TensorFlow从1到2(九)
迁移学习
![]()
迁移学习基本概念
迁移学习是这两年比较火的一个话题,主要原因是在当前的机器学习中,样本数据的获取是成本最高的一块。而迁移学习可以有效的把原有的学习经验(对于模型就是模型本身及其训练好的权重值)带入到新的领域,从而不需要过多的样本数据,也能达到大批量数据所达成的效果,进一步节省了学习的计算量和时间。
MobileNet V2是由谷歌在2018年初发布的一个视觉模型,在Keras中已经内置的并使用ImageNet完成了训练,可以直接拿来就用,这个我们在本系列第五篇中已经提过了。MobileNet V2有轻量和高效的特点。通过Inverted residual block结构,可以用较少的运算量得到较高的精度,很适合移动端的机器学习需求。论文在这里。
在ImageNet数据集上,MobileNet V2能达到92.5%的识别正确率。本篇中,我们以此模型为基础,介绍一个典型的迁移学习实现方法。并通过调整模型完成优化。
问题描述
MobileNet V2原本是识别图片中主题的名称。在ImageNet中,有大量的经过标注的照片,标注的信息也非常详细。比如我们熟悉的猫猫、狗狗,ImageNet并不简单的标注为cat或者dog,而是更详细的标注为加菲、德牧这样精确到具体品种的信息。
我们这里使用调整之后的MobileNet V2模型,用于对图片内容的猫猫和狗狗分类。不去管原本是哪种具体的品种,只分成cat/dog两个大类。
这个问题的描述实际上隐藏了两个重点:
- 迁移学习并不是无限制、随意实现的。原有学习数据和数据的场景,同当前的问题,是有共同点、可借鉴可迁移的。
- 把cat、dog的具体品种忽略,简单的分成两类,并不能认为就是把问题简化了。要知道人工智能并不是人,举例来说,其实机器学习模型自己,并不知道“藏獒”跟“狗”之间有什么关系。在机器学习的模型中,会认为这是两个不同的分类。
从简单开始,先展示一下识别
如同本系列第五篇一样,先使用最简短的代码熟悉一下MobileNet V2。
我们这个例子所使用的数据,是使用tensorflow_datasets模块来自动下载、解压、管理的。所以请先安装这个扩展包:
$ pip3 install tfds-nightly
程序在第一次运行的时候,会自动下载微软的实验数据集。请尽量使用程序自动下载,因为下载之后会自动解压。数据集的保存路径为:“~/tensorflow_datasets/”,这个是tensorflow_datasets默认的。
数据集中是随机尺寸的图片,程序第一步会将图片统一到224x224的尺寸,这个是预置的MobileNet V2模型所决定的。
我们从样本中取头两个图片显示在屏幕上,并且使用模型预测图片内容。请参考源代码中的注释阅读程序,也可以对照一下第五篇的vgg-19/ResNet50模型预测图片内容的程序,这些模型的使用方法几乎是相同的。
#!/usr/bin/env python3
# 引入所使用到的扩展库
from __future__ import absolute_import, division, print_function
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
keras = tf.keras
# 载入训练数据,载入时按照80%:10%:10%的比例拆分为训练、验证、测试三个数据集
# 本程序只是演示识别图片,区分为三类并没有直接意义,但下面的程序训练模型会使用到
SPLIT_WEIGHTS = (8, 1, 1)
splits = tfds.Split.TRAIN.subsplit(weighted=SPLIT_WEIGHTS)
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs', split=list(splits),
with_info=True, as_supervised=True)
# 图片标注
get_label_name = metadata.features['label'].int2str
# 显示头两幅图片
i = 1
plt.figure('Dog & Cat', figsize=(8, 4))
for image, label in raw_train.take(2):
plt.subplot(1, 2, i)
plt.imshow(image)
plt.title(get_label_name(label))
i += 1
plt.show()
# 所有图片转为224x224的尺寸,适应模型的要求
IMG_SIZE = 224
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
train = raw_train.map(format_example)
# 载入模型,第一次执行会下载h5文件
# 预测和迁移学习所用的模型并不完全相同,所以会下载两次
test_model = tf.keras.applications.MobileNetV2(weights='imagenet')
# 预测头两张照片并显示结果
for image, _ in train.take(2):
img = np.expand_dims(image, axis=0)
predict_class = test_model.predict(img)
desc = tf.keras.applications.mobilenet_v2.decode_predictions(predict_class, top=3)
print(desc[0])
我们执行程序看看预测结果:
$ ./cats_dogs_1predict.py
[('n02089078', 'black-and-tan_coonhound', 0.46141574), ('n02105412', 'kelpie', 0.15314996), ('n02106550', 'Rottweiler', 0.092713624)]
[('n02123045', 'tabby', 0.29928064), ('n02123159', 'tiger_cat', 0.08147916), ('n02096177', 'cairn', 0.047330838)]
程序准确的预测出了结果。
迁移学习改造
我们进行猫、狗分类训练,先了解一下样本集。样本集的图片没有什么区别,刚才我们见到了。标注则非常简单,就是1(代表Dog)或者0(代表Cat)。上面的程序中,我们使用get_label_name(label)将数字转换为可读的字符串。这个标注比ImageNet要简单的多。
MobileNet V2模型默认是将图片分类到1000类,每一类都有各自的标注。因为本问题分类只有两类,所以在代码上,我们构建模型的时候增加include_top=False参数,表示我们不需要原有模型中最后的神经网络层(分类到1000类),以便我们增加自己的输出层。当然这样在第一次执行程序的时候,需要重新下载另外一个不包含top层的h5模型数据文件。
随后我们在原有模型的后面增加一个池化层,对数据降维。最后是一个1个节点的输出层,因为我们需要的结果只有两类。
到了迁移学习的重点了,我们的基础模型的各项参数变量,我们并不想改变,因为这样才能保留原来大规模训练的优势,从而保留原来的经验。我们在程序中使用model.trainable = False,设置在训练中,基础模型的各项参数变量不会被新的训练修改数据。
接着我们把数据集分为训练、验证、测试三个数据集,用测试集数据和验证集数据对新的模型进行训练和过程验证。随后对完成训练的模型,使用测试集数据进行评估。
请看源代码:
#!/usr/bin/env python3
# 引入所使用到的扩展库
from __future__ import absolute_import, division, print_function
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
keras = tf.keras
# 载入训练数据,载入时按照80%:10%:10%的比例拆分为训练、验证、测试三个数据集
SPLIT_WEIGHTS = (8, 1, 1)
splits = tfds.Split.TRAIN.subsplit(weighted=SPLIT_WEIGHTS)
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs', split=list(splits),
with_info=True, as_supervised=True)
# cat/dog两类图片,复杂度要低于1000类的图片,所以分辨率可以略低,这样也能节省训练时间
# 所有图片重新调整为160x160点阵
IMG_SIZE = 160
def format_example(image, label):
image = tf.cast(image, tf.float32)
# 数据规范化为-1到+1的浮点数
image = (image/127.5) - 1
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
# 输入形状就是160x160x3,最后3为RGB3字节色
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False, # 使用不包含原有1000类输出层的模型
weights='imagenet')
# 设置基础模型:MobileNetV2的各项权重参数不会被训练所更改
base_model.trainable = False
# 输出模型汇总信息
base_model.summary()
# 增加输出池化层
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
# 输出层
prediction_layer = keras.layers.Dense(1)
# 定义最终完整的模型
model = tf.keras.Sequential([
base_model,
global_average_layer,
prediction_layer
])
# 学习梯度
base_learning_rate = 0.0001
# 编译模型
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss='binary_crossentropy',
metrics=['accuracy'])
# 各部分数据数量
num_train, num_val, num_test = (
metadata.splits['train'].num_examples*weight/10
for weight in SPLIT_WEIGHTS
)
# 迭代次数
initial_epochs = 10
steps_per_epoch = round(num_train)//BATCH_SIZE
# 验证和评估次数
validation_steps = 20
# 显示一下未经训练的初始模型评估结果
loss0, accuracy0 = model.evaluate(test_batches, steps=validation_steps)
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
# 训练
history = model.fit(train_batches.repeat(),
epochs=initial_epochs,
steps_per_epoch=steps_per_epoch,
validation_data=validation_batches.repeat(),
validation_steps=validation_steps)
# 评估
loss0, accuracy0 = model.evaluate(test_batches, steps=validation_steps)
print("Train1ed loss: {:.2f}".format(loss0))
print("Train1ed accuracy: {:.2f}".format(accuracy0))
因为数据集比较大,模型也比较复杂,所以程序执行起来时间很长。最终的评估结果类似为:
Train1ed loss: 0.38
Train1ed accuracy: 0.95
如果不对比来看,这个结果还不错啦。不过准确率比原来对更为复杂的ImageNet数据集的评估值还要低很多,显然还有很大的优化空间。
模型优化
在整个模型中,我们自己增加的部分很少,优化的余地并不多。考虑到原有ImageNet图片库的样本,大多并非猫和狗。所以完全保留原有的模型参数可能对MobileNet V2来讲也是资源上的浪费。
因此我们采取的优化策略就是开放一部分模型的网络层,允许在进一步的训练中,调整其权重值,从而期望更好的结果。
在MobileNet V2模型中,一共有155层卷积或者神经网络。这个值可以使用len(model.layers)来查看。我们仍然锁定前面的100层,把后面的网络层打开,允许训练修改其参数。
在随后新模型的训练中,也不需要全部重头开始训练,model.fit方法中,可以指定initial_epoch参数,接着前面的训练继续进行。
请看源代码:
...继续前面的代码最后输入...
# 打开允许修改基础模型的权重参数
base_model.trainable = True
# 仍然锁死前100层的权重不允许修改
fine_tune_at = 100
# 冻结fine_tune_at之前的层
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
# 重新编译模型
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate/10),
metrics=['accuracy'])
# 输出模型的概况,注意观察有些层被锁定,有些层可以更改
model.summary()
# 在前次训练的基础上再训练10次
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
# 训练模型
history_fine = model.fit(train_batches.repeat(),
steps_per_epoch=steps_per_epoch,
epochs=total_epochs,
initial_epoch=initial_epochs,
validation_data=validation_batches.repeat(),
validation_steps=validation_steps)
# 评估新模型
loss0, accuracy0 = model.evaluate(test_batches, steps=validation_steps)
print("final loss: {:.2f}".format(loss0))
print("final accuracy: {:.2f}".format(accuracy0))
执行优化后的程序,其中model.summary()的输出信息:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
mobilenetv2_1.00_160 (Model) (None, 5, 5, 1280) 2257984
_________________________________________________________________
global_average_pooling2d (Gl (None, 1280) 0
_________________________________________________________________
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,863,873
Non-trainable params: 395,392
Non-trainable params这一部分,就是指我们锁定不参与新数据训练的参数数量。如果你注意看前面一部分base_model.summary()的输出,所有的参数都被锁定不参与训练。
最后的评估结果为:
final loss: 0.23
final accuracy: 0.97
看起来虽然略好,但似乎优化效果并不明显。
其实这主要是观察数值不够直观造成的,我们继续为程序增加绘图功能:
...继续前面的代码最后输入...
# 优化前训练迭代数据
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 优化后训练迭代数据
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
# 使用训练数据绘图
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
我们为了讲解方便,把最终的程序分成了几个部分,实际上为了节省时间,是可以合并在一起执行的,这样不需要重复训练很多次。
从绘图结果看,优化的效果还是很明显的:
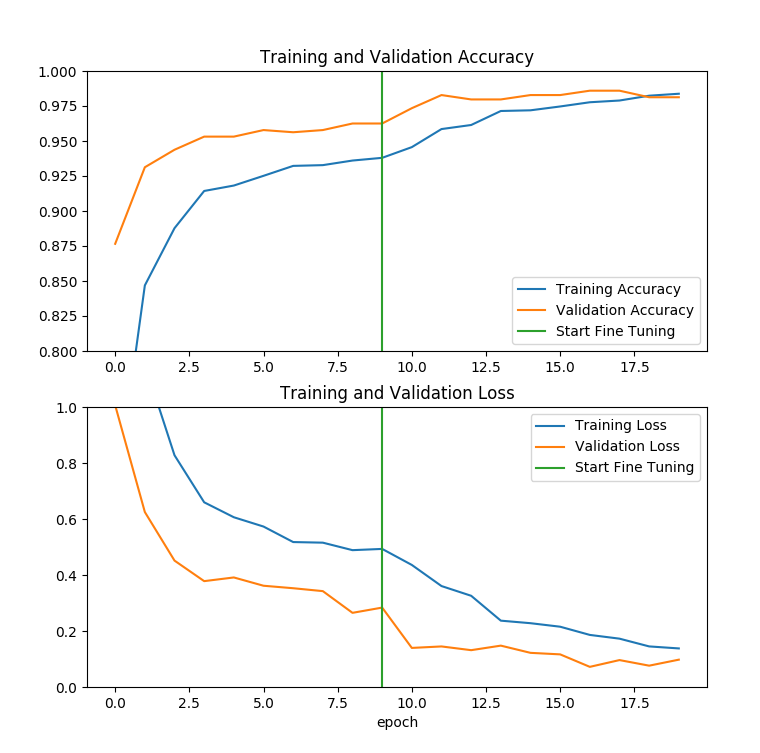
两张图,中间都有一条绿线分隔开优化前和优化后的训练数据。在前半段,正确率和损失值的优化过程是明显比较慢的,而且训练集和验证集两条线的分离也说明有过拟合的现象。在后半段,有一个明显的阶梯表现出来模型性能明显改善,训练集和验证集也更接近。说明各项指标都有效改善了。
(待续…)
