间。通常速度都很快,如果你进入root用Docker查看一下nginx映像,你会发现容量只有令人惊讶的16M。
当然,因为我们身处国内,这么小的映像,也有可能无法下载。碰到这种情况你只能自己想想办法了:)
稍等再次执行查看Pods列表:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-54458cd494-5g5cq 1/1 Running 0 56s
这说明nginx容器已经部署并且执行,并且k8s内置的复制器组件会保证集群中始终有一个nginx容器在执行。类似出现运行中的nginx容器死机了或者崩溃了,k8s的复制器会删除当前容器并重新执行一个nginx容器从而保证容器数量为1。
比如我们尝试直接删除这个Pod:
$ kubectl delete pods nginx-54458cd494-5g5cq
pod "nginx-54458cd494-5g5cq" deleted
再次查看Pods列表:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-54458cd494-4v4v8 1/1 Running 0 6s
可以看到,nginx-54458cd494-5g5cq已经不见了,取而代之的是:nginx-54458cd494-4v4v8。
我们一会儿再学习如何正确删除Pods,先继续复制器的话题。
复制器是一个强大的工具,基本透明的贯穿在k8s之中,大多数不需要单独的操作。Google官方自称k8s为“生产级别的容器编排系统”,这个编排实际就是复制器的基本能力。而因为有了这种自动编排,以并发换速度;以快速启动新的容器替代有故障的容器,才是“生产级”的内涵。
下面我们可以操作复制器,把当前执行的nginx容器扩展为3个:
$ kubectl scale deployment nginx --replicas=3
deployment.extensions/nginx scaled
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-54458cd494-4v4v8 1/1 Running 0 10s
nginx-54458cd494-5g5cq 1/1 Running 0 4m15s
nginx-54458cd494-mxmqq 1/1 Running 0 10s
列表中,原有的容器还在,另外增加了2个,共3个Pods在运行中。
这里强调一下,k8s为大规模的并发提供了运维手段。但软件的研发需要相应的从设计伊始就将并发的支持贯穿在开发中。比如多台服务器间如何同步数据、共享session等。否则同时并发大量的服务器不仅不能提高系统的负载能力,反而可能造成数据的混乱或者系统的互锁。
kubectl的get子命令是获取k8s各项信息很常用的工具,需要认真掌握。比如我们让列表显示更多信息:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-54458cd494-4v4v8 1/1 Running 0 76s 192.168.1.5 userver-node1 <none> <none>
nginx-54458cd494-5g5cq 1/1 Running 0 5m21s 192.168.1.4 userver-node1 <none> <none>
nginx-54458cd494-mxmqq 1/1 Running 0 76s 192.168.0.10 userver-master <none> <none>
在生产环境中,当运行的Pods比较多的时候,我们还需要对列表进行过滤。不然你根本找不到你需要的Pod。比如使用app的名称进行过滤:
//使用了过滤器,当然这里跟上面执行结果是一样的,因为我们没有运行别的Pods
$ kubectl get pods -o wide -l app=nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-54458cd494-4v4v8 1/1 Running 0 76s 192.168.1.5 userver-node1 <none> <none>
nginx-54458cd494-5g5cq 1/1 Running 0 5m21s 192.168.1.4 userver-node1 <none> <none>
nginx-54458cd494-mxmqq 1/1 Running 0 76s 192.168.0.10 userver-master <none> <none>
k8s通过etcd组件支持使用key/value对儿的标签体系和标签过滤来精确定位Pods,从而降低操作复杂性。比如删除Pods的时候,也可以使用这种标签过滤的方式选择多个删除对象,:
$ kubectl delete pods -l app=nginx
pod "nginx-54458cd494-4v4v8" deleted
pod "nginx-54458cd494-5g5cq" deleted
pod "nginx-54458cd494-mxmqq" deleted
当然了,因为复制器的存在,当前的三个容器被删除,复制器会自动启动3个新的容器,来保证nginx容器总数为3:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-54458cd494-cjcjr 1/1 Running 0 20s 192.168.0.11 userver-master <none> <none>
nginx-54458cd494-ncz4n 1/1 Running 0 20s 192.168.1.7 userver-node1 <none> <none>
nginx-54458cd494-vjzb6 1/1 Running 0 20s 192.168.1.6 userver-node1 <none> <none>
可以分别测试三个Pods的工作情况:
$ curl 192.168.0.11:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
$ curl 192.168.1.7:80
...
//80端口是默认的http端口,可以省略
$ curl 192.168.1.6
...
现在三个容器都正常工作了,但访问都是通过的内网,如果想在外网访问,就需要配置k8s的端口服务,把端口暴露出来:
$ kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
service的概念我们前面讲过,这里实际上就是建立了一个服务,类型是NodePort。把容器的80端口开放出来,到一个随机的端口号,端口号的范围默认是30000-32767可以修改。端口的映射是由kube-proxy完成的,因为kube-proxy在每台节点服务器上都会运行,所以访问任一节点的IP地址,配合这个指定的端口号,就可以访问到nginx的输出,这种模式就叫NodePort。kube-proxy的映射功能同时包含了负载均衡的流量分配能力。并且因为服务的建立就是映射到了指定的Pods群,也无需再次进行服务发现。
使用下面命令查看这个服务的具体信息,其中有端口号:
$ kubectl get services nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx NodePort 10.106.91.63 <none> 80:31739/TCP 2m29s
上面信息表明,对外映射的端口为31739。其中CLUSTER-IP是在容器内部访问时候使用的,在外部是访问不到的。这里的CLUSTER也不是指的k8s集群,而是指是我们启动了几个nginx Pods,是运行在k8s集群上的nginx的集群,这一点一定不要误会。之所以单独给出一个独立的内部IP地址,是因为在开发中,内部的服务访问同样也需要负载均衡和隐含其中的服务发现。
我们测试一下:
$ curl 10.96.200.150:31739
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
$ curl 10.96.200.160:31739
...
在实际应用中,访问任意一台节点的对应端口都是可以的。端口服务建立的时候,也可以指定只捆绑某个IP地址的端口,请参考命令的帮助文档。
下面我们再开一个Pod,看看容器内部对其它容器的访问。
这次我们开一个busybox的容器,以便使用bash shell操作:
$ kubectl run -it --generator=run-pod/v1 curl --image=radial/busyboxplus:curl
[ root@curl-66959f6557-wpp5p:/ ]$
因为我们希望使用互动终端的方式(参数-it)执行Pod,所以直接使用kubectl的run子命令。
执行之后,如果是第一次使用busybox,需要下载映像,所以要有片刻的等待。当然速度也会很快,因为这个映像只有4M多的容量。
随后出现的提示符,已经是容器中的shell提示符。
在其中执行:
[ root@curl-66959f6557-wpp5p:/ ]$ nslookup nginx.default.svc.cluster.local
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx.default.svc.cluster.local
Address 1: 10.106.91.63 nginx.default.svc.cluster.local
[ root@curl-66959f6557-wpp5p:/ ]$ curl nginx.default.svc.cluster.local
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
注意名称:nginx.default.svc.cluster.local是我们刚才建立的端口服务的全称。也就是nginx这个名字,加上.default.svc.cluster.local后缀。得到的IP地址,你会发现,跟上面的CLUSTER-IP地址是完全相同的。
因为无论是CLUSTER-IP,还是每台容器的地址,都是动态变化的。所以在编程中,应当坚持使用nginx.default.svc.cluster.local这样的名称来访问其它的服务,就像上例中curl获取nginx首页做的那样。这样做一是保证程序的可迁移性,也是为了利用系统内置的负载均衡机制。
Pod一旦建立,不管是Pod崩溃退出,还是集群重启,都会自动重新运行。并且会保证数量跟复制器设定的数量吻合。
所以当容器不再需要的时候,我们需要显式的删除,方法如下:
//删除对外的端口服务
$ kubectl delete services nginx
service "nginx" deleted
//删除部署
$ kubectl delete deployment nginx
deployment.extensions "nginx" deleted
$ kubectl delete deployment curl
deployment.extensions "curl" deleted
//一些容器的停止需要时间,所以稍等再执行...
$ kubectl get pods
No resources found.
上面介绍的,是从使用VMWare起步,到Docker,再延伸而来的习惯,是基于映像文件的使用方法。k8s的魅力远非止步于此。
我们使用中可能有很多感受,就是用这种方式使用容器,命令行冗长,不容易记忆,更不方便修改和定制,对于写入脚本重复使用也不方便。
k8s引入了使用参数文件来表述容器的各方面配置,易读易用。官方推荐的是yaml文件。
在上一小节介绍安装的时候说过,Ubuntu新版本中也把yaml格式作为部分配置文件的标准。yaml算得上继json之后最新一代的结构化文档格式了。yaml文件有几个简单的须知:
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- #表示注释,从这个字符一直到行尾,都会被解析器忽略。
k8s也支持json格式的配置文件,只是网上大多数存在的资源都已经使用了yaml,所以建议你也从yaml开始,跟社区保持相同。
在官方的文档中,编写配置文件的说明并不是yaml使用说明,而是“使用Deployment运行应用”,路径为:https://kubernetes.io/zh/docs/tasks/run-application/run-stateless-application-deployment/,一定要仔细阅读。
作为串讲,这里举一个小例子。首先列出yaml文件:
---
apiVersion: v1
kind: Pod
metadata:
name: web-site
labels:
app: web
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
- name: helloecho
image: hashicorp/http-echo
args:
- "-text=hello"
ports:
- containerPort: 5678
---
apiVersion: v1
kind: Service
metadata:
name: web-site-svc
spec:
type: NodePort
ports:
- name: nginx-port
port: 80
targetPort: 80
- name: helloecho-port
port: 88
targetPort: 5678
selector:
app: web
使用“—”分割线隔开,这个文件中包含了两个k8s任务,一个是定义Pod,一个是定义对外暴露端口的服务。每个yaml文件中,包含一个任务就可以。但为了便于管理,完成一个工作的多个任务习惯写在一起,这样一次执行就能完成全部工作,并且不用担心执行的顺序。
apiVersion一行指的是k8s的接口版本。yaml实际相当于根据k8s的接口规范来完成任务。
kind指定任务类型,这里分别演示了Pod和Service。
metadata部分是任务相关的key/value对儿,name是必须的,最终就是Pod和Service的名字。labels下面的则是自己定义的,自己定义的目的是为了将来对相关对象的检索。比如Service定义暴露端口的时候,使用selector指令使用app检索为:web的Pod。
这是一个典型的一个Pod中包含多个容器的示例。下面的spec中是定义的主要部分,我觉得不用多解释应当能看懂。这里使用了一个标准的nginx,一个http协议的echo小工具。echo工具的定义里面,使用args指令指定参数“-text=hello”来定制一个“hello”的字符串反馈信息。很多简单系统里面,会用这个小工具做健康检查的信息反馈。
服务的定义里面,使用NodePort模式(看我们前面的例子)来暴露两个对外服务端口,分别映射到nginx和echo两个容器。
上面的文件保存到一个yaml文本文件,比如叫:web-test.yaml。随后可以执行这个文件:
//执行配置文件,建立Pod和Service
$ kubectl apply -f web-test.yaml
pod/web-site created
service/web-site-svc created
//查看Pod
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
web-site 2/2 Running 0 14s
//查看服务
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 31d
web-site-svc NodePort 10.104.214.83 <none> 80:31686/TCP,88:30298/TCP 7s
//测试nginx
$ curl 127.0.0.1:31686
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
//测试echo
$ curl 127.0.0.1:30298
hello
如果有root权限,还可以进一步使用docker ps来检查一下容器运行的情况。可以看到同一个Pod中的nginx跟helloecho分别是两个不同的容器。这里就略掉了。
如果Pod没有像预期的一样执行,使用kubectl get pods命令查看pods列表的时候会看到状态不是Runing。如果仍然无法判断错误来源,使用命令kubectl describe pods web-site能够看到同Pod相关的所有详细信息,其中包括出错的信息,可以帮助你判断未能启动的原因。
测试过程结束后,依靠配置文件删除这个应用也变得简单了:
$ kubectl delete -f web-test.yaml
pod "web-site" deleted
service "web-site-svc" deleted
你可能还有一个疑问,这两个容器之间,似乎什么关系也没有啊,为什么要放到一个Pod中?的确如此,一方面这里仅仅是个演示,简单介绍如何使用yaml配置文件自动化部署的过程。再者,从运维端看,运维的目的就是把各部分容器正常运行起来,时刻让其保持在健康的状态,及时处理各类异常事件。
从某一个容器中,如何访问另外一个容器的计算结果,并进行有机的组合和相关处理,是软件开发过程中解决的问题,运维人员基本没有可能去干涉。
在k8s集群的运维过程中,Docker容器层产生的过期容器及不再使用的镜像,会由Image Collection
及Container Collection自动回收,正常使用情况下,并不需要运维人员手工删除。
作为全面操控k8s的配置文件,这算的上最简单的例子。还有很多指令需要学习,请尽快阅读相关文档。参考别人的使用示例也是快速学习的一种手段,推荐一个使用k8s配置WordPress应用的讲解:https://kubernetes.io/docs/tutorials/stateful-application/mysql-wordpress-persistent-volume/
一般来说,构建k8s集群中的生产环境,同以前使用传统虚机的方式并没有什么不同,通常是这样的工作流程:
- 整个生产系统,包含几个部分的软件模块
- 根据软件模块划分,使用尽可能小的粒度,分别构建Docker映像,并规划服务端口
- 分析这些软件模块相互间的关系,确定模块间共享和沟通数据的方式
- 根据软件间相关关系建立k8s的存储对象和网络对象,并形成yaml配置文件
- 根据软件模块相互间的关联度,考虑高关联的是否需要放入同一个Pod
- 分析根据随着运行压力的增长,软件模块需要增加计算量的数量级关系,数量级相关性强的需要考虑是否放置在同一个Pod,以便自动编排时同时增加部署数量
- 根据以上分析结果,手工运行容器进行概念测试
- 根据测试结果,经过修正,构建Pod部署的yaml配置文件
- 构建端口服务配置文件
- 测试运行 整个的过程中,软件研发部门和运维部门需要高度的配合,共同完成工作。
继续演进
k8s在企业级运维的占用率快速的增长,然而新的需求继续出现。
最核心的问题是,k8s的集群系统,是由主控和工作节点两个部分做成的。小的集群中,只需要一个主控节点。大集群中,k8s提供了高可用的模式(Highly Available Clusters),这种模式支持最少3台主控节点组成主控组,来统一管理整个的k8s集群。
但是即便在这种高可用的模式下,仍然需要配置负载均衡机制,比如HAProxy,放置在控制群组之前,这无可避免的成为了又一个单点瓶颈。
此外还有一些需求,比如对容器的监控功能不足,调试容器的配置问题需要研发团队配合输出大量的日志信息。再比如红黑发布的导流控制等。
在开源社区中,只要有需求,就有大量的团队为此努力,开发出同样大量的产品或者插件。在其中,这次是Istio脱颖而出。
 简单来说,Istio采用了比较新的思路来解决问题。最主要的就是,原本每个容器,需要同管理节点之间建立通讯连接,沟通容器状态及接受控制信息。因为这种机制,管理节点的健康状况和负载能力,成为了整个系统的瓶颈。
简单来说,Istio采用了比较新的思路来解决问题。最主要的就是,原本每个容器,需要同管理节点之间建立通讯连接,沟通容器状态及接受控制信息。因为这种机制,管理节点的健康状况和负载能力,成为了整个系统的瓶颈。
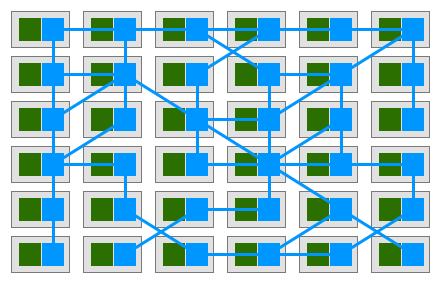
Istio同样也是在容器上配置自己的组件(Sidecar),但这些控制数据流,不再沟通到某个具体的管理节点,而是所有节点直接互相沟通,组成了一个服务网格(ServiceMesh)。网格中任意一个容器出现问题,并不影响整个网格的信息传递和控制,故障的容器同样也会在服务支持下被删除,并被新生成的容器替代。系统不再存在单点瓶颈。
Sidecar的核心是代理机制,接管了所有进出容器的通讯流。在这种机制的帮助下,在流量管理、安全性、控制、和监控方面,显然有了更可靠的手段。因此在Istio首页(https://istio.io)上,这四个特征成为了主要的卖点:
- 连接(Connect)流量管理:智能控制服务之间的调用流量,能够实现灰度升级、AB 测试和红黑部署等功能
- 安全加固(Secure):自动为服务之间的调用提供认证、授权和加密。
- 控制(Control):应用用户定义的策略,保证资源在消费者中公平分配。
- 可观察性(Observe):查看服务运行期间的各种数据,比如日志、监控和 tracing,了解服务的运行情况。
应当说单纯这些功能,在社区中都有不错的组件可以完成,为了少量的需求安装一个轻型的组件也很经济。实际上Istio也直接或者间接的使用了大量社区贡献的组件。但有一点一定要明白,虽然安装同样的组件能够完成同样的功能,但除非使用了Istio的Sidecar机制,否则需求是满足了,但并没有解决单点瓶颈问题,并不是ServiceMesh。
(Sidecar本意是指跨斗摩托车边上的跨斗,这里指正式任务容器旁边再附着一个管理的容器,组成服务网格。Sidecar用在这里是非常形象的说法。)
Istio的安装
Istio可以在k8s上直接安装,这个相爱相杀的世界啊:)
当然这个特征是k8s的市场占有率决定的,支持k8s能让Istio更易用也有更多用户。实际上Istio可以在纯Docker环境配合Docker Compose安装,并且在没有k8s存在的情况下独立运行。
在k8s集群下安装Istio,两个产品的功能都能保留并且和平共处,不失为一种好的解决方案。很多企业也是这样做的。
依然建议你去官网仔细阅读文档https://istio.io/zh/docs/,Istio的中文文档做的非常棒。 接下来是串讲的简化版本。
Istio也是分为命令行控制工具和容器化的系统两部分。安装之前请先确认一下硬件配置,Docker+k8s+Istio所需最小的内存是4G,上一节我们使用2G内存来学习k8s,现在是不够用的。
在k8s的主控节点上安装命令行工具及示例等:
$ curl -L https://git.io/getLatestIstio | sh -
getLatestIstio是官方提供的下载脚本,下载后自动执行,完成后,可以把最新版本的CLI安装于当前目录。
随后把Istio的程序目录加入路径:
//路径设置.bashrc,重新登录生效
echo "export PATH=$PATH:$PWD/istio-1.0.6/bin" >> ~/.profile
//修改当前路径设置
export PATH=$PATH:$PWD/istio-1.0.6/bin
接着是安装Istio的主体部分:
//进入到Istio下载目录,下面所使用的yaml文件都使用了相对路径
$ cd istio-1.0.6/
//在k8s中自定义资源类型
$ kubectl apply -f install/kubernetes/helm/istio/templates/crds.yaml
customresourcedefinition.apiextensions.k8s.io/virtualservices.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/destinationrules.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/serviceentries.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/gateways.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/envoyfilters.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/policies.authentication.istio.io created
customresourcedefinition.apiextensions.k8s.io/meshpolicies.authentication.istio.io created
customresourcedefinition.apiextensions.k8s.io/httpapispecbindings.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/httpapispecs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/quotaspecbindings.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/quotaspecs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/rules.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/attributemanifests.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/bypasses.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/circonuses.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/deniers.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/fluentds.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/kubernetesenvs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/listcheckers.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/memquotas.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/noops.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/opas.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/prometheuses.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/rbacs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/redisquotas.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/servicecontrols.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/signalfxs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/solarwindses.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/stackdrivers.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/statsds.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/stdios.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/apikeys.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/authorizations.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/checknothings.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/kuberneteses.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/listentries.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/logentries.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/edges.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/metrics.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/quotas.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/reportnothings.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/servicecontrolreports.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/tracespans.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/rbacconfigs.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/serviceroles.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/servicerolebindings.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/adapters.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/instances.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/templates.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/handlers.config.istio.io created
//安装基本版本的Istio
$ kubectl apply -f install/kubernetes/istio-demo.yaml
namespace/istio-system created
configmap/istio-galley-configuration created
configmap/istio-grafana-custom-resources created
configmap/istio-grafana-configuration-dashboards created
configmap/istio-grafana created
configmap/istio-statsd-prom-bridge created
configmap/prometheus created
configmap/istio-security-custom-resources created
configmap/istio created
configmap/istio-sidecar-injector created
serviceaccount/istio-galley-service-account created
serviceaccount/istio-egressgateway-service-account created
serviceaccount/istio-ingressgateway-service-account created
serviceaccount/istio-grafana-post-install-account created
clusterrole.rbac.authorization.k8s.io/istio-grafana-post-install-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-grafana-post-install-role-binding-istio-system created
job.batch/istio-grafana-post-install created
serviceaccount/istio-mixer-service-account created
serviceaccount/istio-pilot-service-account created
serviceaccount/prometheus created
serviceaccount/istio-cleanup-secrets-service-account created
clusterrole.rbac.authorization.k8s.io/istio-cleanup-secrets-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-cleanup-secrets-istio-system created
job.batch/istio-cleanup-secrets created
serviceaccount/istio-security-post-install-account created
clusterrole.rbac.authorization.k8s.io/istio-security-post-install-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-security-post-install-role-binding-istio-system created
job.batch/istio-security-post-install created
serviceaccount/istio-citadel-service-account created
serviceaccount/istio-sidecar-injector-service-account created
customresourcedefinition.apiextensions.k8s.io/virtualservices.networking.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/destinationrules.networking.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/serviceentries.networking.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/gateways.networking.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/envoyfilters.networking.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/httpapispecbindings.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/httpapispecs.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/quotaspecbindings.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/quotaspecs.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/rules.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/attributemanifests.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/bypasses.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/circonuses.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/deniers.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/fluentds.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/kubernetesenvs.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/listcheckers.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/memquotas.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/noops.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/opas.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/prometheuses.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/rbacs.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/redisquotas.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/servicecontrols.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/signalfxs.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/solarwindses.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/stackdrivers.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/statsds.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/stdios.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/apikeys.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/authorizations.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/checknothings.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/kuberneteses.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/listentries.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/logentries.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/edges.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/metrics.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/quotas.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/reportnothings.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/servicecontrolreports.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/tracespans.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/rbacconfigs.rbac.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/serviceroles.rbac.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/servicerolebindings.rbac.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/adapters.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/instances.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/templates.config.istio.io unchanged
customresourcedefinition.apiextensions.k8s.io/handlers.config.istio.io unchanged
clusterrole.rbac.authorization.k8s.io/istio-galley-istio-system created
clusterrole.rbac.authorization.k8s.io/istio-egressgateway-istio-system created
clusterrole.rbac.authorization.k8s.io/istio-ingressgateway-istio-system created
clusterrole.rbac.authorization.k8s.io/istio-mixer-istio-system created
clusterrole.rbac.authorization.k8s.io/istio-pilot-istio-system created
clusterrole.rbac.authorization.k8s.io/prometheus-istio-system created
clusterrole.rbac.authorization.k8s.io/istio-citadel-istio-system created
clusterrole.rbac.authorization.k8s.io/istio-sidecar-injector-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-galley-admin-role-binding-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-egressgateway-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-ingressgateway-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-mixer-admin-role-binding-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-pilot-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-citadel-istio-system created
clusterrolebinding.rbac.authorization.k8s.io/istio-sidecar-injector-admin-role-binding-istio-system created
service/istio-galley created
service/istio-egressgateway created
service/istio-ingressgateway created
service/grafana created
service/istio-policy created
service/istio-telemetry created
service/istio-pilot created
service/prometheus created
service/istio-citadel created
service/servicegraph created
service/istio-sidecar-injector created
deployment.extensions/istio-galley created
deployment.extensions/istio-egressgateway created
deployment.extensions/istio-ingressgateway created
deployment.extensions/grafana created
deployment.extensions/istio-policy created
deployment.extensions/istio-telemetry created
deployment.extensions/istio-pilot created
deployment.extensions/prometheus created
deployment.extensions/istio-citadel created
deployment.extensions/servicegraph created
deployment.extensions/istio-sidecar-injector created
deployment.extensions/istio-tracing created
gateway.networking.istio.io/istio-autogenerated-k8s-ingress created
horizontalpodautoscaler.autoscaling/istio-egressgateway created
horizontalpodautoscaler.autoscaling/istio-ingressgateway created
horizontalpodautoscaler.autoscaling/istio-policy created
horizontalpodautoscaler.autoscaling/istio-telemetry created
horizontalpodautoscaler.autoscaling/istio-pilot created
service/jaeger-query created
service/jaeger-collector created
service/jaeger-agent created
service/zipkin created
service/tracing created
mutatingwebhookconfiguration.admissionregistration.k8s.io/istio-sidecar-injector created
attributemanifest.config.istio.io/istioproxy created
attributemanifest.config.istio.io/kubernetes created
stdio.config.istio.io/handler created
logentry.config.istio.io/accesslog created
logentry.config.istio.io/tcpaccesslog created
rule.config.istio.io/stdio created
rule.config.istio.io/stdiotcp created
metric.config.istio.io/requestcount created
metric.config.istio.io/requestduration created
metric.config.istio.io/requestsize created
metric.config.istio.io/responsesize created
metric.config.istio.io/tcpbytesent created
metric.config.istio.io/tcpbytereceived created
prometheus.config.istio.io/handler created
rule.config.istio.io/promhttp created
rule.config.istio.io/promtcp created
kubernetesenv.config.istio.io/handler created
rule.config.istio.io/kubeattrgenrulerule created
rule.config.istio.io/tcpkubeattrgenrulerule created
kubernetes.config.istio.io/attributes created
destinationrule.networking.istio.io/istio-policy created
destinationrule.networking.istio.io/istio-telemetry created
//验证一下安装的服务
$ kubectl get svc -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.99.63.62 <none> 3000/TCP 104s
istio-citadel ClusterIP 10.97.149.61 <none> 8060/TCP,9093/TCP 103s
istio-egressgateway ClusterIP 10.98.244.253 <none> 80/TCP,443/TCP 104s
istio-galley ClusterIP 10.105.199.110 <none> 443/TCP,9093/TCP 105s
istio-ingressgateway LoadBalancer 10.109.153.221 <pending> 80:31380/TCP,443:31390/TCP,31400:31400/TCP,15011:30607/TCP,8060:31625/TCP,853:30655/TCP,15030:32494/TCP,15031:31070/TCP 104s
istio-pilot ClusterIP 10.108.220.116 <none> 15010/TCP,15011/TCP,8080/TCP,9093/TCP 104s
istio-policy ClusterIP 10.101.97.253 <none> 9091/TCP,15004/TCP,9093/TCP 104s
istio-sidecar-injector ClusterIP 10.103.63.166 <none> 443/TCP 103s
istio-telemetry ClusterIP 10.107.184.81 <none> 9091/TCP,15004/TCP,9093/TCP,42422/TCP 104s
jaeger-agent ClusterIP None <none> 5775/UDP,6831/UDP,6832/UDP 101s
jaeger-collector ClusterIP 10.108.136.200 <none> 14267/TCP,14268/TCP 101s
jaeger-query ClusterIP 10.105.46.4 <none> 16686/TCP 101s
prometheus ClusterIP 10.102.94.141 <none> 9090/TCP 103s
servicegraph ClusterIP 10.96.220.16 <none> 8088/TCP 103s
tracing ClusterIP 10.105.46.106 <none> 80/TCP 101s
zipkin ClusterIP 10.106.153.194 <none> 9411/TCP 101s
//验证执行的Pods:
$ kubectl get pods -n istio-system
NAME READY STATUS RESTARTS AGE
grafana-59b8896965-vlbd5 1/1 Running 0 89s
istio-citadel-6f444d9999-cz6gk 1/1 Running 0 85s
istio-cleanup-secrets-29mcx 0/1 Completed 0 91s
istio-egressgateway-6d79447874-gzssf 1/1 Running 0 89s
istio-galley-685bb48846-wx8q4 1/1 Running 0 89s
istio-grafana-post-install-gkz6g 0/1 Completed 0 91s
istio-ingressgateway-5b64fffc9f-f8h2q 1/1 Running 0 89s
istio-pilot-7f558fc848-jtrqs 2/2 Running 0 88s
istio-policy-547d64b8d7-br5cn 2/2 Running 0 88s
istio-security-post-install-xz5xd 0/1 Completed 0 91s
istio-sidecar-injector-5d8dd9448d-m4lls 1/1 Running 0 83s
istio-telemetry-c5488fc49-g5vjw 2/2 Running 0 88s
istio-tracing-6b994895fd-6hwqv 1/1 Running 0 82s
prometheus-76b7745b64-gpdkw 1/1 Running 0 88s
servicegraph-cb9b94c-7sjks 1/1 Running 0 83s
从Pods状态中,如果有不是Running的,可以使用kubectl describe子命令查看详细状态,并找出错误原因。例如:kubectl -n istio-system describe pods istio-pilot。
基础软硬件环境在安装k8s的时候等于经过了验证,所以通常碰到的问题都是因为网络原因映像无法下载。Completed状态的一般是依赖包未能运行导致的退出,这种会自动尝试重启。或者是只需要安装时执行一次的容器。正常情况都不需要管。
Istio可能是发布时间尚短,国内没有能找到比较好的镜像,所以下载比较慢。我整理了一下需要的镜像列表,建议网络环境不理想的,在正式安装Istio之前,先使用root权限在Docker中完成镜像的下载,然后再执行上述安装。
docker pull docker.io/istio/proxy_init:1.0.6
docker pull docker.io/istio/proxyv2:1.0.6
docker pull quay.io/coreos/hyperkube:v1.7.6_coreos.0
docker pull docker.io/istio/galley:1.0.6
docker pull grafana/grafana:5.2.3
docker pull docker.io/istio/mixer:1.0.6
docker pull docker.io/istio/pilot:1.0.6
docker pull docker.io/prom/prometheus:v2.3.1
docker pull docker.io/istio/citadel:1.0.6
docker pull docker.io/istio/servicegraph:1.0.6
docker pull docker.io/istio/sidecar_injector:1.0.6
docker pull docker.io/jaegertracing/all-in-one:1.5
Istio的安装就这样两步,使用容器以来,软件的安装和配置变得越来越便利。
//顺便,在k8s环境中安装Istio之后,尝试列表所有的系统级Pods,也是很壮观的一坨
//不过在微服务的理念下,其实一个容器往往就是一个进程,总体耗费资源并不多
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
istio-system grafana-59b8896965-vlbd5 1/1 Running 2 17h
istio-system istio-citadel-6f444d9999-cz6gk 1/1 Running 2 17h
istio-system istio-egressgateway-6d79447874-gzssf 1/1 Running 2 17h
istio-system istio-galley-685bb48846-4f9qq 1/1 Running 1 16m
istio-system istio-ingressgateway-5b64fffc9f-lqjjv 1/1 Running 1 16m
istio-system istio-pilot-7f558fc848-mts8g 2/2 Running 2 16m
istio-system istio-policy-547d64b8d7-br5cn 2/2 Running 4 17h
istio-system istio-sidecar-injector-5d8dd9448d-ftsrr 1/1 Running 1 16m
istio-system istio-telemetry-c5488fc49-gpdx5 2/2 Running 2 16m
istio-system istio-tracing-6b994895fd-6hwqv 1/1 Running 2 17h
istio-system prometheus-76b7745b64-gpdkw 1/1 Running 2 17h
istio-system servicegraph-cb9b94c-7sjks 1/1 Running 4 17h
kube-system calico-node-sjdcg 2/2 Running 24 5d21h
kube-system coredns-78d4cf999f-pg4mn 1/1 Running 12 5d21h
kube-system coredns-78d4cf999f-zsh76 1/1 Running 12 5d21h
kube-system etcd-userver-master 1/1 Running 12 5d21h
kube-system kube-apiserver-userver-master 1/1 Running 13 5d21h
kube-system kube-controller-manager-userver-master 1/1 Running 15 5d21h
kube-system kube-proxy-fx42f 1/1 Running 12 5d21h
kube-system kube-scheduler-userver-master 1/1 Running 14 5d21h
kube-system kubernetes-dashboard-57df4db6b-5vmqk 1/1 Running 1 16m
Istio基本使用
上面说过,Istio的基本原理是在每个Pods中增加Sidecar来完成对Pods所有数据流量的代理,并以此来达成各项附加的功能。
所以在正式任务之前,我们先做一个设置,让k8s每次启动容器的时候,自动完成Istio Sidercar的注入,这样一来,我们原有的Pods配置文件,无需修改,自动就会得到Istio提供的各项功能:
kubectl label namespace default istio-injection=enabled
这一行就是为默认的default命名空间增加istio sidecard注入功能。如果希望为其它命名空间添加自动注入,把上面命令中的default换成你希望的命名空间的名字。
查看哪些命名空间打开了自动注入,可以使用命令:
kubectl get namespace -L istio-injection
单纯从命令行角度来看,使用Istio同使用基本的k8s似乎没有什么区别。
实际上Istio也是使用配置文件来启动容器。Istio在配置文件中,提供了大量自己特有的配置指令,从而提供服务网格的特征和功能。
作为对比,我们来看一个使用Istio启动容器的配置文件实例:
apiVersion: v1
kind: Service
metadata:
name: istio-dog
labels:
app: istio-dog
service: istio-dog
spec:
ports:
- port: 5678
name: http
selector:
app: istio-dog
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: istio-dog-v1
labels:
app: istio-dog
version: v1
spec:
replicas: 1
template:
metadata:
labels:
app: istio-dog
version: v1
spec:
containers:
- name: istio-dog
image: hashicorp/http-echo
args:
- "-text=istio-dog-v1"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5678
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: istio-dog-v2
labels:
app: istio-dog
version: v2
spec:
replicas: 1
template:
metadata:
labels:
app: istio-dog
version: v2
spec:
containers:
- name: istio-dog
image: hashicorp/http-echo
args:
- "-text=istio-dog-v2"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5678
---
apiVersion: v1
kind: Service
metadata:
name: istio-cat
labels:
app: istio-cat
service: istio-cat
spec:
ports:
- port: 5678
name: http
selector:
app: istio-cat
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: istio-cat-v1
labels:
app: istio-cat
version: v1
spec:
replicas: 1
template:
metadata:
labels:
app: istio-cat
version: v1
spec:
containers:
- name: istio-cat
image: hashicorp/http-echo
args:
- "-text=istio-cat-v1"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5678
Istio官方提供了Bookinfo示例作为入门教程,所有配套文档均有中文版,示例和文档写的都很棒。站在运维人员角度看,Bookinfo示例略显门槛偏高,所以我使用自己写的示例来演示、入门。
上面的配置文件中,定义了两个服务和三个Pod,其中istio-dog定义了两个版本。版本化是A/B测试和红黑发布的必须功能,也是我们前面说过的k8s的弱项。
Pod定义的部分,使用不一样的类型Deployment。实际上区别同Pod类型并不大,看起来应当不困难。服务部分,单纯从指令上跟前面k8s的示例没有区别,但是我们并没有定义服务类型比如NodePort。这是因为,我们使用的是Istio服务网格,虽然运行在k8s环境下,但并不需要k8s的网络代理功能。
前面说过,智能的流量控制是Istio第一大基本功能。理解并使用这一功能,需要先介绍一下做Istio流量控制的主要路径:
- 用户的访问,首先到达Istio的网关Gateway。Gateway配置4-6层的边缘接口,比如端口、TLS。这个配置为整个系统提供入口流量。
- 从Gateway出来,流量到达Istio的虚拟服务VirtualService。每一个VirtualService都必须绑定到一个Gateway来获取入口流量。虚拟服务根据配置的各项条件,在服务Service之间分拆流量。或者说,到达虚拟服务的流量,根据配置的各项条件,到达不同的服务。这里服务Service就是前面讲过的k8s服务,虽然是由Istio管理的,但是同一个东西。
- 服务相当于基本的负载均衡机制,对应到一组Pods的对外端口。这个同k8s相同。
- 流量从VirtualService到达Service之间,可以设置目标规则DestinationRule。目标规则在VirtualService之后生效。可以包含断路器、子版本特定规则、负载均衡策略、流量策略等更精细的控制手段。
- Service Entry:Istio 内部会维护一个服务注册表,可以用 ServiceEntry 向其中加入额外的条目。通常这个对象用来启用对 Istio 服务网格之外的服务发出请求。例如可以用来允许对 *.foo.com 域名上的服务主机的调用。
了解了这个机制,我们看一个网络设置的示例:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: istio-test-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: istio-test
spec:
hosts:
- "*"
gateways:
- istio-test-gateway
http:
- match:
- uri:
exact: /cat-and-dog
route:
- destination:
host: istio-dog
port:
number: 5678
配置文件中首先定义了一个Gateway,端口号80,特别注意一下其中的protocol指令,定义了HTTP协议。这一点跟k8s是有比较大的区别的,虽然你可能认为是理所当然的。原因是Istio是使用Sidecar全面代理作为核心来实现所有功能的,既然是代理,并且需要流经的数据进行解析,所以必然对可识别的协议类型是有限制的。这一点同k8s的端口映射实际有根本的区别。
配置文件中又定义了一个虚拟服务,从Gateway过来的流量中,如果路径匹配/cat-and-dog,则将流量导入到istio-dog服务。注意host容易让人误解,这里实际就是Service名,k8s中也是一样的。
我们把两个配置文件,分别保存为比如istio-test.yaml和istio-test-gateway1.yaml,然后执行来测试一下。
$ kubectl apply -f istio-test.yaml
service/istio-dog created
deployment.extensions/istio-dog-v1 created
deployment.extensions/istio-dog-v2 created
service/istio-cat created
deployment.extensions/istio-cat-v1 created
$ kubectl apply -f istio-test-gateway1.yaml
gateway.networking.istio.io/istio-test-gateway created
virtualservice.networking.istio.io/istio-test created
$ kubectl get VirtualServices
NAME AGE
istio-test 25s
$ kubectl get Gateways
NAME AGE
istio-test-gateway 3m
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
istio-cat-5fdcfd9fcd-bncmm 2/2 Running 0 3m57s
istio-dog-v1-657d697cd8-pdm7w 2/2 Running 0 3m57s
istio-dog-v2-69f6bb9dd8-wx8f7 2/2 Running 0 3m57s
//注意运行在Istio中的服务并不需要导出端口
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-cat ClusterIP 10.106.214.198 <none> 80/TCP 4m24s
istio-dog ClusterIP 10.106.22.195 <none> 80/TCP 4m24s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d
不同于k8s,Istio已经预先导出了80/443端口,这是由istio-ingressgateway服务来完成的:
$ kubectl get svc istio-ingressgateway -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.98.100.87 <pending> 80:31380/TCP,443:31390/TCP,31400:31400/TCP,15011:30050/TCP,8060:32063/TCP,853:31120/TCP,15030:30238/TCP,15031:30782/TCP 20h
通常80端口都是映射到31380,使用k8s的节点IP和31380端口就可以访问我们的测试应用。这个端口号可以通过修改istio-ingressgateway服务来修改。
为了体现我们的流量分配效果,我们再添加一个脚本文件,比如run100.sh:
#!/bin/sh
for i in `seq 100`;
do
curl 127.0.0.1:31380/cat-and-dog
done
执行测试脚本:
$ ./run100.sh
istio-dog-v2
istio-dog-v1
istio-dog-v2
istio-dog-v1
istio-dog-v1
istio-dog-v2
...略
我们并没有在虚拟服务中指定更详细的流量策略,所以两个istio-dog容器是分别提供服务的,基本各占50%流量。这个流量分配并不是虚拟服务提供的,而是基本Service。
我们再来看看另外一种配置方式:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: istio-test-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: istio-test
spec:
hosts:
- "*"
gateways:
- istio-test-gateway
http:
- match:
- uri:
exact: /dog
route:
- destination:
host: istio-dog
- match:
- uri:
exact: /cat
route:
- destination:
host: istio-cat
配置文件保存为istio-test-gateway2.yaml。在执行新的网络配置前,记着先删除掉旧的:
$ kubectl delete -f istio-test-gateway1.yaml
gateway.networking.istio.io "istio-test-gateway" deleted
virtualservice.networking.istio.io "istio-test" deleted
$ kubectl apply -f istio-test-gateway2.yaml
gateway.networking.istio.io/istio-test-gateway created
virtualservice.networking.istio.io/istio-test created
此时,访问根据路径不同,分配到两个不同的服务,再到3个Pods:
$ curl http://127.0.0.1:31380/dog
istio-dog-v2
$ curl http://127.0.0.1:31380/dog
istio-dog-v2
$ curl http://127.0.0.1:31380/dog
istio-dog-v1
$ curl http://127.0.0.1:31380/cat
istio-cat-v1
$ curl http://127.0.0.1:31380/cat
istio-cat-v1
再来看一个:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: istio-test-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: istio-test
spec:
hosts:
- "*"
gateways:
- istio-test-gateway
http:
- match:
- uri:
exact: /cat-and-dog
route:
- destination:
host: istio-dog
weight: 20
- destination:
host: istio-cat
weight: 80
保存配置到文件:istio-test-gateway3.yaml。删除上一版的配置,应用新的配置:
$ kubectl delete -f istio-test-gateway2.yaml
gateway.networking.istio.io "istio-test-gateway" deleted
virtualservice.networking.istio.io "istio-test" deleted
$ kubectl apply -f istio-test-gateway3.yaml
gateway.networking.istio.io/istio-test-gateway created
virtualservice.networking.istio.io/istio-test created
这次是使用权重值,分配到两个服务的流量比例,到istio-dog的是20%,到istio-cat的是80%。看一看测试的结果:
$ ./run100.sh
istio-cat-v1
istio-cat-v1
istio-dog-v1
istio-dog-v2
istio-cat-v1
istio-cat-v1
istio-cat-v1
istio-cat-v1
istio-cat-v1
istio-cat-v1
istio-dog-v1
istio-cat-v1
istio-cat-v1
istio-cat-v1
istio-dog-v2
...
好吧,我承认我故意误导了各位。其实apply子命令的真谛本身就在于对于同类型中同名的对象,比如我们上面定义的VirtualService中的istio-test。对于新的配置,在应用时并不需要删除原来的定义,k8s和Istio都会自动的更新配置。在这个过程中,对外的服务并没有中断。
因为有了这样的机制,才可以实现老版本、新版本并行运行,新版本测试结束后,直接取代老版本的服务完成升级这样的需求。
我这里每次都强调删除上一个配置,实际是强调,如果是两个不同的应用,前一个不使用了,记着一定要回收资源,并且避免端口冲突。
你可以试试直接应用另外一个配置文件来测试一下,感受一下不停机更新的快乐吧。
在容器内,访问其它容器的服务,同样是使用基于DNS的服务名称,比如:istio-cat.default.svc.cluster.local,这个跟k8s是完全一致的。
可以参考官方Bookinfo案例的python源码。安装Istio命令行时候的下载包中只有yaml配置文件,python程序的源码及Dockerfile源码需要到官方github仓库中检索。想要彻底了解运维、研发跟Istio的配合,建议读一读源码。作为示例性的源码,代码量很短,注释也比较全,非常便于理解。仓库地址:https://github.com/istio/istio/tree/master/samples/bookinfo/src
掌握了上面所说的概念,看过了本文中的示例,现在去看官方关于Bookinfo部分的教程不应当有问题了,建议及早开始,网址在本小节开始的部分给出了。
执行Bookinfo示例,因为网络原因,建议首先root状态使用docker提前下载映像文件。因为这种小众的映像,国内更是难以找到镜像网站,官方下载速度很慢:
docker pull istio/examples-bookinfo-details-v1:1.8.0
docker pull istio/examples-bookinfo-ratings-v1:1.8.0
docker pull istio/istio/examples-bookinfo-reviews-v1:1.8.0
docker pull istio/examples-bookinfo-reviews-v2:1.8.0
docker pull istio/examples-bookinfo-reviews-v3:1.8.0
docker pull istio/examples-bookinfo-productpage-v1:1.8.0
 在Istio安装的过程中,已经预置了Prometheus和Grafana指标可视化工具,使用Kubectl工具的端口转发功能把服务端口开放出来就可以使用,比如:
在Istio安装的过程中,已经预置了Prometheus和Grafana指标可视化工具,使用Kubectl工具的端口转发功能把服务端口开放出来就可以使用,比如:
$ kubectl -n istio-system port-forward $(kubectl -n istio-system get pod -l app=prometheus -o jsonpath='{.items[0].metadata.name}') --address 0.0.0.0 9090:9090 &
$ kubectl -n istio-system port-forward $(kubectl -n istio-system get pod -l app=grafana -o jsonpath='{.items[0].metadata.name}') --address 0.0.0.0 3000:3000 &
上面两条转发命令中的--address 0.0.0.0是为了把端口开放给节点主机之外的电脑来访问,因为通常节点服务器上不具备图形界面。但这也会带来安全性的问题,所以注意要使用完即时关闭。
这部分请参考官方文档:https://istio.io/zh/docs/tasks/telemetry/metrics/querying-metrics/
Istio在辅助调试方面,可以在流量中注入指定的错误信息、对数据包进行延迟、中断等,用于模拟实际故障发生的可能性,从而帮助研发人员、运维人员对系统进行优化。具体使用方法请参考官方文档。
监控功能和辅助调试同样也是借助了Sidecar对所有数据流的代理功能得以实现的。
在安全性方面,Istio主要是采用证书签名机制和TLS连接。支持TLS连接的版本,同本文中我们示例安装的版本不是同一个。如果有需求,请在Istio集群安装时就注意选择对应的配置文件来启动。详情请至官方文档学习。
Istio的使用实验中,每个配置实验完成,如果配置不再需要,记着使用kubectl delete -f xxx.yaml的方式来删除。因为不同于k8s的随机映射端口出来,Istio通常都使用默认导出的80或者443端口。这样不同配置之间忘记删除难免会造成冲突。这时候可以手工删除,可以参考一下Bookinfo中的 samples/bookinfo/platform/kube/cleanup.sh 脚本。基本做法是使用kubectl get遍历下面三类对象:
destinationrules virtualservices gateways,其中的内容全部删除。
在删除Pods的时候,视服务程序清理工作的任务不同,有些可能需要需要一些时间才可以退出,这时候可以使用Linux内置的watch工具来监控退出过程:
watch kubectl get pods
watch的退出是ctrl-c键。
结语
本文以用户需求的演进为导向,面向实际应用串讲了服务器端企业级运维的流行技术和流行概念。
重点介绍了Docker/k8s/Istio的安装、典型使用的入门。
水平所限,错误、疏漏在所难免,欢迎批评指正。
