从零开始学习PYTHON3讲义(八)
列表类型跟冒泡排序

《从零开始PYTHON3》第八讲
前面我们见过了不少的小程序,也见过了不少不同类型的变量使用的方法。但目前我们涉及到的,还都是单个的变量和单个的立即数。以变量来说,目前我们见到的,基本都属于“临时性”的使用。实际如果想发挥计算机的速度优势,还需要批量处理数据,这就需要有批量处理能力的变量类型,这就是我们下面要学习的列表类型。
列表类型
列表类型属于我们学习的Python基本数据类型中的第3种,在其它语言中通常以“数组”来称呼。
先复习一下第六讲的一个小程序:
for x in [2,3,8.3,34,55,23]:
print(x)
#运行结果:
2
3
8.3
34
55
23
第六讲的时候我们讲的是for循环,在使用for循环遍历序列化类型的时候,我们使用了这个例子,实际上,例子中的[2,3,8.3,34,55,23]部分,就是一个完整的列表类型,更准确说,是数字列表。此外我们在第六讲说过了,列表类型属于序列化类型的一种,序列化类型并不是Python中的一种类型,而是指的是可以按照某种规则逐个访问的类型。其实这个概念就是遍历的概念,我们第六讲的时候也说过了,for语句就是专门为了遍历功能设计的。
在学习for循环的时候,我们还学习过range()函数,比如:range(100)。既然能在for类型中使用,range()函数返回的当然也是序列化的类型,但并非列表。想把range()的返回结果当做列表使用,需要使用list()函数来转换,比如:
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
使用立即数来为列表变量赋值(或者说叫初始化)使用如下的方式:
arr = [2,3,8.3,"hello",34,True,55,23]
同其它数据类型的赋值方法一样,使用“=”赋值操作符。列表的立即数,则使用“[]”中括号包裹,每个数据之间,使用逗号隔开。列表中的每个元素都会被分配一个数字指定它的位置。这个位置也可以叫索引,第一个索引是0,第二个索引是1,依此类推。一个列表中元素的顺序,就是他们的位置,也就是索引的顺序。
在每个列表数据中,可以包含不同数据类型的数值。但通常并不这样使用,因为这会使得处理的逻辑复杂,或者降低工作效率。而且并不容易让其它人理解。所以千万不要模仿这里用于示例的使用方式。
列表类型有以下一些常用的操作:
-
检查列表中的元素数量,这也被称为列表的“长度”:
>>> a=[12,78,23,5.5,9.2,90,332,45] >>> len(a) 8 -
访问列表中的数据:
#定义一个列表: arr = [2,3,8.3,"hello",34,True,55,23] #取其中指定个元素 arr[0] => 2 arr[3] => 'hello' arr[-1] => 23 arr[40] => 越界出错 #越界出错的提示通常是这样: Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range前面说过了,列表中每个元素都有一个“索引”标识该元素的位置。在其它一些语言中,也称为“下标”。就是前面例子中,中括号中的数字。“索引”、“下标“在这里是同一个意思。通常我们学习中会碰到的同义词有很多,这是因为大家都使用的翻译过来的词汇,而翻译并不统一。
再强调一遍,下标计数是从0开始的,不是1。你一定要习惯,在计算机中,很多计数都是从0开始,而不是1。
下标不能超过列表中元素数量的范围,否则会报错。
-
列表中单个元素的赋值和替换
给列表中元素赋值,跟获取列表中元素的值是一样的,只是将列表和下标当做“左值”,也就是放到等号左侧。
下标同样不能“越界”
并非所有的“序列化”类型都能更改其中的值,列表是可以更改的类型,后面我们会详细讲”不可更改“类型是什么情况。
#定义列表: arr = [2,3,8.3,"hello",34,True,55,23] #给指定元素赋值 arr[0] = 2.5678 arr[3] = 10 arr[-1] = "你好" arr => [2.5678, 3, 8.3, 10, 34, True, 55, '你好'] -
列表的+运算和*运算
列表的 + 和 * 运算非常类似于字符串中的 + 和 *,可以看看例子:
["a",1,2]+[4,"b",3] => ['a', 1, 2, 4, 'b', 3] [1,2,3]*3 => [1, 2, 3, 1, 2, 3, 1, 2, 3]列表和字符串,都没有定义-和/的操作。
-
为已经存在的列表增加元素,有三种可能的方法:
#+运算的方法 a=["a",1,3]+[4] a => ['a', 1, 3, 4] #使用追加函数,在列表最后增加元素 a.append("new") a => ['a', 1, 3, 4, 'new'] #使用插入函数,在列表中间增加元素 a.insert(2,3.3) #在第2个位置增加,注意从0开始计数下标 a => ['a', 1, 3.3, 3, 4, 'new']列表可以只包含1个元素或者0个元素,上面代码中,第一种方式使用的例子中,就采用了加运算来操作1个元素的列表。 同我们以前学过的print/len这些函数不一样,append必须依附于列表类型(或者其它支持的类型),这种方式叫“面向对象(object)编程”,这是跟我们现在使用的“面向函数编程”是对应的。曾经认为面向对象编程是先进的方式。实际上现在人们已经共识,每种编程方法,都有自己的适用范围。 因为有越界问题的存在,列表变量,在被添加数据之前,需要先使用赋值初始化,比如a=[],注意这个时候,列表变量a实际上包含0个元素。
-
有增加自然有删除,列表元素的删除有两种常用的方法:
#接着上一个例子,假设现在有列表变量a a => ['a', 1, 3.3, 3, 4, 'new'] #弹出,是指从列表最后删除一个元素,并作为返回值返回 #这种方法是为了喜欢“堆栈”算法的程序员准备的 #堆栈算法我们并不涉及,知道概念就好 x=a.pop() a => ['a', 1, 3.3, 3, 4] x => 'new' #移除指定位置的元素,不返回移除的值 a.remove(3) a => ['a', 1, 3.3, 4]记住函数的返回值是可以省略的,只调用a.pop()不保留其返回值就等于只删除了列表最后一个值。
append/pop/remove这些都是从属于某个列表变量的函数,记住他们跟前面的变量名之间使用一个“.”隔开。
今天学习列表类型,我们一下子学习了不少新的函数,可以说新函数出现的速度再次加快。千万不要紧张,我们前面已经讲过了,语言本身的学习实际很容易,学会了关键字,懂了语法就算会了。然后通过算法的学习来加强编程的能力。在这个过程中,会不断的接触新的函数,大多数函数都不需要你记住,大致理解概念,想用的时候搜索能找到就算合格。
此外,在Python的交互模式中,也内置了帮助系统,可以帮助你知道如何使用不熟悉的函数。很遗憾,目前只有英文的帮助文档。所有立志从事科技事业的同学,也要加强英语的学习。
>>> help("keywords") #列出所有关键字
Here is a list of the Python keywords. Enter any keyword to get more help.
False class from or
None continue global pass
True def if raise
and del import return
as elif in try
assert else is while
async except lambda with
await finally nonlocal yield
break for not
>>> help("for") #使用help函数,显示关键字for的文档
#下面省略的帮助的内容,非常详细,因此非常长
今天学的列表类型,内置了很多的函数,同样也可以使用help()函数来获取帮助:
help(list)
还可以查询具体某个函数的帮助:
help(list.append) #查看list的append函数
help(print) #查看print函数
help()函数的帮助文档使用有一些小技巧需要知道。如果是在IDLE环境中,帮助文档会一次全部显示出来,同时开始准备接受下一条交互命令。这时候可以使用鼠标拖动滚动条上下翻页浏览内容。
如果是在命令行方式下使用的Python,并在交互模式下使用了help()函数,可以:
- 使用翻页键上下翻页查看文档。
- 空格键也是向下翻页。
- q键退出帮助,返回交互式的界面。
挑战
1.首先是相对简单的一个题目:请用户输入10个数字, 保存到列表,随后按照输入顺序的逆序显示出来。
请充分思考,并有了清晰思路后再向下看。
#请用户输入10个数字, 保存到列表,随后按照输入顺序的逆序显示出来
#用户输入的数字个数
n=10
print("下面请输入",n,"个数字。")
#因为越界问题的存在,列表变量添加数据前,需要先初始化
a=[] #使用空白列表初始化
#循环输入,直接输入到列表
for i in range(n):
#print参数中的end设置为‘’表示显示完不换行
#在字符串一章中我们讲过换行符'\n',通常end是换行符
print("请输入第",i+1,"个数字:",end='')
a.append(input())
for i in range(9,-1,-1):
print("第",i+1,"个数字是:",a[i])
程序中有了较多的注释,已经能让大多同学看懂。还有疑惑的,继续做一个充分的思考,对疑惑的部分,在心中做一个假设,然后再继续向下看。这是一个非常好的学习方法,可以帮助你理解对方的编程思路。
-
print("请输入第",i+1,"个数字:",end=''),print在这里的目的当然是显示提示信息,使用i+1的原因,是因为人们习惯上是从1开始计数,10个数字,计数到10。而列表类型是从0开始计数,这里把i加一为了看上去更自然。同时因为需要使用了多个参数的组合,虽然input函数也支持显示一段提示信息,但input并不支持多个参数组合,所以必须在input之前用一个print函数来显示提示信息。
通常print显示最后会换行,效果就称为在新的一行让你输入信息。这肯定不好看,所以要在print的最后设置不允许换行,这样能让input在同一行开始输入信息。这个是print函数中,参数end=’‘的作用。
-
a.append(input())是两个函数组合使用,我们在第三讲中就见过了。因为时间比较长,这里我们再重复一次。这条语句等同于这样的方式:temp = input() a.append(tmp)而且这样组合使用还可以省掉一个临时的变量。
此外你可能会问,既然要求输入数字,为什么没有使用int()或者float()来转换?
原因很简单,题目中只是要求输入、输出,并没有计算的要求,所以没有必要一定转换成数字。何况转换还可能因为用户输入的错误而报错。因此,本例中所使用的数组,实际上会是一个字符串数组。
-
range(9,-1,-1),跟我们平常熟悉的range使用不太一样,区别在于这里是逆序的序列,等同于:[9,8,7,6,5,4,3,2,1,0],注意同样不会包括最终的边界-1,这刚好吻合我们的需求。
2.接下来会有点难度了:把给定的10个数字由大到小排序显示。
这可能是我们正式涉及到的第一个算法:冒泡排序。所以我们直接开始讲解。排序是最常用的算法之一,也是很基础的算法,很多的算法也依赖于排序的结果。Python有内置的排序函数,我们最后再介绍。
首先假设我们有一个数组,包含10个数字,你可以理解为我们上面练习输入的10个数字,当然是转换成数字类型之后的:
data = [5,22,34,12,87,67,3,43,56,23]
让我们用一张图来讲解“冒泡排序”的基本原理:
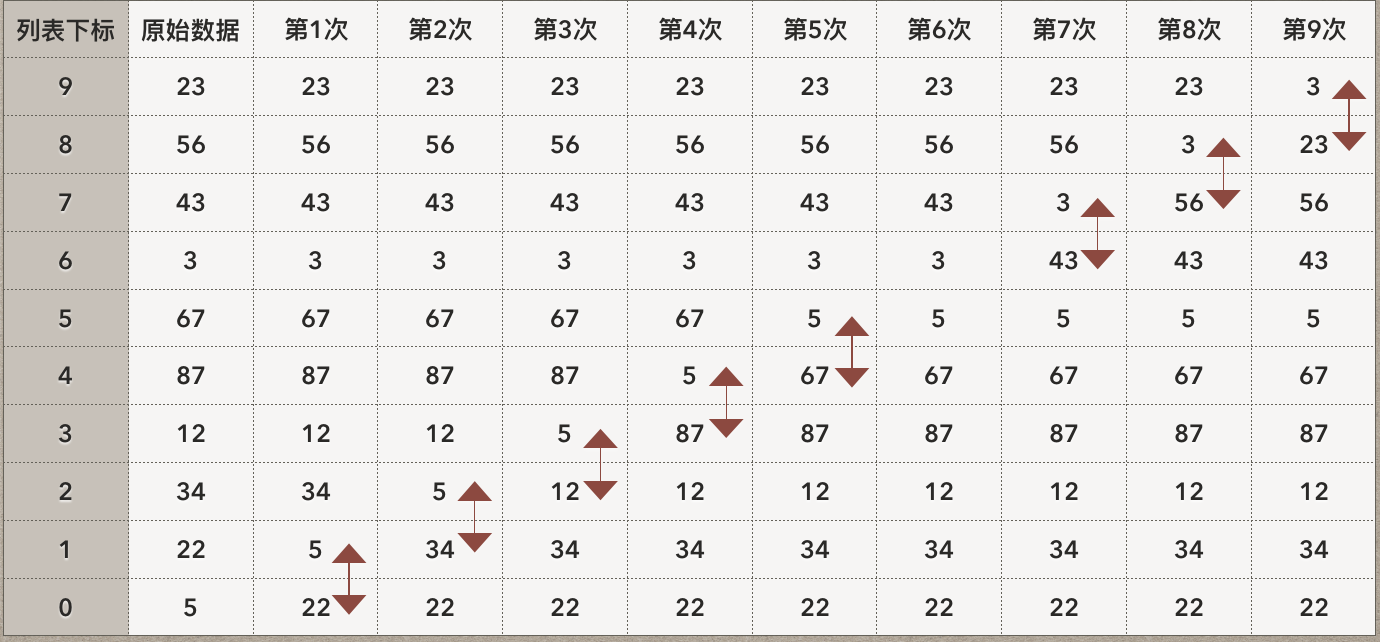 上图中,最左边一列是数组的下标索引,请对照上面的列表赋值语句,在最下面的是元素0,最上面的是元素9,0-9共10个数字元素。上图中从左数第二列是原始数组的样子,尚未排序。
上图中,最左边一列是数组的下标索引,请对照上面的列表赋值语句,在最下面的是元素0,最上面的是元素9,0-9共10个数字元素。上图中从左数第二列是原始数组的样子,尚未排序。
随后第1次循环,我们开始从第0个数字开始处理,把这个数字,跟它后面的一个数字相比较,把两个数字中,小的一个,放在后面(图中是上面)。以5和22为例,比较之后,5更小,所以把5跟22调换位置,第0个元素变成22,第1个元素,是5。
接着第2次循环,把第1个元素,这时候是5,跟第2个元素,这时候是34,比较。同样把小的放到后面,因此5、34又调换了位置,5成为元素2。
这样的操作一直循环继续,其中只有当5成为第5个元素,跟第6个元素3比较的时候,3更小,因此3和5的位置没有调换。并且在之后的循环中,使用3跟其后面的43进行比较,操作的方式完全相同。
这样完成全列表的比较之后,第9个元素,是全列表中最小的数值3。其它的元素也变动了位置,变动的原则是数值大的,更靠前了。但除了第9个元素3,其它元素并没有完成排序。
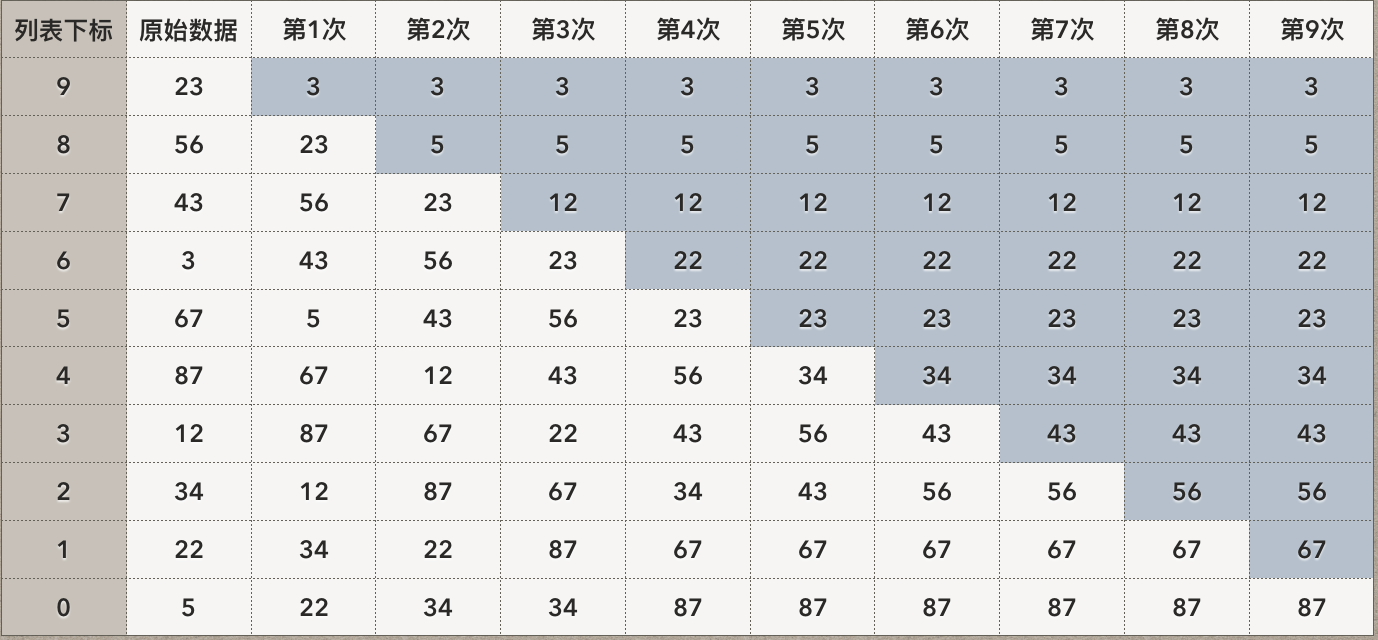
以上的操作肯定很适合用一个循环来执行,因为是在最核心的位置执行,也称为内循环。相应的,当然有外循环,来不断的变换条件,并执行内循环。我们已经知道内循环每循环一次,都将把列表中一个最小的数字,放到列表的最后,因此外循环的目标,就是不断循环,让前面的、最小的元素,不断跑到列表的最后(图中是上部)这很像水中的气泡,这是“冒泡排序”算法名称的由来。上图用来说明外循环每次执行的样子。外循环嵌套了内循环,外循环每执行一次,相当于执行一个完整的内循环,也既完成把本次循环找到的最小的数字,“冒泡”到上面“未排序”部分的“最后”位置。
观察一下内循环的边界,开始肯定是从第0个元素开始,结束则是列表数量少1个,因为每次都是比较当前元组及其后的1个元素,所以结束边界是比列表数量少1。并且,当下一次使用内循环的时候,开始的位置还是0,但结束边界都要比上次再少1,因为上次的内循环,已经把整个列表最小的数值,“冒泡”到了最上面。
我们再看外循环的边界,起始当然也是0,而结束边界,同样是列表元素数量-1。原因是每次循环都将把列表中最小的数值冒泡到最上面,最后最大的元素必然已经剩到了第0个元素,无需再循环。因此循环的边界是要比元素总数少1次。
现在我们可以看看排序源码了:
data = [5,22,34,12,87,67,3,43,56,23]
def bubbleSort(data):
n=len(data)
for i in range(0,n-1):
for j in range(0,n-i-1):
if (data[j]<data[j+1]):
data[j],data[j+1] = data[j+1],data[j]
#print(i,j,data)
#print(i,data)
#使用冒泡排序
print("排序前:",data)
bubbleSort(data)
print("排序后:",data)
程序中我们定义了排序函数,主程序的逻辑就是现实排序前列表、排序、最后显示排序后列表。
排序中,外循环跟刚才解释的完全一样,范围是从0到n-1。这里有一个小迷惑点,我们知道range本身就不会产生最后一个边界的数字,相当于进行了n-1,为啥还要n-1呢?原因依然是列表类型下标是从0开始,因此10个元素,最后一个元素的下标是9。
内循环的结束边界是n-i-1,n-1容易理解,但是我们讲过了,每次都要再少1次循环,因为已经冒泡到最上面1个元素不需要再被比较,所以内循环使用了外循环的变量i,使得个完整的内循环都比上次更少循环一次。
if语句用来比较当前元素和其后的一个元素,如果当前元素更小,则交换当前元素跟后面的元素。交换所使用的语句我们前面学过了,希望你还记得。
后面两个print函数被注释掉了,对于这个排序它们没意义,它们是调试程序的时候使用的。如果显示出来的话,跟我们上面的两张图将是一样的。
上面是冒泡排序完整的讲述。
接着要讲一个额外的概念。我们前面一直讲,Python自定义函数的参数,主要用来传递数据到函数内,函数的返回值应当用return来返回。但可能你注意到了,在上面的冒泡排序中,数据的输入、输出都使用了自定义函数的参数data。
这里面有两方面的原因,部分我们在第三讲讲过,这里再完整讲一遍:
- 函数的参数用来传递进入函数的参数,return返回函数的结果这是良好编程的理念要求,是建议性的,不是强制性的。的确有的时候直接使用参数本身传入、传出数值看上去更自然,并且不影响程序的可读性和可维护性。在数据量比较大的时候,比如一个很大的列表,这种方式也更快,因为不需要为新的变量分配内存和复制参数的值,这时候是可以使用这种方式的。
- Python中的数据类型,分为可改变和不可改变两种类型,可改变的数据类型,比如列表类型,可以用于函数传入、传出参数;但不可变更类型,比如字符串,比如数值,都是不可改变类型,所以仅能用于把参数传递进入函数,并不能用于传递结果返回。
上面这段好费解是吧,我们可能看过这样的例子:
a = 1;
a = a + 1;
这个例子中,我们不是等于修改了a的值吗?
这个问题完全解释,需要再学习许多计算机更底层技术的来龙去脉,这超出了本课程的范围。大致的解释一下:
a=1 是第一次使用a变量,相当于在电脑中申请了一部分内存,用于保存a变量。而下面a=a+1,看上去 变量名没有变,但实际上是另外申请了一个变量a,新变量a的值,是老变量a+1之后的值。这样复制之后,原有的变量a将被回收。
而列表变量data,第一次复制的时候,同样是申请了一大块内存空间,用于保存data的所有元素。对data内部元素的任何复制、改变,都只是修改data内部的空间,并没有影响data本身。反过来,如果再次进行了data=[...]这样的赋值操作,则原有的data就又被回收了,取而代之的是新的data变量。
那么字符串变量呢?字符串变量看起来很像列表啊?修改其内部的某个字符应当不影响字符串变量本身吧?能不能用于传递参数呢?
答案是不能,字符串变量为了提高处理效率,在Python中是共用的,换言之,很多程序中,会有很多相同字符串或者部分相同字符串,这时候为了提高效率,Python是会共用这部分字符串所占用的内存的。这也导致字符串不能修改其本身,因为这会影响其它可能共享它的字符串。
实际在Python六大基本类型中,只有2中类型,包括列表,是可被修改的。其它类型都是只读类型。
上面的排序程序,同时演示了data参数传入、传出的应用。下面给一段代码,来让你看看只读类型无法传递结果到函数之外的情况:
def somefunc(x):
x=25 #x是数值类型,不会被传递回
return 10
a=15
somefunc(a)
print(a)
#最后的显示仍然是15,表示函数中的修改并没有能传递出函数
这部分内容,难度比较大,如果不能完全理解,可以做一般性了解即可。因为在常规的编程中,这部分知识暂时不需要用到。
最后看看Python内置的排序函数,有两个版本,一个是列表类型所包含的,一个是内置的通用函数,我们直接用源码来讲解:
#列表内置的排序操作
a=[12,78,23,5.5,9.2,90,332,45]
a.sort()
print(a)
==> [5.5, 9.2, 12, 23, 45, 78, 90, 332]
a.sort(reverse=True) #通常函数传参是按照前后顺序,也可以按照参数名
#reverse就是参数名,为真表示逆序排序
==> [332, 90, 78, 45, 23, 12, 9.2, 5.5]
#python内置的通用排序函数
sorted(a)
sorted(a,reverse=True) #逆序
使用上述排序函数的时候,要保证列表中的类型是统一的,否则会报错,请看示例:
a = [12,78,23,True,5.5,9.2,90,0.3,45]
a.sort() #注意True是数字类型的子类型,算同一种类型,实际是数值1
print(a)
==>[0.3, True, 5.5, 9.2, 12, 23, 45, 78, 90]
a = [12,78,23,True,5.5,"9.2",90,332,45]
a.sort() #排序失败,因为有字符串类型
练习时间
- 请用户输入10个数字,逆输入顺序显示出来,并显示10个数字的总和及平均值
- 将问题1中的10个数字使用冒泡排序,由大到小排列
- 将问题1中10个数字使用冒泡排序,由小到大排列
本讲小结
- 列表类型是各类语言中最常用的数据结构之一,应用范围很广,在其它语言中一般称为”数组“
- 排序是最常用的算法之一,有很多种排序的算法,冒泡排序是最简单易懂也易用的
- 算法跟数据结构通常都是一起考虑的
练习题答案
请参考源码ex1.py
