从锅炉工到AI专家(8)
TensorFlow实务
ImageNet
基础部分完成,从本篇开始,会略微的增加一些难度。
通常说,在解决问题的时候,大多程序员都会在网上搜索,寻找一些相似相近的案例作为参考。这个方式在机器学习领域同样有效。可惜早期的时候,各公司的保密还是做的比较严格,时至今日有了很大改善,但在整个IT行业中,机器学习领域,各公司的研发成果保密仍然是最严重的。
因此,ImageNet对机器学习的推动更是难能可贵和功不可没。在机器学习尚处于摸索阶段,大家在都没有大规模投资的情况下艰苦研究的时候,ImageNet提供了一个迄今也是最大的已标注视觉大数据集,让个人即便在家里也可能把精力集中在算法和理论的研究。
ImageNet还连续举办了多届机器识别大赛,比赛结果一次次刷新机器学习识别纪录,最新的成绩已经超过人眼在图像识别方面的平均水平。诞生了很多优秀的算法或者模型。
诸如:LeNet、AlexNet、GoogLeNet、VGG、ResNet等模型,都已经通过大赛证明了自己的能力,并得到广泛的应用。
从这几个优胜算法的经验看,获奖的机器学习系统基本有这样几个特点:
- 大规模并准确标注的数据集用于训练、验证、测试
- 强悍的硬件,特别是有强劲的GPU帮助计算
- 更深的网络、更巧妙的网络组合及Dropout/ReLU算法的组合应用
今天以VGG为例完成一个图像识别的完整代码。这里的完整特别指不同于前几篇的学习中,使用已经归一化完成的图片,本次使用真实的图片文件进行识别。
vgg-19
VGG-19是2014年在ImageNet大赛中夺冠的算法,整体模型定义超过了19层的卷积及神经网络。下图是vgg系列网络的结构示意图:
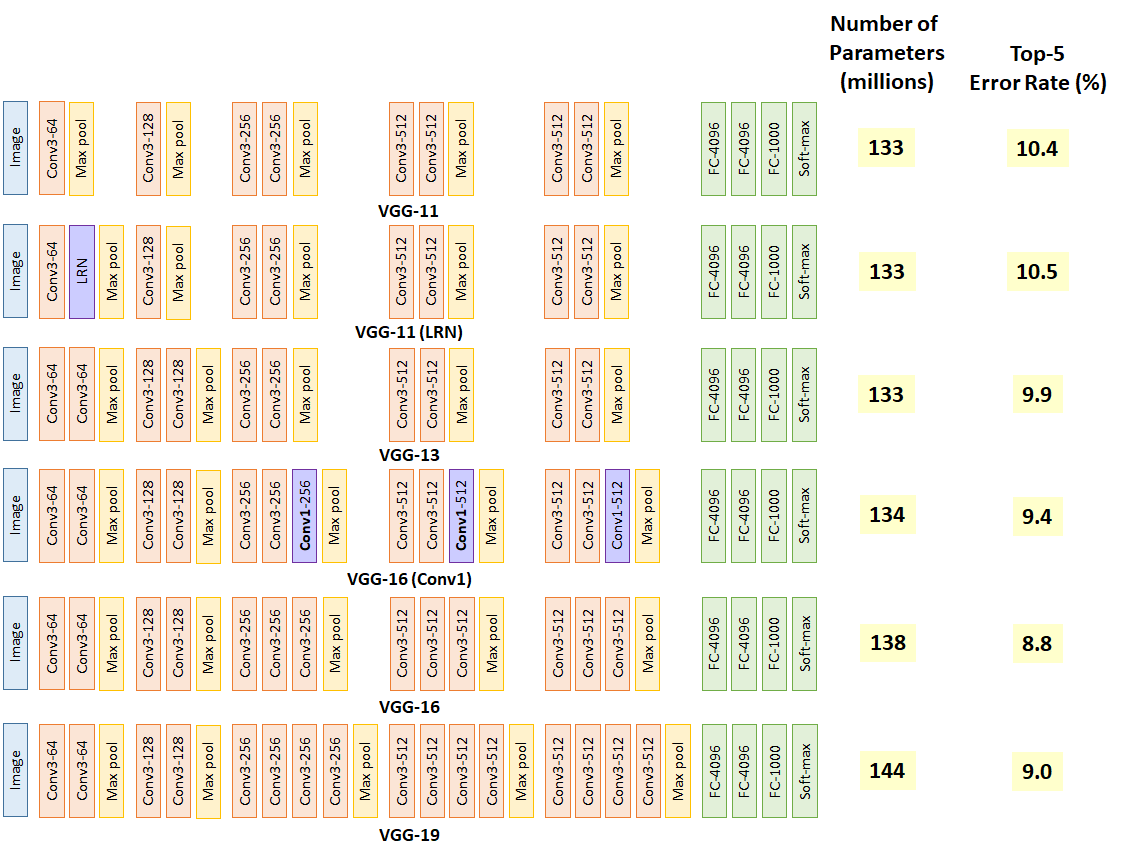
这里选择这个案例有三个原因:一是可以从上图看到,虽然模型很复杂,但没有超过我们现在掌握的基础算法,所有用到的算法我们都已经学过;二是这个复杂的模型完成ImageNet学习用时很长,但网上已经有完整的训练数据可以直接下载使用,从而大大的降低使用门槛。也就是说,我们搭建好模型,就可以用来对图片进行识别预测;三则是这是真正广泛应用的模型,在吻合的领域完全可以直接用于商用化。
训练数据下载:点击下载
分类标签下载:点击查看
两个文件下载后不要修改文件名,直接放置到./data/目录。
注意的准备事项
本篇的代码中又多用了一些第三方的扩展库需要在运行之前先安装,跟前面安装的newpy是一样的,可以使用pip安装:
pip2 install scipy pillow
先看源码
源文件分为两个文件,一个是vgg.py,用于实现vgg的模型,并且提供接口用于预测图片;另一个是主程序文件,用什么名字都没关系,我用的是picRegn.py。
vgg.py:
#这个程序相当于一个库,不会直接执行,
#所以开始没有用于脚本模式的标志
# -*- coding=UTF-8 -*-
import tensorflow as tf
import numpy as np
import scipy.io as sio
netmat_path = 'data/imagenet-vgg-verydeep-19.mat'
##定义卷积层
def _conv_layer(input, weight, bias):
conv = tf.nn.conv2d(input, tf.constant(weight), strides=(1, 1, 1, 1), padding='SAME')
return tf.nn.bias_add(conv, bias)
##定义池化层
def _pool_layer(input):
return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
##定义全链接层
def _fc_layer(input, weights, bias):
shape = input.get_shape().as_list()
dim = 1
for d in shape[1:]:
dim *= d
x = tf.reshape(input, [-1, dim])
fc = tf.nn.bias_add(tf.matmul(x, weights), bias)
return fc
##定义softmax分类输出层
def _softmax_preds(input):
preds = tf.nn.softmax(input, name='prediction')
return preds
##图片处里前减去均值(归一化的部分工作)
def _preprocess(image, mean_pixel):
return image - mean_pixel
##加均值,用于还原可显示图片
def _unprocess(image, mean_pixel):
return image + mean_pixel
##构建cnn前向传播网络
def net(data, input_image):
#根据vgg19的标准定义深层卷积网络
layers = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2',
'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2',
'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2',
'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4', 'pool5',
'fc6', 'relu6',
'fc7', 'relu7',
'fc8', 'softmax'
)
weights = data['layers'][0]
net = {}
current = input_image
#枚举所有的层
for i, name in enumerate(layers):
#取名字的前4个字母作为本层的类型
kind = name[:4]
#根据conv/relu/pool/soft这几种情况,调用对应函数定义相应层
#每次定义层以上一层的输出为输入,将整个网络连接起来
if kind == 'conv':
kernels, bias = weights[i][0][0][0][0]
kernels = np.transpose(kernels, (1, 0, 2, 3))
bias = bias.reshape(-1)
current = _conv_layer(current, kernels, bias)
elif kind == 'relu':
current = tf.nn.relu(current)
elif kind == 'pool':
current = _pool_layer(current)
elif kind == 'soft':
current = _softmax_preds(current)
#处理最后的全连接层
kind2 = name[:2]
if kind2 == 'fc':
kernels1, bias1 = weights[i][0][0][0][0]
kernels1 = kernels1.reshape(-1, kernels1.shape[-1])
bias1 = bias1.reshape(-1)
current = _fc_layer(current, kernels1, bias1)
net[name] = current
assert len(net) == len(layers)
return net, layers
def predict(image):
global data,mean_pixel
#统一减去均值
image_pre = _preprocess(image, mean_pixel)
#拉成数组
image_pre = np.expand_dims(image_pre, axis=0)
#转成浮点矩阵
image_preTensor = tf.to_float(tf.convert_to_tensor(image_pre))
#定义深度VGG19神经网络及载入图片数据用于预测
nets, layers = net(data, image_preTensor)
#取分类层数据
preds = nets['softmax']
#从分类转成整数的索引,
#实际上.eval才是真正开始tensorFlow计算,以前那么多工作都是在建模型
predsSortIndex = np.argsort(-preds[0].eval())
#返回预测数据
return predsSortIndex,preds
#载入训练好的矩阵文件,
#loadmat是载入matlab的数据数据文件
data = sio.loadmat(netmat_path)
mean = data['normalization'][0][0][0]
#获取图片像素均值用于图片的归一化
mean_pixel = np.mean(mean, axis=(0, 1))
picRegn.py:
#!/usr/bin/env python
# -*- coding=UTF-8 -*-
import vgg
import os,sys
import numpy as np
import scipy.misc
import tensorflow as tf
import argparse
FLAGS = None
##读取图片并把图片尺寸归一化
def _get_img(src, img_size=False):
img = scipy.misc.imread(src, mode='RGB')
if not (len(img.shape) == 3 and img.shape[2] == 3):
img = np.dstack((img, img, img))
if img_size != False:
img = scipy.misc.imresize(img, img_size)
return img.astype(np.float32)
##获取路径中文件列表
def list_files(in_path):
files = []
for (dirpath, dirnames, filenames) in os.walk(in_path):
files.extend(filenames)
break
return files
##获取文件路径列表dir+filename
def _get_files(img_dir):
files = list_files(img_dir)
return [os.path.join(img_dir, x) for x in files]
##获得图片的分类标签值
def _get_allClassificationName(file_path):
f = open(file_path, 'r')
lines = f.readlines()
f.close()
return lines
def main(_):
##加载ImageNet mat标签
lines = _get_allClassificationName('data/synset_words.txt')
images = _get_files(FLAGS.image_dir) ##获取图片路径中文件列表
with tf.Session() as sess:
for i, imgPath in enumerate(images):
##加载图片并压缩到标准格式=>224x224x3色
image = _get_img(imgPath, (224, 224, 3))
predsSortIndex,preds = vgg.predict(image)
print('#####%s#######' % imgPath)
for i in range(3): ##输出前3种分类
nIndex = predsSortIndex
classificationName = lines[nIndex[i]] ##分类名称
problity = preds[0][nIndex[i]] ##某一类型概率
print('%d.ClassificationName=%s Problity=%f' % ((i + 1), classificationName, problity.eval()))
sess.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-i','--image_dir', type=str, default='images/',
help='Pic files folder path')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
代码讲解
我们先从主程序讲起,因为主程序结构比较简单。
主程序定义了一个参数,如果运行时没有给定参数,默认从./images/文件夹列出所有文件,然后逐个识别。
程序首先读入了图片分类的标签库。与此对应已经训练好的vgg数据在vgg.py中读入,我们后面再讲。
接着程序列出文件夹中所有图片,逐个读入。读入的图片统一将尺寸变更为长宽均为224,颜色为RGB的图片(归一化)。
随后使用vgg算法识别给定的图片矩阵。返回值已经从分类变成了索引,使用索引在标签库中查找就可以得到图片所属的分类。程序会列出最相似的前三个分类及其相似度。
本例中所使用的图片就是在百度图片上随意搜索的,显示如下:

最后的执行结果为:
$ ./picRegn.py
#####images/leopard.jpeg#######
1.ClassificationName=n02128385 leopard, Panthera pardus
Problity=0.941652
2.ClassificationName=n02128925 jaguar, panther, Panthera onca, Felis onca
Problity=0.031439
3.ClassificationName=n02130308 cheetah, chetah, Acinonyx jubatus
Problity=0.024339
注意这个网络比较深,训练数据集也很大,因此执行这个程序建议至少是16G内存8核以上CPU,当然如果有GPU支持就更好了。
接着说重点vgg.py。
首先是全局部分,这部分在主程序一开头引入vgg包的时候就会执行。载入已经训练好的数据集,这个数据集实际是matlab/octave格式的,python可以很好的支持直接读入或者存储matlab数据集用于同其它项目共享资源。如同我们第二篇讲过的,至少迄今,matlab/octave还是学术界的主流研究方式。而机器学习算法的源头基本在学术界,也就是所谓“论文驱动”的研发模式。
随后根据训练数据集的情况得到其中使用的图片数据均值,这个均值用于在输入图片的时候也做相同的归一化动作。这样本幅图片同以前训练的结果集才具有可比较性,才谈得上用以前的训练结果识别本图片。
vgg.py最主要的函数是net,其它函数都是围绕这个函数而工作的。在这个函数中,首先完整定义一个vgg19的模型。这个定义跟我们以前用的方式非常不同。在我们以前学习的时候,因为结构比较简单,都是直接逐行的用命令进行模型的搭建。而在这个19层的网络中,用手工搭建已经太繁琐了,因此用了一个字符串数组layers,将模型以字符串的形式存入数组。然后循环遍历这个数组,根据该层名称调用相应的子程序定义相应层的算法。并将每一层的输入,定义为上一层的输出,从而将网络逐层关联在一起,最终完成完整的网络。
这种方法在复杂网络中会经常用到,目前我听说比较深的网络已经超过了1000层之多。这一篇里,这部分是学习的重点,学会了这个,你才能真正的在网上搜索成熟的算法、模型,并拿来应用。
vgg19的网络看上面展开的图反而不一定容易理解,我再转帖一张vgg-16网络的结构化示意图供参考(vgg-19网络除了层数其它基本类似):
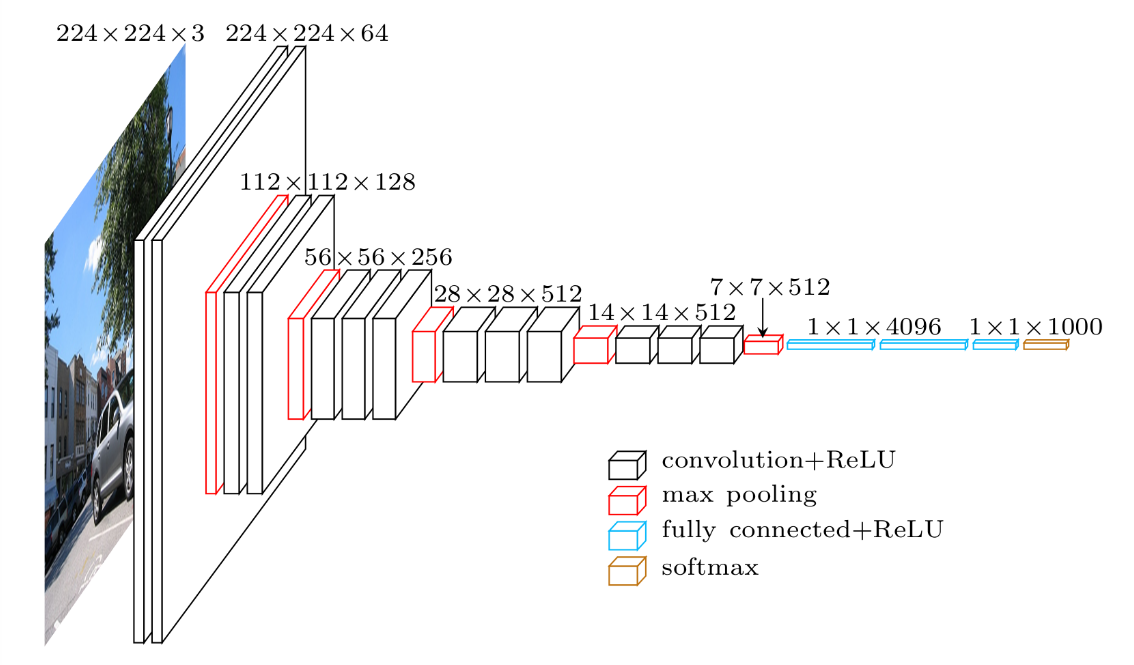
整个vgg包对外的接口实际上主要是使用函数:predict,这个函数接受一个参数,参数是一个224x224x3的图片矩阵。函数中会对图片统一减去均值,然后转换成张量(矩阵),并且全部变成浮点数据。随后送入刚才说过的net,用构建的网络对图片进行识别。
一个要注意的情况是,其实刚才说到的所有工作都只是对数据模型的描述、定义和组装。真正执行TensorFlow运算在下面preds[0].eval()这里,其实你看到evel()就应当明白了,我们前面的文章讲过,这里是使用当前默认的session来执行一个模型并返回结果。
同样是图像识别,用这个程序进行图像识别,跟使用百度之类的云API有什么区别吗?都学到第八篇了,这种区别无论如何你也应当能说得出来,不然我要伤心死了:)。云API是所有工作架构在云端,提供接口调用,按使用数量付费。使用这里的程序则是要自己搭建服务器,定义、实现接口,在自己的服务器上运行。如何取舍,其实不仅仅是技术问题,更重要是对于业务和企业战略的决策。
讲解就到这里,建议再多找几张图片样本,识别来试一试吧。
另一个脑洞
用作图像识别的深度卷机网络,还可以做一些很有意思的事情,这里就是一个例子。
《A Neural Algorithm of Artistic Style》,这篇论文认为,既然深度学习网络识别图片的主要理论依据,是找出图片的各项特征。那这些特征,同艺术品的绘画风格是否有共通性呢?随后证明的确是可行的。在这里有了一个完整的实现,用于将一副风格鲜明的艺术品:

以及一副普通的照片:

合成为一副风格相似的艺术作品:

可以看到,这种合成的水平,比平常的Photoshop滤镜效果可强太多了。当然,合成过程因为是机器学习过程,而不是简单的识别,所以运算拟合的过程,时间相当长。
源码有一点长,请直接移步到作者github网页去看,这里只做一个简单的讲解。
首先也是用vgg.py定义了vgg网络,因为本例中vgg网络不是用于识别的,所以取消了最后的3个全连接层、相关激活层还有softmax分类层。
vgg.py的代码对照我们上面的实现来读很容易理解,几乎都是相同的。所以这里补充一句,这一类的经典实现,保存到自己的代码库吧,就好像一把瑞士军刀,用的时候,拿出来简单改改就可以投产。
neural_style.py是主程序,主要定义和解析命令行参数,其中有大量的常量用于优化合成的效果。网上还有很多其它实现,但这个实现效果最好,跟这些复杂的参数有很大关系,因为显然作者使用这些配置灵活的参数已经进行了长时间的算法调优。主程序中其它的工作就是读写图片文件、基本的初始化性质的工作。
stylize.py是算法实现的主要部分,具体的实现如果有兴趣,建议先读一下论文,才能理解算法是如何实现的。
大概方法是:首先从隐藏层中抽出接近内容原图的隐藏层和接近风格图特征的隐藏层。如果你还记得前面第五篇mnist例子中我们将权重值可视化之后形成的图片,你就能大概理解这里抽取中间隐藏层的含义了。
然后使用vgg19网络分别抽取两张图片的特征,抽取的时候公式是不同的。在过程中,通过刚才说的指定的两组隐藏层来计算代价函数值,公式在论文中有。并以此代价值使用同样的反向传播算法拟合风格图及内容图的抽象部分(隐藏层部分)。随后在完成1000次的拟合之后,使用算法完成两张图的合成图(结果图片),最终合成图同时最接近风格图片以及内容原图。从而得到一张艺术品化的照片。
合成的算法在源码中有英文的解释,大致分成五步:
- 使用特定公式将提取的风格矩阵的RGB格式转为灰度图;
- 将灰度图再转为YUV格式;
- 原图提取的特征矩阵从RGB转换为YUV;
- 使用风格矩阵的Y部分,原图特征矩阵的U和V部分,重新组合为一张新图;
- 将新图转回RGB,作为结果输出。补充一点,RGB分别代表红、绿、蓝应当大家都知道了,YUV分别代表Y(亮度)、及U/V两种(色度)信号。
下面的引文中有一篇稍微详细的用中文解释了一下这个算法,但是主要的部分还是建议你读英文论文。
其它的同类算法
本篇开始说了其它一些同样获奖的算法,比如LeNet、AlexNet、GoogLeNet、ResNet,但是因为理解起来可能不如vgg-19方便,所以没在这里介绍。
但这些算法同样非常优秀,后来的获奖者更是超出vgg很多。这些可以在网上搜索实现代码,也有一些优秀的实现直接用pip就可以找到,可以用pip2 search tensorflow搜索,因为使用tensorflow实现的算法一般都会有tensorflow的关键字标签。
这种类型的算法基本上掌握了机器学习的基本理念,直接上手使用就好。具体实现原理,有兴趣就找论文读一读,没兴趣就当做黑盒来使用就好。
(待续…)
引文及参考
使用Imagenet VGG-19模型进行图片识别
使用tensorflow实现VGG19网络
CNN的发展史
vgg model
深入理解Neural Style
