从锅炉工到AI专家(2)
TensorFlow实务
大数据
上一节说到,大多的AI问题,会有很多个变量,这里深入的解释一下这个问题。
比如说某个网站要做用户行为分析,从而指导网站建设的改进。通常而言如果没有行为分析,并不需要采集用户太多的数据。
比如用户注册,最少只需要用户名、用户密码就够了。随后比如为了当用户过生日的时候,自动给用户发送一封贺卡(潜台词,我们可能需要给用户推送广告),我们再增加两项生日日期和邮箱地址。再下来国家规定网站注册必须实名制,我们可能又增加了用户姓名和身份证号码,可能还需要增加用户手机号码,用于同移动通信部门打通,验证用户实名制的真实性。这样一共是七个数据字段(仅为示例,事实比本例肯定要复杂很多倍)。
随后通过网站的运营,用户数不断增加,到了某一天,网站的技术人员发现,数据量太大了,并发也太高了,一组服务器已经无法负担网站的运营。最重要其中的基础数据库也变得太大,系统无法容纳,需要分库、集群的新技术,才能保证网站的运营。
从网站的运维来讲,这的确是一项重要的技术改进。但从“机器学习”的角度看,这些数据量的变化,并没有什么不同,可能在算法上,也不需要有太大的改变。所以严格上讲,这样的数据管理,还不能叫大数据。
我们继续向下看,为了进行用户行为的分析。我们还要增加很多用户数据的采集点。比如用户每次访问网页的IP地址、用户的点击习惯、每个页面停留的时间、在页面上习惯点哪些位置的链接、操作上有什么习惯、用户的设备是什么型号、用户每次上网在什么时间段,这样需要关注的数据,我们还能列出很多。甚至可能会付费去第三方的公司购买很多其它的信息,比如我的用户还喜欢在什么网站停留,停留在其它网站的时候关注了什么内容,最近购买了什么东西等等信息。
这些信息有下面几个特点:
- 并不是简单的信息表长度增长了,而是每行信息关注的维度大大的增加了,也就是信息表变宽了。
- 随着维度的增加,总体的数据量可能会激增,很少的用户数,就需要利用到集群、并发等多种处理方式来解决压力问题。
- 这些增加的维度,由于数量的增加,基本只能考虑用机器学习的方式,由计算机自动完成处理,分析其中的规律。
还有一些数据,天生就是多维的,比如图片识别。每幅图片,数字化保存到电脑之后,很可能是一大笔数据,比如某副照片320x240分辨率,那就相当于320x240x(RGB 3色)=230400维的一个数据集。这个在后面讲到具体案例的时候还会说到。
梯度下降法解线性回归方程
在数据维度非常多的时候,也就是我们的方程可能有n个变量(n值很大)的时候,原有的公式、解法都已经失效了。可能是计算量过大导致速度无法接受,也可能是空间需求太大导致我们的计算机无法做到,所以我们需要有新的办法来完成解方程—-也就是机器学习的过程。
梯度下降法是我们常用的一种方式,实际上这种算法包括其针对性或者改进型算法有很多种,应当称为梯度下降法家族。比如批量梯度下降法(BGD)、随机梯度下降法(SGD)、小批量梯度下降法(MBGD)等。
这是统计学家和经济学家在大量数据分析过程中常用的手段,所以其实早期的机器学习专家往往也是来自于统计专业。
在大多机器学习的课程中,对梯度下降法及相关算法的讲解是最重要的一部分,但现在情况有所改变。TensorFlow以及其它一些流行框架,已经内置了函数用于运行梯度下降法及其它常用算法,技术人员即便不了解这些知识,也能够上手机器学习项目。所以原本我计划略去这部分算法的细节。但发现实际上还是不能,因为我看到了很多在TensorFlow官方样例运行很好,但到了具体项目中就失败的例子,归根结底还是对算法本身了解太少,碰到问题不知道如何下手解决。
所以几经修改,我决定既不略去,也不再作为重点。这里用伪代码的方式来简略描述一下这个算法的工作流程:
- 首先定义好我们的公式,比如前面提到的房价公式是y = Θ0 * x + Θ1,方便起见,我们这里称这个公式为:y’=fj(x)
- 我们定义一个代价函数(Cost function),用于表示真实房价与我们计算房价差的绝对值,这里记为:abs(y-y’)。这里我们省去梯度下降法的公式推导过程,最终的推导结果我们记为J(Θ0,Θ1),你只需要知道,这个跟上面说的预测房价合真实房价之差是等价的。这个代价函数的值越小,表示我们要求的方程越接近真实解。注意x/y都是我们手中资料库中已有的数据集,我们想用这些已有的数据集,来得出原来公式中Θ0/Θ1两个常量的值,从而完成方程求解,也就是“机器学习”的过程。
- 我们随机为Θ0/Θ1取一个初始值。
- 利用Θ0/Θ1的当前值,带入一组当前已有的数据x,利用公式fj(x)求得一个房价值,记为y’,同时跟样本中的真实y值一起计算代价函数的值。
- 通过梯度下降步长alpha,带入梯度下降公式,得到一组新的Θ0/Θ1,并以此带入fj(x)计算新的y’,然后计算新的代价函数值。(梯度下降公式有兴趣请查看链接资料)
- 重复步骤5,直到得到一个最小的代价函数值,此时的Θ0/Θ1取值就是我们要求解的值。
- 这里的讲解,把先前的常量a/b替换成了Θ0/Θ1,原因是,我们将来的参数集可不会只有两个这么少,可能是n个,希望你明白这里只是在降维模拟一个过程。
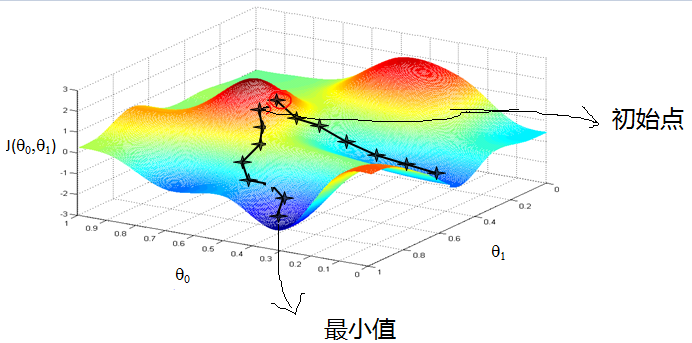
这张图描述了梯度下降法解方程的过程。需要说明的是图中手绘的部分,就是我们一开始随机取了初始值,也就是初始点,然后逐步的梯度下降,直到代价函数值最小的时候,得到两个未知数的解。
同时从图中可以看出来,因为初始值的不同及步长的不同,梯度下降法很可能会陷入某个局部最小值,这时候梯度下降法因为已经最小,向周围任何一点继续都无法得到更小的代价函数值,从而终止了继续求解。但实际上离最优解还有很大差距.下面这张图是降维到2维的一张示意图,可以看的更清楚:
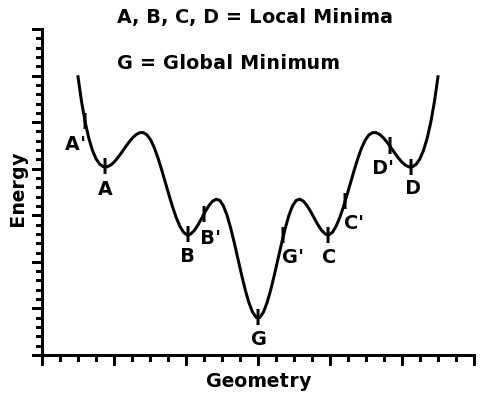
图中的G点是最优解,A/B/C/D点都是局部最优解。当我们的变量很多的时候,很高的维度使得获取全局最优解往往是很不容易的。
陷入局部最优解的时候实际上只有这样几个选择:1.随机产生另外一组初始值,同时增加尝试求解过程的次数,从而得到不同的解,取其中最好的值;2.变更梯度下降步长;3.变更或者优化算法。局部最优解是《机器学习》算法调优重点之一
具体的算法本身是纯粹的数学问题,有网友收集、撰写的参考资料在最下面的参考链接里面,写的很不错。我建议有志于算法研究的朋友一定仔细阅读。刚才说了,实际上在很多《机器学习》课程中,这部分占了相当的篇幅,可见其重要性。从这个角度上说,现代机器学习的框架一方面降低了学习的门槛,不需要懂梯度下降法也能使用机器学习,另外一方面,是不是也就此屏蔽了很多人真正上升的空间呢?
第一个练习,我们先深入一下
行文这么长了,终于要进入TensorFlow的世界。估计你读的很辛苦,我尽力用非专业的语言来解释很多基础的概念和来龙去脉,忍得也很辛苦。
在正式例子之前,再补充一个“机器学习”的重要概念,数据“规范化”。
我们注意到了,为了进行“机器学习”,我们从很多维度获取相关数据,建立复杂的数学模型,以求得到比较好的结果。
但这些方方面面的数据,差别非常大,比如有价格因素,取值范围很可能是几千到上亿;也很可能是面积因素,取值几十到几百。将来还可能有朝向因素,如果把方向数字化,可能不过是1-4;类似的还很多,比如楼层数。
总的来说,这些数字如此大的量级差距,在一个试图建立较为通用(注:后面还会对“较为通用”这个词再详细解释)的数学化公式的算法中,会对结果产生不可估量的影响。比如面积多1平米或者少1平米,本来应当对最终房价有很大的影响。但对于同样的数字,计算机并不理解这个数量级跟另外一个参数数量级之间的差别,它看起来增加1平米跟增加1块钱是一样的。最后的结果,不可避免的会倾向数字大的参数所导致的影响,从而让计算结果完全不可用。
因此,所有采集到的数据在真正进入运算之前,首先要规范化,比较通用的规范化方式,是计算某个具体值在该参量取值范围中的比例值,让最终的结果是0-1之间的浮点小数,这样可以保证所有的参量,最终是工作在同一个量级维度上,从而保证结果的正确性。
数据的“规范化”,是影响“机器学习”精度的重要因素,绝对不可省略。
终于可以进入源代码部分了,我习惯于在代码中加入详细的注释让你做到每一行都看懂,我认为这是重要的学习手段之一。
源码中随机生成了100套住房面积和对应价格的数据集,然后通过TensorFlow使用内置的梯度下降法解出每平米价格及基础费用两个系数。在这里要求读者已经有python的基础知识,因为至少当前,机器学习的首选语言还是python。
#!/usr/bin/env python
# -*- coding=UTF-8 -*-
#本代码在mac电脑,python2.7环境测试通过
#第一行是mac/Linux系统脚本程序的标志,表示从环境参量中寻找python程序解释器来执行本脚本
#省去了每次在命令行使用 python <脚本名> 这样的执行方式
#第二行表示本脚本文本文件存盘使用的代码是utf-8,并且字符串使用的编码也是utf-8,
#在本源码中,这一点其实没有什么区别,但如果需要中文输出的时候,这一行就必须要加了。
#引入TensorFlow库
import tensorflow as tf
#引入数值计算库
import numpy as np
#使用 NumPy 生成假数据集x,代表房间的平米数,这里的取值范围是0-1的浮点数,
#原因请看正文中的说明,属于是“规范化”之后的数据
# 生成的数据共100个,式样是100行,每行1个数据
x = np.float32(np.random.rand(100,1))
#我们假设每平米0.5万元,基础费用0.7万,这个数值也是规范化之后的,仅供示例
#最终运行的结果,应当求出来0.5/0.7这两个值代表计算成功
#计算最终房价y,x和y一同当做我们的样本数据
# np.dot的意思就是向量x * 0.5
y = np.dot(x,0.5) + 0.7
#---------------------------------数据集准备完成
#以下使用TensorFlow构建数学模型,在这个过程中,
#直到调用.run之前,实际上都是构造模型,而没有真正的运行。
#这跟上面的numpy库每一次都是真正执行是截然不同的区别
# 请参考正文,我们假定房价的公式为:y=a*x+b
#tf.Variable是在TensorFlow中定义一个变量的意思
#我们这里简单起见,人为给a/b两个初始值,都是0.3,注意这也是相当于规范化之后的数值
b = tf.Variable(np.float32(0.3))
a = tf.Variable(np.float32(0.3))
#这是定义主要的数学模型,模型来自于上面的公式
#注意这里必须使用tf的公式,这样的公式才是模型
#上面使用np的是直接计算,而不是定义模型
# TensorFlow的函数名基本就是完整英文,你应当能读懂
y_value = tf.multiply(x,a) + b
# 这里是代价函数,同我们文中所讲的唯一区别是用平方来取代求绝对值,
#目标都是为了得到一个正数值,功能完全相同,
#平方计算起来会更快更容易,这种方式也称为“方差“
loss = tf.reduce_mean(tf.square(y_value - y))
# TensorFlow内置的梯度下降算法,每步长0.5
optimizer = tf.train.GradientDescentOptimizer(0.5)
# 代价函数值最小化的时候,代表求得解
train = optimizer.minimize(loss)
# 初始化所有变量,也就是上面定义的a/b两个变量
init = tf.global_variables_initializer()
#启动图
sess = tf.Session()
#真正的执行初始化变量,还是老话,上面只是定义模型,并没有真正开始执行
sess.run(init)
#重复梯度下降200次,每隔5次打印一次结果
for step in xrange(0, 200):
sess.run(train)
if step % 5 == 0:
print step, sess.run(loss),sess.run(a), sess.run(b)
随后我们看看上面脚本运行的结果:
0 0.017659416 0.56524247 0.7991155
5 4.084394e-06 0.50660795 0.6963032
10 1.9465895e-06 0.5046281 0.697532
15 9.344591e-07 0.50320655 0.69828993
20 4.4858396e-07 0.5022217 0.69881517
25 2.1534281e-07 0.5015393 0.69917905
30 1.0337125e-07 0.5010665 0.6994312
35 4.9617547e-08 0.5007389 0.69960594
40 2.3823773e-08 0.500512 0.69972694
45 1.1437169e-08 0.50035477 0.6998108
50 5.4911653e-09 0.5002458 0.6998689
55 2.6369513e-09 0.50017035 0.69990915
60 1.2654721e-09 0.500118 0.69993705
65 6.075896e-10 0.5000818 0.69995636
70 2.9137154e-10 0.5000566 0.69996977
75 1.4008027e-10 0.5000393 0.69997907
80 6.7331245e-11 0.50002724 0.69998544
85 3.2336054e-11 0.5000189 0.6999899
90 1.5535804e-11 0.5000131 0.699993
95 7.4518525e-12 0.50000906 0.69999516
100 3.5502267e-12 0.50000626 0.69999665
105 1.648246e-12 0.5000043 0.6999977
110 8.017054e-13 0.500003 0.6999984
115 3.877787e-13 0.5000021 0.6999989
120 1.8626878e-13 0.50000143 0.6999992
125 8.9173115e-14 0.500001 0.69999945
130 4.515499e-14 0.5000007 0.69999963
135 2.1138646e-14 0.5000005 0.69999975
140 1.20437e-14 0.50000036 0.6999998
145 1.20437e-14 0.50000036 0.6999998
150 1.20437e-14 0.50000036 0.6999998
155 1.20437e-14 0.50000036 0.6999998
160 1.20437e-14 0.50000036 0.6999998
165 1.20437e-14 0.50000036 0.6999998
170 1.20437e-14 0.50000036 0.6999998
175 1.20437e-14 0.50000036 0.6999998
180 1.20437e-14 0.50000036 0.6999998
185 1.20437e-14 0.50000036 0.6999998
190 1.20437e-14 0.50000036 0.6999998
195 1.20437e-14 0.50000036 0.6999998
因为数据集是随机产生的,所以上面结果每次运行都会不同,但基本上在150步以内都能有效收敛,请看打印出来的两个结果值,也是很令人满意的。
(待续…)
