TensorFlow从1到2(十四)
评估器的使用和泰坦尼克号乘客分析
![]()
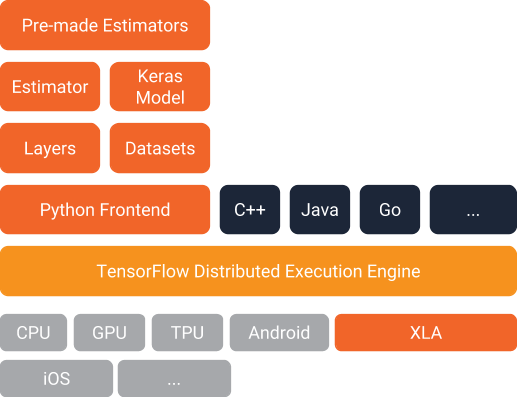
三种开发模式
使用TensorFlow 2.0完成机器学习一般有三种方式:
- 使用底层逻辑
这种方式使用Python函数自定义学习模型,把数学公式转化为可执行的程序逻辑。接着在训练循环中,通过tf.GradientTape()迭代,使用tape.gradient()梯度下降,使用optimizer.apply_gradients()更新模型权重,逐次逼近,完成模型训练。 - 使用Keras高层接口
TensorFlow 1.x的开发中,Keras就作为第三方库存在。2.0中,更是已经成为标准配置。我们前面大多的例子都是基于Keras或者自定义Keras模型配合底层训练循环完成。从网上的一些开源项目来看,这已经是应用最广泛的方式。 - 今天要介绍的评估器tf.estimator
评估器是TensorFlow官方推荐的内置高级API,层次上看跟Keras实际处于同样位置,只是似乎大家都视而不见了,以至于现在从用户的实际情况看用的人要远远少于Keras。
 通常认为评估器因为内置的紧密结合,运行速度要高于Keras。Keras一直是一个通用的高层框架,除了支持TensorFlow作为后端,还同时支持Theano和CNTK。高度的抽象肯定会影响Keras的速度,不过本人并未实际对比测试。我觉的,对于大量数据导致的长时间训练来说,这点效率上的差异不应当成为大问题,否则Python这种解释型的语言就不会成为优选的机器学习基础平台了。
通常认为评估器因为内置的紧密结合,运行速度要高于Keras。Keras一直是一个通用的高层框架,除了支持TensorFlow作为后端,还同时支持Theano和CNTK。高度的抽象肯定会影响Keras的速度,不过本人并未实际对比测试。我觉的,对于大量数据导致的长时间训练来说,这点效率上的差异不应当成为大问题,否则Python这种解释型的语言就不会成为优选的机器学习基础平台了。
在TensorFlow 1.x中可以使用tf.estimator.model_to_estimator方法将Keras模型转换为TensorFlow评估器。TensorFlow 2.0中,统一到了tf.keras.estimator.model_to_estimator方法。所以如果偏爱评估器的话,使用Keras也不会成为障碍。
评估器基本工作流程
其实从编程逻辑来看,这些高层API所提供的工作方式是很相似的。使用评估器开发机器学习大致分为如下步骤:
- 载入数据
- 数据清洗和数据预处理
- 编写数据流水线输入函数
- 定义评估器模型
- 训练
- 评估
在这个流程里面,只有“编写数据流水线输入函数”这一步是跟Keras模型是不同的。在Keras模型中,我们直接准备数据集,把数据集送入到模型即可。而在评估器中,数据的输入,需要指定一个函数供评估器调用。
使用评估器的实例
这一个来自官方文档的实例比较残酷,使用泰坦尼克号的乘客名单,评估在沉船事件发生后,客户能生存下来的可能性。
数据格式是csv,建议先下载,保存到工作目录:
训练集数据:https://storage.googleapis.com/tf-datasets/titanic/train.csv
评估集数据:https://storage.googleapis.com/tf-datasets/titanic/eval.csv
文件下载后不要修改名称。
数据包含如下属性维度:
| 属性名称 | 属性描述 |
|---|---|
| sex | 乘客性别 |
| age | 乘客年龄 |
| n_siblings_spouses | 随行兄弟或者配偶数量 |
| parch | 随行父母或者子女数量 |
| fare | 船费金额 |
| class | 船舱等级 |
| deck | 甲板编号 |
| embark_town | 登船地点 |
| alone | 是否为独自旅行 |
从这些属性中能看出,数据的收集者是非常用心的。
比如随行兄弟或者配偶、随行父母或者子女这种特征,在大多人的传统观念中,肯定会用类似“随行家属数量”这样的维度合并在一起。
但在这个案例中,两个不同的维度,对于最终存活影响肯定是不同的。
基本数据分析
这部分的工作其实跟评估器的使用没有什么关系,但这正是大数据时代的魅力所在,所以我们还是延续官方文档的思路来看一看。
先在命令行执行Python,启动交互环境。然后把下面这部分代码拷贝到Python执行。这些代码完成引用扩展库、载入数据等基本工作。
# 引入扩展库
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
# 载入数据
dftrain = pd.read_csv('train.csv')
dfeval = pd.read_csv('eval.csv')
# 分离标注字段
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
dftrain.head()
这时候命令行看起来大致是这个样子:
$ python3
Python 3.7.3 (default, Mar 27 2019, 09:23:39)
[Clang 10.0.0 (clang-1000.11.45.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> # 引入扩展库
... from __future__ import absolute_import, division, print_function, unicode_literals
>>>
>>> import numpy as np
>>> import pandas as pd
>>> import matplotlib.pyplot as plt
>>> import tensorflow as tf
>>>
>>> # 载入数据
... dftrain = pd.read_csv('train.csv')
>>> dfeval = pd.read_csv('eval.csv')
>>> # 分离标注字段
... y_train = dftrain.pop('survived')
>>> y_eval = dfeval.pop('survived')
>>>
>>> dftrain.head()
sex age n_siblings_spouses parch fare class deck embark_town alone
0 male 22.0 1 0 7.2500 Third unknown Southampton n
1 female 38.0 1 0 71.2833 First C Cherbourg n
2 female 26.0 0 0 7.9250 Third unknown Southampton y
3 female 35.0 1 0 53.1000 First C Southampton n
4 male 28.0 0 0 8.4583 Third unknown Queenstown y
>>>
最后是列出的训练集头5条记录。
我们先看看乘客的年龄分布(后续的代码都是直接拷贝到Python命令行执行):
dftrain.age.hist(bins=20)
plt.show()
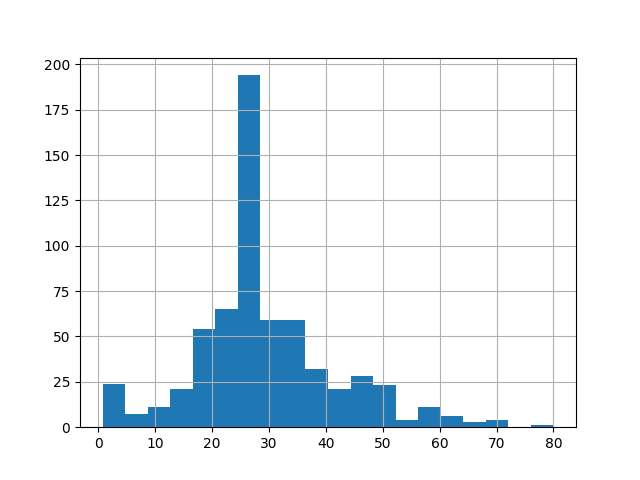 直方图中显示,乘客年龄主要分布在20岁至30岁之间。
直方图中显示,乘客年龄主要分布在20岁至30岁之间。
再来看看性别分布:
dftrain.sex.value_counts().plot(kind='barh')
plt.show()
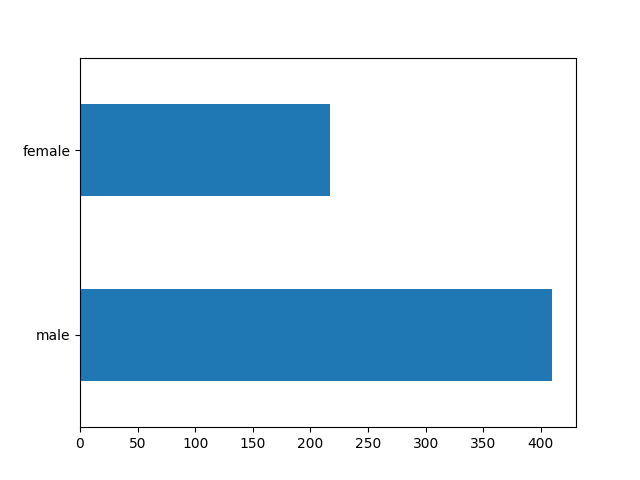 男性乘客的数量,几乎是女性乘客的两倍。
男性乘客的数量,几乎是女性乘客的两倍。
接着是船舱等级的分布,这个参数能间接体现乘客的经济实力:
dftrain['class'].value_counts().plot(kind='barh')
plt.show()
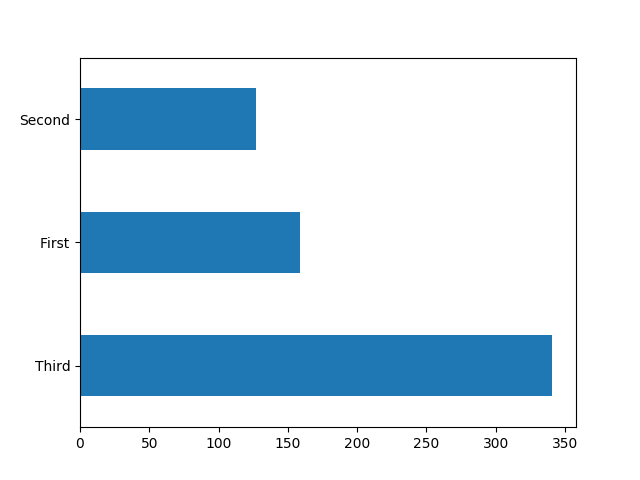 图中显示,大多数乘客还是在三等舱。
图中显示,大多数乘客还是在三等舱。
继续看乘客上船的地点:
dftrain['embark_town'].value_counts().plot(kind='barh')
plt.show()
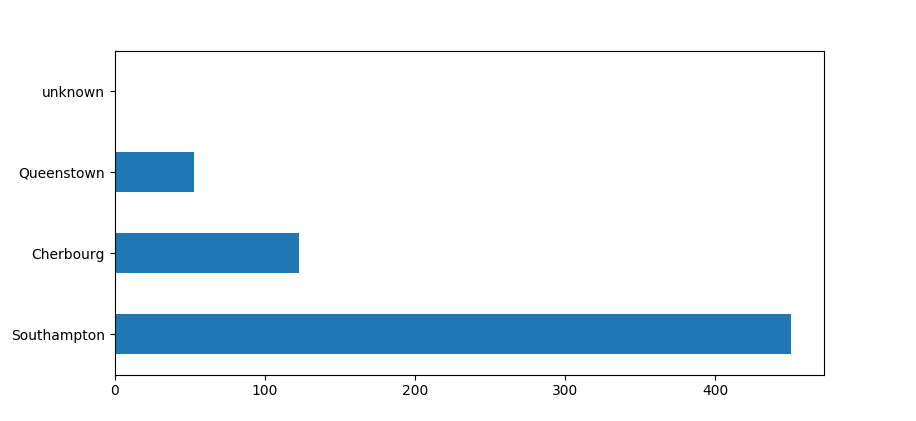 大多数乘客来自南安普顿。
大多数乘客来自南安普顿。
继续,把性别跟最后生存标注关联起来:
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
plt.show()
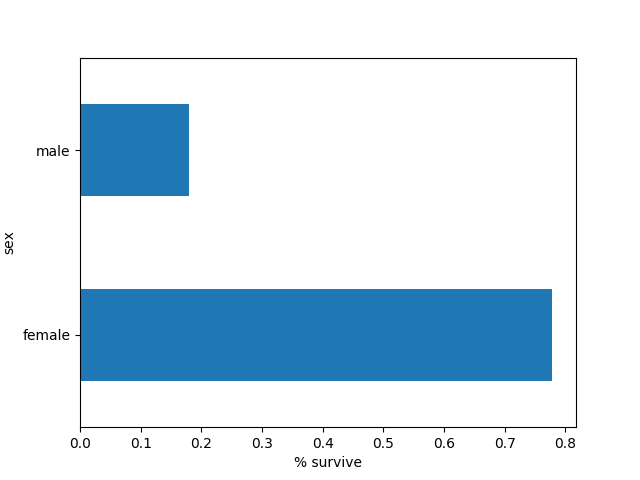 女性的存活率几乎超过男性的5倍。
女性的存活率几乎超过男性的5倍。
再来一个更复杂的统计,我们首先把年龄分段,然后看看不同年龄段的乘客最终存活率:
def calc_age_section(n, lim):
return'[%.f,%.f)' % (lim*(n//lim), lim*(n//lim)+lim) # map function
addone = pd.Series([calc_age_section(s, 10) for s in dftrain.age])
dftrain['ages'] = addone
pd.concat([dftrain, y_train], axis=1).groupby('ages').survived.mean().plot(kind='barh').set_xlabel('% survive');
plt.show()
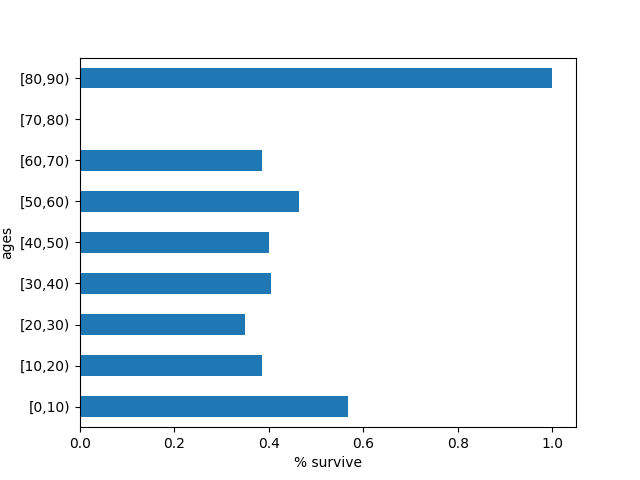 10岁以下儿童和80岁以上的老人得到了最多的生存机会。
10岁以下儿童和80岁以上的老人得到了最多的生存机会。
在那个寒冷、慌乱的沉船夜晚,弱者反而更多的活了下来。
数据的预处理
数据预处理这个话题我们讲了很多次,这是通常机器学习研发工作中,工程师需要做的最多工作。
泰坦尼克号乘客名单的数据虽然不复杂,也属于典型的结构化数据。
其中主要包含两类,一种是分类型的数据,比如船舱等级,比如上船城市名称。另一类则是简单的数值,比如年龄和购票价格。
对于数值型的数据可以直接规范化后进入模型,对于分类型的数据,则还需要做编码,我们这里还是使用最常见的one-hot。
# 定义所需的数据列,分为分类型属性和数值型属性分别定义
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
# 辅助函数,把给定数据列做one-hot编码
def one_hot_cat_column(feature_name, vocab):
return tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list(feature_name,
vocab))
# 最终使用的数据列,先置空
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
# 分类的属性都要做one-hot编码,然后加入数据列
vocabulary = dftrain[feature_name].unique()
feature_columns.append(one_hot_cat_column(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
# 数值类的属性直接入列
feature_columns.append(tf.feature_column.numeric_column(feature_name,
dtype=tf.float32))
数据输入函数
评估器的训练、评估都需要使用数据输入函数作为参数。输入函数本身不接受任何参数,返回一个tf.data.Dataset对象给模型用于供给数据。
因为除了数据集不同,训练和评估模型所使用的数据格式通常都是一样的。所以经常会在程序代码上,共用一个函数,然后用参数来区分用于评估还是用于训练。
然而输入函数相当于回调函数,由评估器控制着调用,这过程中并没有参数传递。所以比较聪明的做法可以使用嵌套函数的方法来定义,比如:
# 这是一个很少量数据的样本,直接把整个数据集当做一批
NUM_EXAMPLES = len(y_train)
# 输入函数的构造函数
def make_input_fn(X, y, n_epochs=None, shuffle=True):
def input_fn():
dataset = tf.data.Dataset.from_tensor_slices((dict(X), y))
# 乱序
if shuffle:
dataset = dataset.shuffle(NUM_EXAMPLES)
# 训练时让数据重复尽量多的次数
dataset = dataset.repeat(n_epochs)
dataset = dataset.batch(NUM_EXAMPLES)
return dataset
return input_fn
# 训练、评估所使用的数据输入函数,区别只是数据是否乱序以及迭代多少次
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)
模型和源码
本例中我们直接使用预定义的评估器模型(pre-made estimator)。所以代码非常简单,定义、训练、评估都是只需要一行代码:
# 使用线性分类器作为模型
linear_est = tf.estimator.LinearClassifier(feature_columns)
# 训练
linear_est.train(train_input_fn, max_steps=100)
# 评估
result = linear_est.evaluate(eval_input_fn)
我们来看看完整代码:
#!/usr/bin/env python3
# 引入扩展库
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
# 载入数据
dftrain = pd.read_csv('train.csv')
dfeval = pd.read_csv('eval.csv')
# 分离标注字段
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
################################################################
# 定义所需的数据列,分为分类型属性和数值型属性分别定义
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
# 辅助函数,把给定数据列做one-hot编码
def one_hot_cat_column(feature_name, vocab):
return tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list(feature_name,
vocab))
# 最终使用的数据列,先置空
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
# 分类的属性都要做one-hot编码,然后加入数据列
vocabulary = dftrain[feature_name].unique()
feature_columns.append(one_hot_cat_column(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
# 数值类的属性直接入列
feature_columns.append(tf.feature_column.numeric_column(feature_name,
dtype=tf.float32))
################################################################
# 这是一个很少量数据的样本,直接把整个数据集当做一批
NUM_EXAMPLES = len(y_train)
# 输入函数的构造函数
def make_input_fn(X, y, n_epochs=None, shuffle=True):
def input_fn():
dataset = tf.data.Dataset.from_tensor_slices((dict(X), y))
# 乱序
if shuffle:
dataset = dataset.shuffle(NUM_EXAMPLES)
# 训练时让数据重复尽量多的次数
dataset = dataset.repeat(n_epochs)
dataset = dataset.batch(NUM_EXAMPLES)
return dataset
return input_fn
# 训练、评估所使用的数据输入函数,区别只是数据是否乱序以及迭代多少次
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)
# 使用线性分类器作为模型
linear_est = tf.estimator.LinearClassifier(feature_columns)
# 训练
linear_est.train(train_input_fn, max_steps=100)
# 评估
result = linear_est.evaluate(eval_input_fn)
print("----------------------------------")
print(pd.Series(result))
程序执行的最后显示了评估的结果,在我的电脑上显示的结果是这样的:
----------------------------------
accuracy 0.765152
accuracy_baseline 0.625000
auc 0.832844
auc_precision_recall 0.789631
average_loss 0.478908
label/mean 0.375000
loss 0.478908
precision 0.703297
prediction/mean 0.350790
recall 0.646465
global_step 100.000000
正确率不算太高。
评估器的模型使用起来很简单,我们尝试换用另外一种模型,比如提升树分类器。
# 以下代码放在程序最后,因为这个数据集非常小,速度很快,所以做两次学习也并不感觉慢
n_batches = 1
est = tf.estimator.BoostedTreesClassifier(feature_columns,
n_batches_per_layer=n_batches)
# 训练
est.train(train_input_fn, max_steps=100)
# 评估
result = est.evaluate(eval_input_fn)
print("----------------------------------")
print(pd.Series(result))
这次得到的结果是这样的:
----------------------------------
accuracy 0.825758
accuracy_baseline 0.625000
auc 0.872360
auc_precision_recall 0.857325
average_loss 0.411853
label/mean 0.375000
loss 0.411853
precision 0.784946
prediction/mean 0.382282
recall 0.737374
global_step 100.000000
虽然准确率仍然并不高,但比起来线性分类器,提高还是算的上明显。
性能评价
评价机器学习模型的性能,除了看刚才的统计信息,绘图是非常好的一种方式,可以更直观,某些问题也能体现的一目了然。
我们在上面程序的最后再增加几行代码,绘制预测概率的统计信息:
# 绘制预测概率直方图
pred_dicts1 = list(linear_est.predict(eval_input_fn))
pred_dicts2 = list(bt_est.predict(eval_input_fn))
probs1 = pd.Series([pred['probabilities'][1] for pred in pred_dicts1])
probs2 = pd.Series([pred['probabilities'][1] for pred in pred_dicts2])
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
probs1.plot(kind='hist', bins=20, title='linear-est predicted probabilities');
plt.subplot(1, 2, 2)
probs2.plot(kind='hist', bins=20, title='bt-est predicted probabilities');
plt.show()
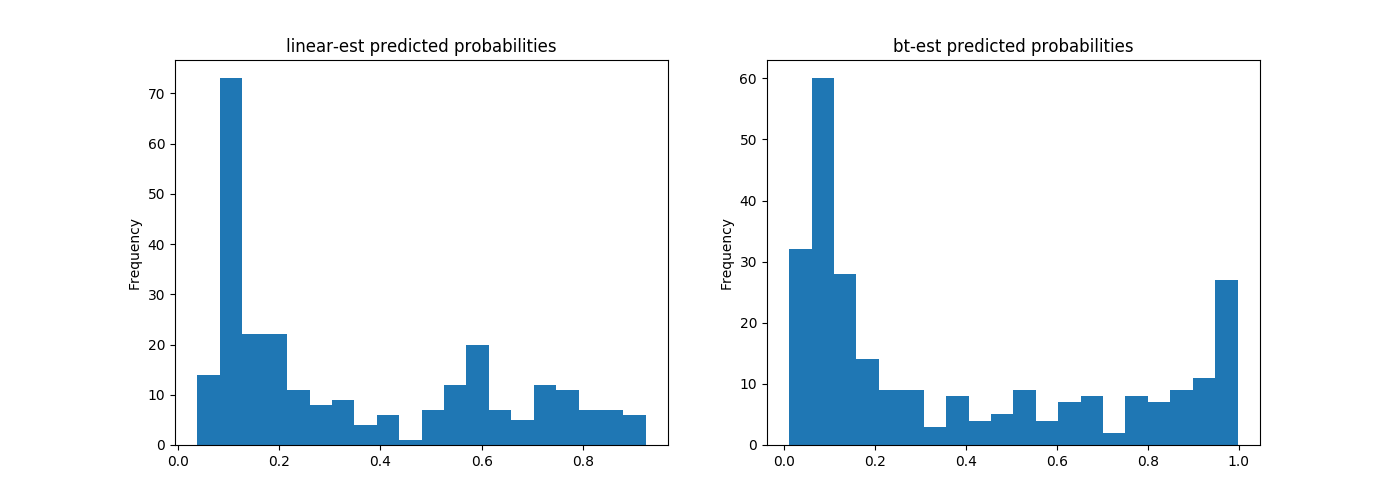 大量集中在图形左侧的数据簇,显示了乘客九死一生的悲惨命运。
大量集中在图形左侧的数据簇,显示了乘客九死一生的悲惨命运。
因为我们的预测结果只有两种可能:0表示未能生存;1表示生存下来。所以预测的结果,应当明显的尽量靠近0和1两端。中间悬而未决的部分应当尽可能少。从图形的情况看,如果不考虑分类准确率问题,提升树分类器效果要更好一些。
当然作为成熟的预定义模型,模型都是很优秀的,只是提升树可能更适合本应用的场景。
尽管这个例子很简单,但现在的分类算法实际越来越复杂。预测结果在不同类别数据上表现并不不均衡,使得使用正确率这样的传统标准不能恰当的反应分类器的性能,本例中也已经出现了这种倾向。或者说,分类器,对于不同类别的样本,性能表现是不一致的。
这种情况,使用ROC(Receiver Operating Characteristic)观察者操作曲线能够表现的更清楚。
对于一个分类器的分类结果,一般有以下四种情况:
- 真阳性(TP):判断为1,实际上也为1。
- 伪阳性(FP):判断为1,实际上为0。
- 真阴性(TN):判断为0,实际上也为0。
- 伪阴性(FN):判断为0,实际上为1。
ROC图中,左上角是真阳性的极点,曲线越接近左上角,意味着分类器性能越好。所以左上角是分类器追求的方向。
下面代码,请接续在上面代码之后,用来绘制ROC曲线:
# 绘制ROC(Receiver Operating Characteristic)曲线
from sklearn.metrics import roc_curve
def plot_roc(probs, title):
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title(title)
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
plot_roc(probs1, "linear-est ROC")
plt.subplot(1, 2, 2)
plot_roc(probs2, "bt-est ROC")
plt.show()
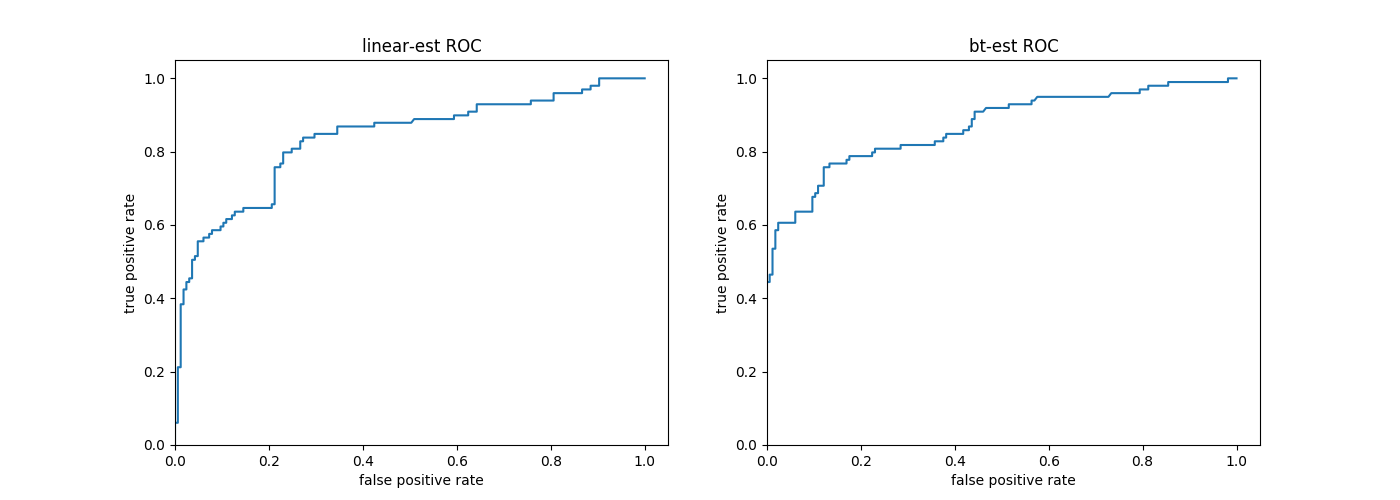 从ROC曲线看,在本例中使用提升树模型的优势更为明显。
从ROC曲线看,在本例中使用提升树模型的优势更为明显。
(待续…)
