TensorFlow从1到2(十二)
生成对抗网络GAN和图片自动生成
![]()
生成对抗网络的概念
上一篇中介绍的VAE自动编码器具备了一定程度的创造特征,能够“无中生有”的由一组随机数向量生成手写字符的图片。
这个“创造能力”我们在模型中分为编码器和解码器两个部分。其能力来源实际上是大量样本经过学习编码后,在数字层面对编码结果进行微调,再解码生成图片的过程。所生成的图片,是对原样本图的某种变形模仿。
今天的要介绍的生成对抗网络(GAN)也具备很类似的功能,所建立的模型,能够生成非常接近样本图片的结果。
相对于VAE,生成对抗网络GAN更接近一种思想,并非针对机器视觉领域,而是一种很通用的机器学习理念。
让我们用一个例子来理解生成对抗网络:
比如我们想学习英语朗读。一开始,我们的朗读能力肯定很差,每次考试都是不及格。这时候,我们会努力的学习。当然人的学习是通过各种可能手段,听录音、看视频、找外教。学习一段时间后,再去参加考试,如果成绩依然很差,我们回来继续学习。一直到我们得到了一个自己满意的成绩。
这个例子中有几个重要的因素:学习者本人就是机器学习中的神经网络,负责生成某个结果,比如朗读;考官负责判断我们朗读的英语是否达到了水平要求。考官实际也是一个网络模型,本身并不能知道什么样的朗读叫好,什么样的朗读叫差,其判断依据来自于对“好的朗读”样本的学习;学习者不断学习提高的过程,这个就相当于网络模型不断的训练迭代。
回到我们的图片生成过程。图片生成是一个模型,负责生成所需要的图片;
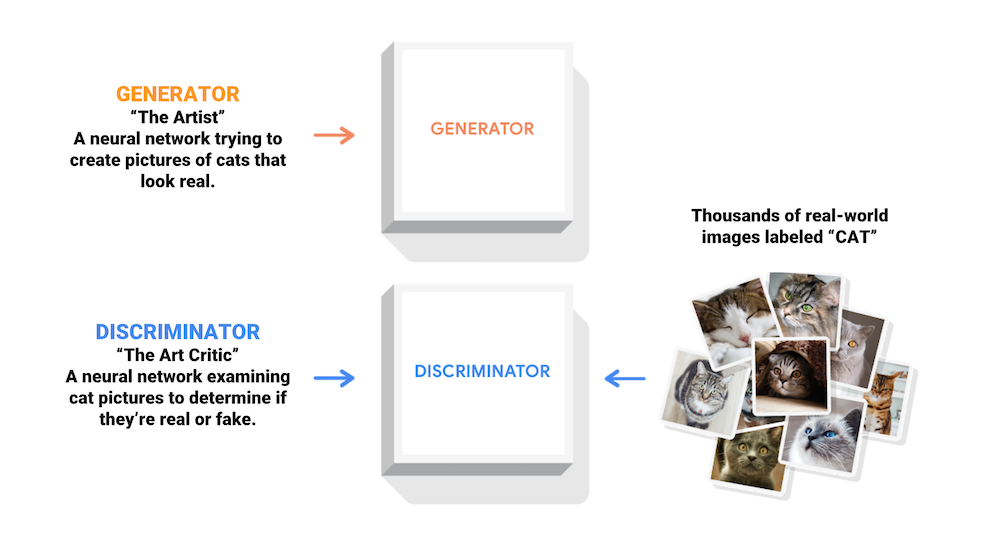
(图片来自官方文档)
“考官”负责检查样本和生成图。这里有一个区别于VAE模型的重点,VAE是直接比较样本和生成图,以两者的差距作为代价。
而GAN中,考官本身的学习,自动为样本图添加标注1,为生成图添加标注0。完成学习后,如果生成的图片,考官会判断为真实样本,说明所生成的图片达到了应有的水准。
(图片来自官方文档)
这样的机器学习方式,可以不使用经过标注的样本数据,能够大量节省成本。虽然会带来学习过程的加长和大量算力需求,但通常来说,算力还是更容易获得的。
另一个角度上说,VAE直接比较样本图片和生成图片,大量的数据和复杂性,导致VAE的损失函数的代码量大,计算速度也慢。GAN只有真、伪两个判断结果,模型输出简单,代价函数也容易的多。所以在同一组数据上,使用VAE算法往往会比GAN略慢一些。
看起来如果只是生成图片这一个维度的结果,GAN似乎更有优势,但如果考虑到输出结果的可控性等因素,VAE在机器视觉领域的应用仍然是很广泛。
不过GAN的思想是比较判断结果而非原图,是“裁判”,所以这种思想很容易推广到多个应用领域,而不仅仅是机器视觉范畴。
GAN实例
本篇我们尝试使用时尚单品的样本库作为训练数据,最终让模型可以由随机的种子向量,生成时尚单品的图片。
我们前面已经做过介绍,时尚单品的样本也是28x28单色图片,同MNIST手写数字样本是完全相同的格式。因此换用手写数字的图片样本,只要把载入样本数据的部分替换掉就可以,其它代码无需修改。
![]()
样本数据载入的部分:
(train_images, _), (_, _) = keras.datasets.fashion_mnist.load_data()
我们实际只需要了训练的数据集,测试集和两个数据集的标注我们都直接抛弃了。GAN是典型的非监督学习,并不需要标注。
源码中方法make_generator_model用来建立图片生成模型;make_discriminator_model方法用来建立辨别模型,辨别模型也就是我们刚才说的“考官”。
两个模型都使用keras.Sequential帮助建立,结构并不复杂。
模型的学习一定要关注输入和输出,中间的部分如果没有理论基础,反而可以并不是很在意。因为算法的研究会关注模型,软件开发工程师更关心使用。
生成网络输入随机数种子向量序列,输出是28x28x1的图片序列。一次调用可以生成多幅图片。
辨别模型输入是28x28x1的序列图片,输出只有1维。输出值接近0代表辨别结果是伪图片,输出值接近1表示辨别结果是真实样本图片。
其中的卷积网络层,我们在上一个系列中做了仔细的介绍,这里可以再稍微复习一下关于卷积的输出维度。卷积层的输入必须是宽x高x色深的多维数组。输出的色深部分,同卷积层的节点数相同。宽、高则同卷积核的步长数相关,一般是乘的关系。比如:
...假设本层输入为7x7x256...
layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
...因为节点数为128,步长是1...
...所以输出维度是7x7x128...
layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
...输出维度为14x14x64...
使用Keras之后,这些细节一般都不需要自己去算了。但在这种图片作为输入、输出参数的模型中,为了保证结果图片是指定分辨率,这样的计算还是难以避免的。
两个模型分别使用两个不同的代价函数,生成模型的代价函数很简单。我们期望生成网络的图片,经过辨别模型后,结果无限接近1,也就是真实样本的水平:
# 生成模型的损失函数
def generator_loss(fake_output):
# 生成模型期望最终的结果越来越接近1,也就是真实样本
return cross_entropy(tf.ones_like(fake_output), fake_output)
辨别模型的代价函数,则是要对所有的样本图片人为指定标注结果是1,对所有生成的图片,则人为指定标注结果0。这目的是训练辨别模型对于辨别真伪的能力越来越强,从而可以判断生成的图片,是否能无限接近真实样本图片的水平。这个过程,其实就是“对抗”的过程。
# 辨别模型损失函数
def discriminator_loss(real_output, fake_output):
# 样本图希望结果趋近1
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
# 自己生成的图希望结果趋近0
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
# 总损失
total_loss = real_loss + fake_loss
return total_loss
完整源码
程序的其它部分,都同通常的机器学习项目非常类似,应当读起来没有难度了。
#!/usr/bin/env python3
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow import keras
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
import sys
# 如果使用train参数运行则进入训练模式
TRAIN = False
if len(sys.argv) == 2 and sys.argv[1] == 'train':
TRAIN = True
# 使用手写字体样本做训练
# (train_images, _), (_, _) = keras.datasets.mnist.load_data()
# 使用时尚单品样本做训练
(train_images, _), (_, _) = keras.datasets.fashion_mnist.load_data()
# 因为卷积层的需求,增加色深维度
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
# 规范化为-1 - +1
train_images = (train_images - 127.5) / 127.5
BUFFER_SIZE = 60000
BATCH_SIZE = 256
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# 图片生成模型
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
generator = make_generator_model()
# 原图、生成图辨别网络
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
discriminator = make_discriminator_model()
# 随机生成一个向量,用于生成图片
noise = tf.random.normal([1, 100])
# 生成一张,此时模型未经训练,图片为噪点
generated_image = generator(noise, training=False)
# plt.imshow(generated_image[0, :, :, 0], cmap='gray')
# 判断结果
decision = discriminator(generated_image)
# 此时的结果应当应当趋近于0,表示为伪造图片
print(decision)
# 交叉熵损失函数
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
# 辨别模型损失函数
def discriminator_loss(real_output, fake_output):
# 样本图希望结果趋近1
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
# 自己生成的图希望结果趋近0
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
# 总损失
total_loss = real_loss + fake_loss
return total_loss
# 生成模型的损失函数
def generator_loss(fake_output):
# 生成模型期望最终的结果越来越接近1,也就是真实样本
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
# 训练结果保存
checkpoint_dir = 'dcgan_training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
EPOCHS = 100
noise_dim = 100
num_examples_to_generate = 16
# 初始化16个种子向量,用于生成4x4的图片
seed = tf.random.normal([num_examples_to_generate, noise_dim])
# @tf.function表示TensorFlow编译、缓存此函数,用于在训练中快速调用
@tf.function
def train_step(images):
# 随机生成一个批次的种子向量
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# 生成一个批次的图片
generated_images = generator(noise, training=True)
# 辨别一个批次的真实样本
real_output = discriminator(images, training=True)
# 辨别一个批次的生成图片
fake_output = discriminator(generated_images, training=True)
# 计算两个损失值
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
# 根据损失值调整模型的权重参量
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
# 计算出的参量应用到模型
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs+1):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# 每个训练批次生成一张图片作为阶段成功
print("=======================================")
generate_and_save_images(
generator,
epoch + 1,
seed)
# 每20次迭代保存一次训练数据
if (epoch + 1) % 20 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
print('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
def generate_and_save_images(model, epoch, test_input):
# 设置为非训练状态,生成一组图片
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
# 4格x4格拼接
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
# 保存为png
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
# plt.show()
plt.close()
# 遍历所有png图片,汇总为gif动图
def write_gif():
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
last = -1
for i, filename in enumerate(filenames):
frame = 2*(i**0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
# 生成一张初始状态的4格图片,应当是噪点
generate_and_save_images(
generator,
0000,
seed)
if TRAIN:
# 以训练模式运行,进入训练状态
train(train_dataset, EPOCHS)
write_gif()
else:
# 非训练模式,恢复训练数据
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
print("After training:")
# 显示训练完成后,生成图片的辨别结果
generated_image = generator(noise, training=False)
decision = discriminator(generated_image)
# 结果应当趋近1
print(decision)
# 重新生成随机值,生成一组图片保存
seed = tf.random.normal([num_examples_to_generate, noise_dim])
generate_and_save_images(
generator,
9999,
seed)
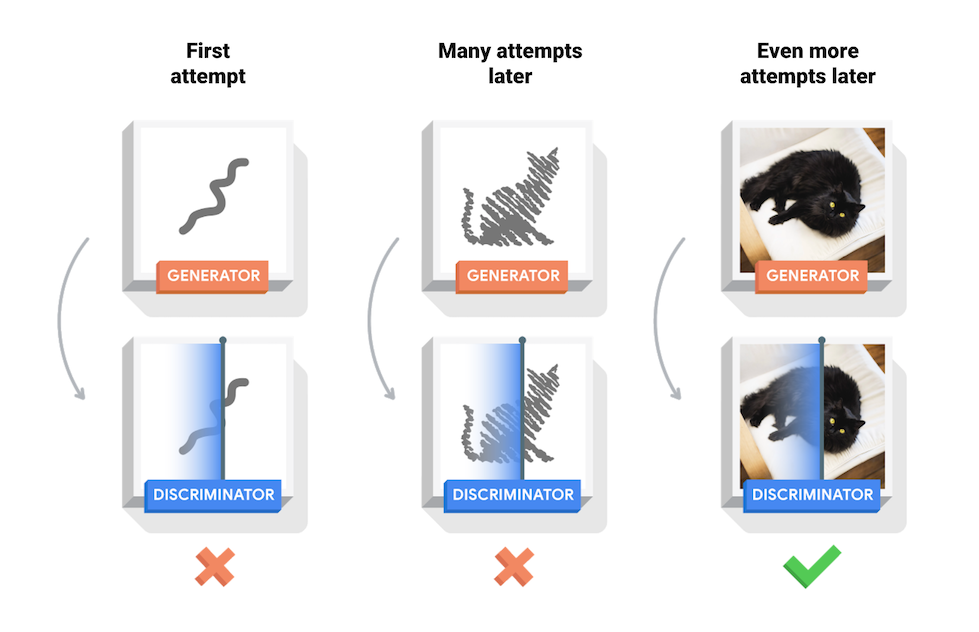
程序经过100次迭代,最终生成的的图片类似这个样子:

还是老话,看起来的确一般,但应当说已经有一些神似真实的样本了。
而把完整的训练过程连续起来作为一张动图,同VAE一样,是一幅从噪声到清晰,缓慢的渐进过程。因为GAN网络并非直接比较图片结果,无法更直接的指出图片差距,因此在渐进过程中,能看到一些反复和跳动。这说明,在机器视觉领域GAN的可控性并不如VAE。
 在所有模型未经训练的时候,我们随机生成了一幅图片,使用辨别器进行了判断。在训练完成之后,我们再次重复这一过程。通过命令行的输出,我们可以看到类似这样的结果:
在所有模型未经训练的时候,我们随机生成了一幅图片,使用辨别器进行了判断。在训练完成之后,我们再次重复这一过程。通过命令行的输出,我们可以看到类似这样的结果:
tf.Tensor([[-4.8871705e-05]], shape=(1, 1), dtype=float32)
After training:
tf.Tensor([[-1.5235078]], shape=(1, 1), dtype=float32)
一开始是一个很趋近于0的值,这是因为那张完全是噪点组成的生成图片,同真实样本图片完全没有相似点,虽然辨别模型并未训练,但这依然是很低的得分。
在训练完成后,所生成的图片,从辨别器的眼中看来,已经很接近真实样本,因此我们获得了一个较高的得分。
GAN参考论文:《NIPS 2016 Tutorial: Generative Adversarial Networks>
(待续…)
