NMF学习练习:做电影推荐
Non-negative Matrix Factorization
 NMF是很久以前学的,基本快忘没了,昨天YX提出来一个关于NMF(同音同字不同义)的问题,才又想起来。
NMF是很久以前学的,基本快忘没了,昨天YX提出来一个关于NMF(同音同字不同义)的问题,才又想起来。
自己的学习笔记写的比较乱,好在网上资料多,摘了一篇,补充上自己笔记的内容,留此助记。
NMF概念出现的比较早,差不多在电脑还没有开始繁荣起来,NMF及相关的一些算法已经很成熟了。NMF用在电影推荐、商品推荐也并不是很适合,现在大多使用SVD之类的算法。不过这篇只是学习的记录,有个例子总比枯燥的啃概念好的多。
场景
让我们假设一个场景。
相像当前这个档期,有10部电影正在上映,我们把它们放到一个数组中:
item = [
'希特勒回来了', '死侍', '房间', '龙虾', '大空头',
'极盗者', '裁缝', '八恶人', '实习生', '间谍之桥',
]
放入数组这个动作,等于也把这些电影编了号,从0到9,比如电影《实习生》,编号就是8。
随后我们继续假设我们影院有15个老顾客,同样把它们放置到一个数组:
user = ['五柳君', '帕格尼六', '木村静香', 'WTF', 'airyyouth',
'橙子c', '秋月白', 'clavin_kong', 'olit', 'You_某人',
'凛冬将至', 'Rusty', '噢!你看!', 'Aron', 'ErDong Chen']
他们的编号是0-14。
接着从用户的观影记录中,我们提取每个用户,对每部电影的打分记录。以电影序号为行号,以用户编号为列号,形成一个矩阵:
RATE_MATRIX = np.array(
[[5, 5, 3, 0, 5, 5, 4, 3, 2, 1, 4, 1, 3, 4, 5],
[5, 0, 4, 0, 4, 4, 3, 2, 1, 2, 4, 4, 3, 4, 0],
[0, 3, 0, 5, 4, 5, 0, 4, 4, 5, 3, 0, 0, 0, 0],
[5, 4, 3, 3, 5, 5, 0, 1, 1, 3, 4, 5, 0, 2, 4],
[5, 4, 3, 3, 5, 5, 3, 3, 3, 4, 5, 0, 5, 2, 4],
[5, 4, 2, 2, 0, 5, 3, 3, 3, 4, 4, 4, 5, 2, 5],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]
)
从矩阵中,我们可以得到这样几个信息:
- 评分是5分制。
- 用户打分是有个人特点的,比如第一列的用户,也就是“五柳君”,喜欢给电影打5分,:),真是个心宽的家伙。
- 用户没有打分的电影,给分就是0。(通常不会出现真的给某部电影打0分的情况)。
分类
我们使用NMF为电影进行主题分类。
这是一个非常典型的非监督学习方式,也就是我们并不指定主题是什么,只知道主题一定是存在的,因此一定会有两个典型的倾向:
- 任何一部电影,必然倾向某一种或者几种主题。
- 任意一位观众,必然喜爱某一种或者几种主题。
这里的理解重点是在非监督学习中,我们并不指定主题是什么,但只要你联想一下实际情况就容易理解了,比如可能是“爱情”主题,或者“枪战”主题。
下面代码将使用NMF设定2个关注主题,并通过分类,将电影分类为倾向主题1或者主题2的两类。同时将用户分为喜爱主题1或者喜爱主题2两个分类。
nmf_model = NMF(n_components=2) # 设有2个主题
item_dis = nmf_model.fit_transform(RATE_MATRIX)
user_dis = nmf_model.components_
print('用户的主题分布:')
print(user_dis)
print('电影的主题分布:')
print(item_dis)
使用上面的数据集,会得到如下结果:
用户的主题分布:
[[0.81240799 0.71153396 0.47062388 0.43807017 1.39456425 2.24323719
1.02417204 1.25356481 1.10517661 1.47624595 1.84626347 0.97437242
1.14921406 0.8159644 1.14200028]
[2.23910382 1.70186882 1.34300272 1.09192602 0.68045441 0.
0.0542231 0. 0. 0. 0.04426552 0.12260418
0.34109613 0.51642843 0.6157604 ]]
电影的主题分布:
[[2.20401687 1.53852775]
[1.9083879 0.83214869]
[1.95596132 0. ]
[1.87637018 1.65573674]
[2.48959328 1.41632377]
[2.38108536 1.08460665]
[0. 2.29342959]
[0. 2.27353353]
[0. 2.32513876]
[0. 2.23196277]]
这些数据非常不利于观察理解。它们代表的概念是,比较接近的值,代表该影片或者该观众属于(或说喜爱)比较接近的主题。
数据可视化
为了观察起来更直观,可以使用绘图的代码把数据显示出来,从而更形象的理解“聚类”。
#显示电影的坐标分布
plt1 = plt
plt1.plot(item_dis[:, 0], item_dis[:, 1], 'ro')
plt1.draw()#直接画出矩阵,只打了点,下面对图plt1进行一些设置
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of items (NMF)')#设置图的标题
count = 1
zipitem = zip(item, item_dis)#把电影标题和电影的坐标联系在一起
for item in zipitem:
item_name = item[0]
data = item[1]
plt1.text(data[0], data[1], item_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')
plt1.show()
#显示用户的坐标分布
user_dis = user_dis.T #把转置用户分布矩阵
plt2 = plt
plt2.plot(user_dis[:, 0], user_dis[:, 1], 'ro')
plt2.xlim((-1, 3))
plt2.ylim((-1, 3))
plt2.title(u'the distribution of user (NMF)')#设置图的标题
zipuser = zip(user, user_dis)#把电影标题和电影的坐标联系在一起
for user in zipuser:
user_name = user[0]
data = user[1]
plt2.text(data[0], data[1], user_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')
plt2.show()#直接画出矩阵,只打了点,下面对图plt1进行一些设置
以上代码会得到两张图,电影主题分布:
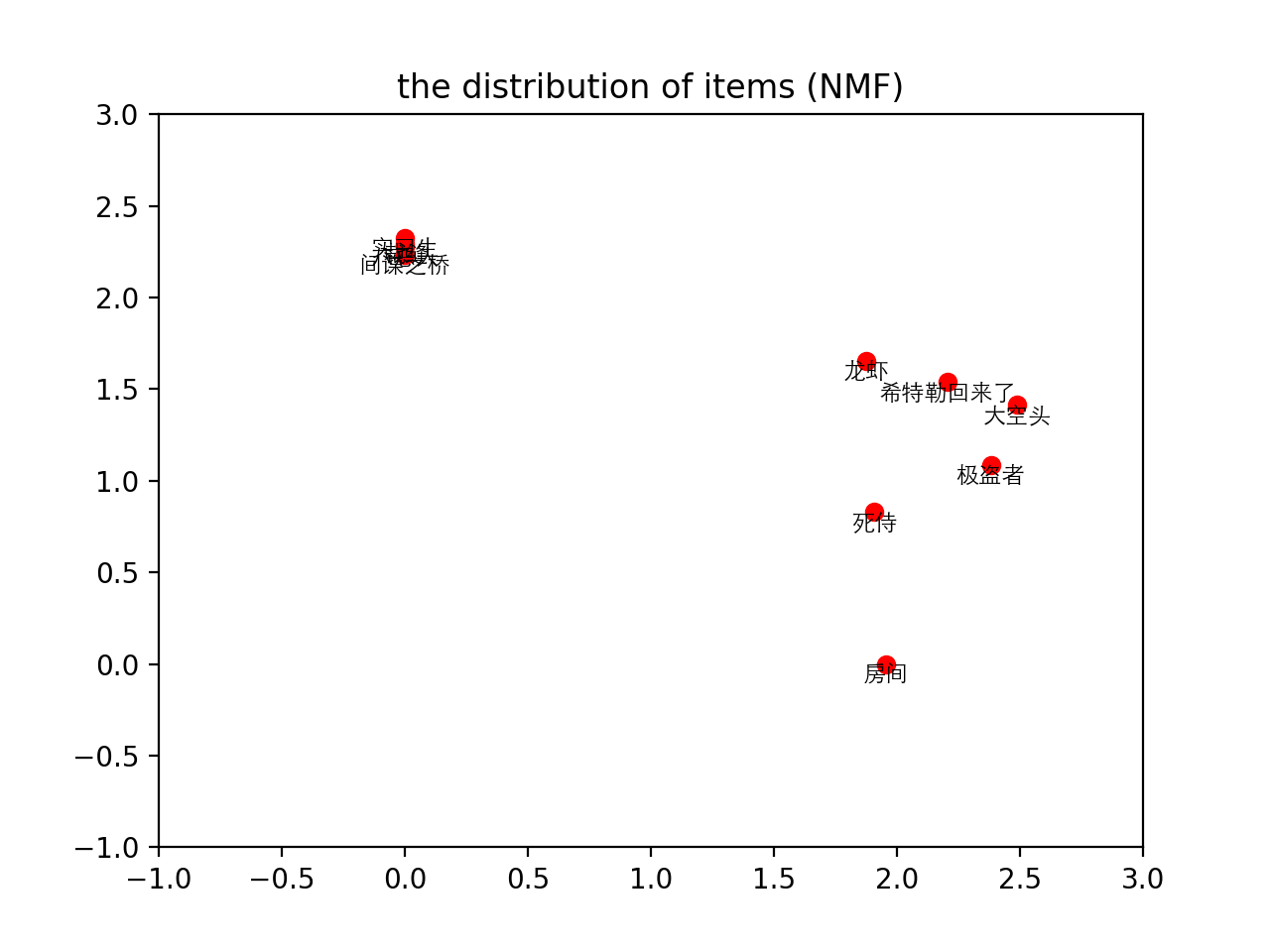 用户倾向主题分布:
用户倾向主题分布:
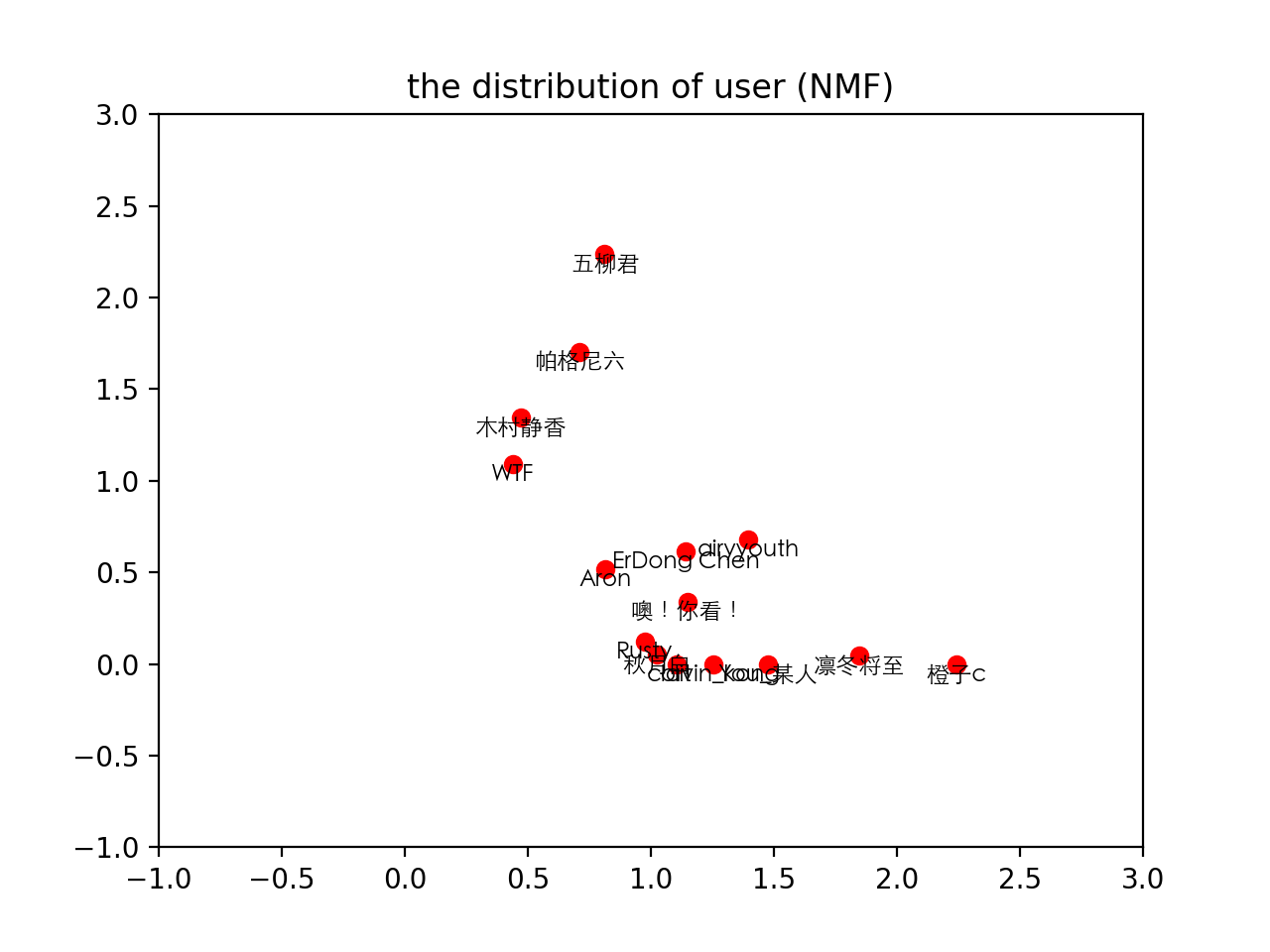 从图中可以看到,我们分类比较少,数据也不是很准确,导致分布偏差比较大,但基本上是分成两类的。
从图中可以看到,我们分类比较少,数据也不是很准确,导致分布偏差比较大,但基本上是分成两类的。
电影推荐
采用这种方式,我们指定一个用户名,则可以为该用户推荐他倾向主题的电影。
本例中的数据偏差比较大,所以计算的结果有点没有说服力,仅供参考。
filter_matrix = RATE_MATRIX < 1e-8
rec_mat = np.dot(item_dis, user_dis)
print('重建矩阵,并过滤掉已经看过的电影')
rec_filter_mat = (filter_matrix * rec_mat).T
print(rec_filter_mat)
rec_user = 'Rusty' # 需要进行推荐的用户
rec_userid = user.index(rec_user) # 推荐用户ID
rec_list = rec_filter_mat[rec_userid, :] # 推荐用户的电影列表
print('推荐用户的电影:')
print(np.nonzero(rec_list))
执行结果:
(array([2, 4, 6, 7, 8, 9]),)
完整代码
上面为了叙述方便,打散、简化并且省略了一些代码。下面是完整的代码,并且因为XJ同学的课程要求,使用了python3代码。嗯,python3对于中文的支持的确好了很多哈。
#!/usr/bin/env python3
#pip3 install sklearn scipy numpy matplotlib
from sklearn.decomposition import NMF
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
item = [
'希特勒回来了', '死侍', '房间', '龙虾', '大空头',
'极盗者', '裁缝', '八恶人', '实习生', '间谍之桥',
]
user = ['五柳君', '帕格尼六', '木村静香', 'WTF', 'airyyouth',
'橙子c', '秋月白', 'clavin_kong', 'olit', 'You_某人',
'凛冬将至', 'Rusty', '噢!你看!', 'Aron', 'ErDong Chen']
RATE_MATRIX = np.array(
[[5, 5, 3, 0, 5, 5, 4, 3, 2, 1, 4, 1, 3, 4, 5],
[5, 0, 4, 0, 4, 4, 3, 2, 1, 2, 4, 4, 3, 4, 0],
[0, 3, 0, 5, 4, 5, 0, 4, 4, 5, 3, 0, 0, 0, 0],
[5, 4, 3, 3, 5, 5, 0, 1, 1, 3, 4, 5, 0, 2, 4],
[5, 4, 3, 3, 5, 5, 3, 3, 3, 4, 5, 0, 5, 2, 4],
[5, 4, 2, 2, 0, 5, 3, 3, 3, 4, 4, 4, 5, 2, 5],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]
)
nmf_model = NMF(n_components=2) # 设有2个主题
item_dis = nmf_model.fit_transform(RATE_MATRIX)
user_dis = nmf_model.components_
print('用户的主题分布:')
print(user_dis)
print('电影的主题分布:')
print(item_dis)
filter_matrix = RATE_MATRIX < 1e-8
rec_mat = np.dot(item_dis, user_dis)
print('重建矩阵,并过滤掉已经评分的物品:')
rec_filter_mat = (filter_matrix * rec_mat).T
print(rec_filter_mat)
rec_user = 'Rusty' # 需要进行推荐的用户
#rec_user = '凛冬将至' # 需要进行推荐的用户
rec_userid = user.index(rec_user) # 推荐用户ID
rec_list = rec_filter_mat[rec_userid, :] # 推荐用户的电影列表
print('推荐用户的电影:')
print(np.nonzero(rec_list))
######################################################################
fontP = FontProperties(fname="/System/Library/Fonts/STHeiti Light.ttc")
fontP.set_size('small')
plt1 = plt
plt1.plot(item_dis[:, 0], item_dis[:, 1], 'ro')
plt1.draw()#直接画出矩阵,只打了点,下面对图plt1进行一些设置
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of items (NMF)')#设置图的标题
count = 1
zipitem = zip(item, item_dis)#把电影标题和电影的坐标联系在一起
for item in zipitem:
item_name = item[0]
data = item[1]
plt1.text(data[0], data[1], item_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')
plt1.show()
user_dis = user_dis.T #把转置用户分布矩阵
plt2 = plt
plt2.plot(user_dis[:, 0], user_dis[:, 1], 'ro')
plt2.xlim((-1, 3))
plt2.ylim((-1, 3))
plt2.title(u'the distribution of user (NMF)')#设置图的标题
zipuser = zip(user, user_dis)#把电影标题和电影的坐标联系在一起
for user in zipuser:
user_name = user[0]
data = user[1]
plt2.text(data[0], data[1], user_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')
plt2.show()#直接画出矩阵,只打了点,下面对图plt1进行一些设置
特别感谢,代码及数据转自:NMF 非负矩阵分解(Non-negative Matrix Factorization)实践。
