TensorFlow从1到2(十五)(完结)
在浏览器做机器学习
![]()
TensorFlow的Javascript版
TensorFlow一直努力扩展自己的基础平台环境,除了熟悉的Python,当前的TensorFlow还实现了支持Javascript/C++/Java/Go/Swift(预发布版)共6种语言。
越来越多的普通程序员,可以容易的在自己工作的环境加入机器学习特征,让产品更智能。
在Javascript语言方面,TensorFlow又分为两个版本。一个是使用node.js支持,用于服务器端开发的@tensorflow/tfjs-node。安装方法:
npm install @tensorflow/tfjs-node
# ...GPU版本...
npm install @tensorflow/tfjs-node-gpu
另一个则是在浏览器中就可以使用的前端机器学习包@tensorflow/tfjs。安装方法:
npm install @tensorflow/tfjs
前者跟Python的版本一样,可以工作在单机、工作站、服务器环境。后者则只需要支持HTML5的浏览器就能良好的执行,浏览器版本目前还不支持GPU运算。
浏览器机器学习快速入门
浏览器版本的TensorFlow是其家族中性能最弱的一个发布,但很可能也是容易产生最多应用的版本。毕竟无需考虑运行环境,浏览即执行,能最大限度上降低对用户的额外要求。
我觉得将来很可能发展为在服务器端通过GPU支持完成模型的开发和训练,然后浏览器作为最方便的客户端只用来完成预测和反馈给用户直接的结果。
很多前端程序员还不喜欢使用node.js和npm帮助管理整体开发。所以我们直接从网页入手。而且这种方式,也更容易让人理解程序完整的运行方式。
首先是基础的网页,我在下面给出一个模板。TensorFlow.js的开发,都集中在js程序中,所以这个网页可以保存下来。不同的项目,只要更换不同的js程序就好。
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>TensorFlow.js 练习</title>
<!-- 引入机器学习库TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- 引入机器学习可视化库tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- 机器学习主程序(自己编写) -->
<script src="script.js"></script>
</head>
<body>
<!-- 放你的网页内容 -->
本页无正文<p />
</body>
</html>
其实就是一个空白的网页,分别引入了三个js文件。第一个js是TensorFlow的主要库,必不可少。第二个是用于TensorFlow可视化图表显示的,在正式发布的程序中根据需要使用。第三个是自己编写的程序。
接着我们使用《TensorFlow从1到2(七)》中,油耗预测的数据集,也完成一个简单的油耗预测的示例。
原始的数据结构请到第七篇中查看。这里为了js处理的方便,已经预先转成了json格式。下面是头两条记录的样子:
[
{
"Name": "chevrolet chevelle malibu",
"Miles_per_Gallon": 18,
"Cylinders": 8,
"Displacement": 307,
"Horsepower": 130,
"Weight_in_lbs": 3504,
"Acceleration": 12,
"Year": "1970-01-01",
"Origin": "USA"
},
{
"Name": "buick skylark 320",
"Miles_per_Gallon": 15,
"Cylinders": 8,
"Displacement": 350,
"Horsepower": 165,
"Weight_in_lbs": 3693,
"Acceleration": 11.5,
"Year": "1970-01-01",
"Origin": "USA"
},
...
我们只是想演示TensorFlow.js的使用,所以把问题简化一下,只保留功率数据(Horsepower)和油耗数据(MPG),MPG这里同时也是标注信息。
因为我们做过这个练习,我们知道样本中有无效数据。所以数据预处理的时候,还要把数据做一个清洗(当然数据清洗应当养成习惯)。
随后,浏览器不是命令行,不能简单的在命令行输出信息。这时候轮到TensorFlow-vis出场了,我们做一个二维映射把基础数据显示在屏幕上。
第一步先不走那么快,我们只完成这一部分功能,先执行起来看一看。
下面是完成刚才所说功能的代码,别忘了文件名是script.js,跟index.html要放在同一目录:
// 获取数据,只保留感兴趣的字段,并进行数据清洗
async function getData() {
const carsDataReq = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataReq.json();
const cleaned = carsData.map(car => ({
//只保留两个字段
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
//清洗无效数据
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
// 相当于主程序,执行入口
async function run() {
//载入数据
const data = await getData();
//建立绘图数据
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
//使用tfvis绘图
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
//载入后开始执行run()函数
document.addEventListener('DOMContentLoaded', run);
在支持HTML5的浏览器中打开index.html文件就开始了程序执行,因为是本地文件,通常双击打开就可以。程序一开始首先下载样本数据,视网络环境不同,速度会有区别。执行结束后会自动在浏览器的右侧弹出图表窗口显示我们绘制的样本分布图。
除了可能的输入拼写错误,文件下载是最可能出现的问题,如果碰到这种情况,请根据数据文件的路径自行下载到本地来进行试验。
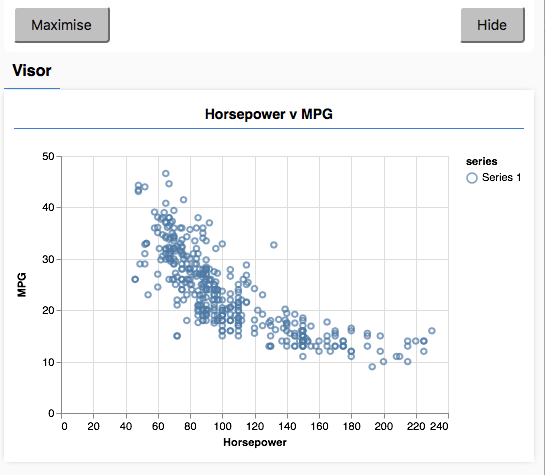
这部分相当于一个Hello World吧。从示例中可以看出,js在数据处理中,虽然没有Python的优势,但对于确定的数据类型也有自己的优点。在图表的显示上更是方便,无需第三方模块的支持。何况大多数现代浏览器也都包括console工具,必要情况下通过输出console的调试信息也可以达到很多目的。
此外有一点需要说明的,是稍微可能耗时的函数,应当尽量使用异步方式,也就是function关键字之前的async。以避免阻塞整个程序的执行。
当然使用了异步方式,程序的整体逻辑一定要多思考,想清楚,避免执行过程中顺序混乱。
用js定义模型
TensorFlow.js完整模仿了Keras的模型定义方式,所以如果使用过Keras,那使用TensorFlow.js完全无压力。
下面就是本例中的模型定义:
// 建立神经网络模型
function createModel() {
// 使用sequential对象建立模型
const model = tf.sequential();
// 输入层
model.add(tf.layers.dense({inputShape: [1], units: 128, useBias: true}));
// 隐藏层
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
model.add(tf.layers.dense({units: 25, activation: 'sigmoid'}));
model.add(tf.layers.dense({units: 5, activation: 'sigmoid'}));
// 输出层
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
代码中除了没有了tf.keras的关键字其它没有什么特殊的东西。你可能也注意到了,定义模型操作本身速度是很快的,并不需要异步执行。
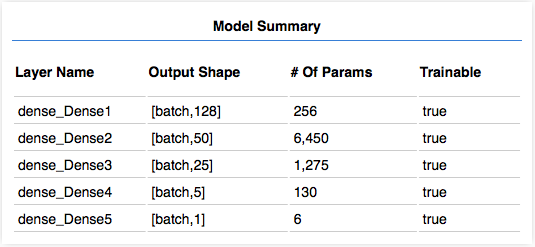
模型定义完成后,可视化工具提供了modelSummary方法,用于将模型显示在浏览器中供用户检查。
// 在图表窗口显示模型摘要信息
tfvis.show.modelSummary({name: 'Model Summary'}, model);
数据预处理
在数据载入的时候我们已经进行了一些预处理的工作。这个数据预处理主要是指把js数据转换为TensorFlow处理起来更高效的张量类型。此外还需要做数据的规范化。
在这里有很重要的一点需要说明。js语言在大规模数据的处理上,不如Python的高效。当然这一定程度上是浏览器的限制。
其中最突出的问题是内存的垃圾回收,这个问题困扰js已久,相信不做机器学习你也碰到过。而同时,用户对于浏览器的内存占用本身也是非常敏感的。
TensorFlow.js为了解决这个问题,专门提供了tf.tidy()函数。使用方法是把大规模的内存操作,放置在这个函数的回调中执行。函数调用完成后,tf.tidy()得到控制权,进行内存的清理工作,防止内存泄露。
其它没有什么需要特殊说明的,可以看源码中的注释:
// 将数据转换为张量
function convertToTensor(data) {
// 数据预处理的过程必然会产生很多中间结果,将占用大量内存
// tf.tidy()负责清理这些中间结果,所以要把数据处理包含在这个函数之内
// 这一点很重要
return tf.tidy(() => {
// 把样本数据乱序排列
tf.util.shuffle(data);
// 将数据转换为张量,功率值作为特征值,油耗值作为标定目标
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
// 数据规范化,把数据从最小到最大转换为0-1浮点空间
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// 把数据范围值也要返回,我们后面绘图会用到
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
完整代码
程序核心的训练和测试(预测)的代码在TensorFlow中非常简单,我们早就有经验了。唯一需要说明的是,除了跟Python中一样使用model.fit()做训练,以及model.predict()做预测,我们的过程和结果,也会使用TensorFLow-vis图表工具可视化出来,显示在浏览器中。
其中训练部分,是使用回调函数,这种机制我们在Python中也见过。目的是能够动态的显示训练的过程,而不是全部训练枯燥、漫长的等待完成才显示一次。
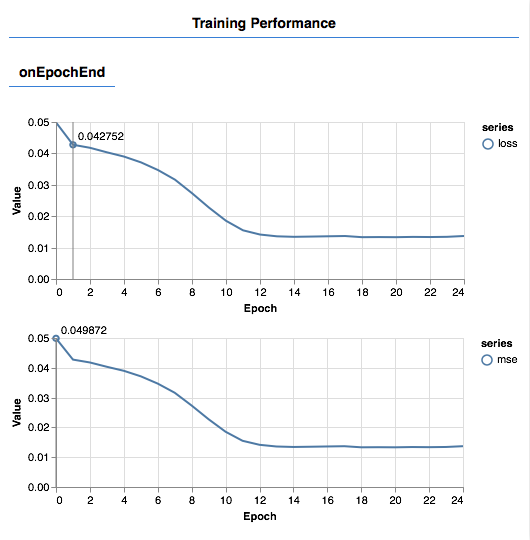
预测部分的数据少,速度很快,就是执行完成后一次显示。
但预测部分的数据有大量的转换过程,这个过程消耗内存大,所以放在tf.tidy()中执行以防止内存泄露。
好了,代码秀出,请参考注释阅读:
// 获取数据,只保留感兴趣的字段,并进行数据清洗
async function getData() {
const carsDataReq = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataReq.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
// 相当于主程序,执行入口
async function run() {
//载入数据
const data = await getData();
//建立绘图数据
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
//使用tfvis绘图
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// 建立神经网络模型
const model = createModel();
// 在图表窗口显示模型摘要信息
tfvis.show.modelSummary({name: 'Model Summary'}, model);
// 将数据从js对象转换为张量,并完成预处理
const tensorData = convertToTensor(data);
// 使用样本数据训练模型,训练时只需要x/y的值
const {inputs, labels} = tensorData;
await trainModel(model, inputs, labels);
// 训练完成在console输出完成信息(需要打开浏览器console窗口才能看到)
console.log('Done Training');
// 使用训练完成的模型进行预测并显示结果
testModel(model, data, tensorData);
}
// 载入完成执行主函数run()
document.addEventListener('DOMContentLoaded', run);
// 建立神经网络模型
function createModel() {
// 使用sequential对象建立模型
const model = tf.sequential();
// 输入层
model.add(tf.layers.dense({inputShape: [1], units: 128, useBias: true}));
// 隐藏层
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
model.add(tf.layers.dense({units: 25, activation: 'sigmoid'}));
model.add(tf.layers.dense({units: 5, activation: 'sigmoid'}));
// 输出层
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
// 将数据转换为张量
function convertToTensor(data) {
// 数据预处理的过程必然会产生很多中间结果,将占用大量内存
// tf.tidy()负责清理这些中间结果,所以要把数据处理包含在这个函数之内
// 这一点很重要
return tf.tidy(() => {
// 把样本数据乱序排列
tf.util.shuffle(data);
// 将数据转换为张量,功率值作为特征值,油耗值作为标定目标
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
// 数据规范化,把数据从最小到最大转换为0-1浮点空间
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// 把数据范围值也要返回,我们后面绘图会用到
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
async function trainModel(model, inputs, labels) {
// 编译模型
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
//每批次数据数量和训练迭代数量
const batchSize = 28;
const epochs = 25;
// 训练
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
// 使用回调函数绘制训练过程,曲线指标loss/mse
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
// 测试模型
function testModel(model, inputData, normalizationData) {
// 获取数据集的取值范围
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// 防止内存泄露,依然要把大量数据的操作放在tf.tidy值中
const [xs, preds] = tf.tidy(() => {
//功率数据直接使用0-1空间,相当于遍历所有样本空间
const xs = tf.linspace(0, 1, 100);
//批量预测
const preds = model.predict(xs.reshape([100, 1]));
// 预测结果也是规范化的0-1值,所以使用数据集取值范围还原到原始样本模型
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
// 返回最终结果
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
// 准备成绘图数据
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
// 原始的样本生成散列点同屏显示
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
//绘图
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
程序执行,最终预测测试的输出结果如下:
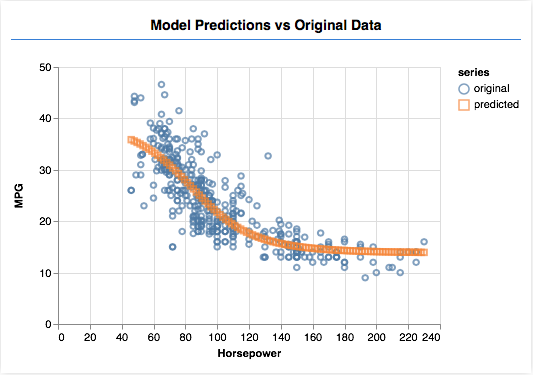
结语
本连载目标定位让已经有TensorFlow使用经验的技术人员,快速上手TensorFlow 2.0开发。
不知不觉,连载15篇。但还有很多内容未能包含进来。比如分布式训练、比如图像内容描述等。建议有需要的朋友继续到官网文档中学习。
水平所限,文中错误、疏漏不少,欢迎批评指正。
(连载完)
