TensorFlow从1到2(七)
线性回归模型预测汽车油耗以及训练过程优化
![]()
线性回归模型
“回归”这个词,既是Regression算法的名称,也代表了不同的计算结果。当然结果也是由算法决定的。
不同于前面讲过的多个分类算法或者逻辑回归,线性回归模型的结果是一个连续的值。
实际上我们第一篇的房价预测就属于线性回归算法,如果把这个模型用于预测,结果是一个连续值而不是有限的分类。
从代码上讲,那个例子更多的是为了延续从TensorFlow 1.x而来的解题思路,我不想在这个系列的第一篇就给大家印象,TensorFlow 2.0成为了完全不同的另一个东西。在TensorFlow 2.0中,有更方便的方法可以解决类似问题。
线性回归算法在大多数机器学习课程中,也都是最早会学习的算法。所以对这个算法,我们都不陌生。
因此本篇的重点不在算法本身,也不在油耗的预测,而是通过油耗预测这样简单的例子,介绍在TensorFlow 2.0中,如何更好的对训练过程进行监控和管理,还有其它一些方便有效的小技巧。
了解样本数据
在机器学习算法本身没有大的突破的情况下,对样本数据的选取、预处理往往是项目成功的关键。我们接续前一篇继续说一说样本数据。
样本数据的预处理依靠对样本数据的了解和分析。Python的交互模式配合第三方工具包则是对样本数据分析的强力武器。
下面我们使用Python的交互模式,载入油耗预测的样本数据,先直观的看一下样本数据:
(第一次载入样本数据会从网上下载,速度比较慢)
$ python3
Python 3.7.3 (default, Mar 27 2019, 09:23:39)
[Clang 10.0.0 (clang-1000.11.45.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from tensorflow import keras
>>> import pandas as pd
>>> dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
>>> column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
... 'Acceleration', 'Model Year', 'Origin']
>>> raw_dataset = pd.read_csv(dataset_path, names=column_names,
... na_values = "?", comment='\t',
... sep=" ", skipinitialspace=True)
>>>
>>> raw_dataset.tail()
MPG Cylinders Displacement Horsepower Weight Acceleration Model Year Origin
393 27.0 4 140.0 86.0 2790.0 15.6 82 1
394 44.0 4 97.0 52.0 2130.0 24.6 82 2
395 32.0 4 135.0 84.0 2295.0 11.6 82 1
396 28.0 4 120.0 79.0 2625.0 18.6 82 1
397 31.0 4 119.0 82.0 2720.0 19.4 82 1
>>> raw_dataset
MPG Cylinders Displacement Horsepower Weight Acceleration Model Year Origin
0 18.0 8 307.0 130.0 3504.0 12.0 70 1
1 15.0 8 350.0 165.0 3693.0 11.5 70 1
2 18.0 8 318.0 150.0 3436.0 11.0 70 1
3 16.0 8 304.0 150.0 3433.0 12.0 70 1
.. ... ... ... ... ... ... ... ...
373 24.0 4 140.0 92.0 2865.0 16.4 82 1
374 23.0 4 151.0 NaN 3035.0 20.5 82 1
.. ... ... ... ... ... ... ... ...
396 28.0 4 120.0 79.0 2625.0 18.6 82 1
397 31.0 4 119.0 82.0 2720.0 19.4 82 1
[398 rows x 8 columns]
>>>
本篇就不用表格来逐行解释属性列的含义了,我们会在用到的每一列单独说明。
使用raw_dataset.tail()列出数据的最后几行,显示数据一共只有398行。说明数据集并不是很大,可以直接全部列出来粗略的看一下。这一步使用Excel之类的工具效果可能更好。不过习惯命令行操作的工程师直接列出也是一样的。
数据中可以看到第374行,在Horsepower(发动机功率)一列,意外的有NaN未知数据。这样的数据当然是无效的,需要首先进行数据清洗。大数据转行过来的技术人员都熟悉,数据清洗是保证数据有效性必不可少的手段。
其实这里的NaN并不能完全说意外,我们在使用Pandas打开数据集的时候使用了参数:na_values = “?”,这是指数据集中如果有“?”字符,则数据当做无效数据,方便后续使用内置方法处理。这个参数可以根据你获取的数据集修改。
比如检查数据集是否有无效数据可以使用isna()方法:
>>> # 继续上面的交互操作
...
>>> raw_dataset.isna().sum()
MPG 0
Cylinders 0
Displacement 0
Horsepower 6
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int64
>>>
>>> # 确认有6个无效数据,需要抛弃相应行
... # 将数据复制一份,防止误操作
...
>>> dataset = raw_dataset.copy()
>>>
>>> # 抛弃无效数据所在行
...
>>> dataset = dataset.dropna()
>>>
接着Origin一列,实际是一个分类类型,并不是数字。分别代表车型的产地为美国、欧洲或者日本。上一篇中我们已经有了经验,我们要把这个数据列转成one-hot编码方式:
>>> # 取出Origin数据列,原数据集中将不会再有这一列
...
>>> origin = dataset.pop('Origin')
>>>
>>> # 根据分类编码,分别为新对应列赋值1.0
...
>>> dataset['USA'] = (origin == 1)*1.0
>>> dataset['Europe'] = (origin == 2)*1.0
>>> dataset['Japan'] = (origin == 3)*1.0
>>>
>>> # 列出新的数据集尾部,以观察结果
...
>>> dataset.tail()
MPG Cylinders Displacement Horsepower Weight Acceleration Model Year USA Europe Japan
393 27.0 4 140.0 86.0 2790.0 15.6 82 1.0 0.0 0.0
394 44.0 4 97.0 52.0 2130.0 24.6 82 0.0 1.0 0.0
395 32.0 4 135.0 84.0 2295.0 11.6 82 1.0 0.0 0.0
396 28.0 4 120.0 79.0 2625.0 18.6 82 1.0 0.0 0.0
397 31.0 4 119.0 82.0 2720.0 19.4 82 1.0 0.0 0.0
>>>
不同前一篇,这次做One-hot编码的方式直接使用了Python语言的逻辑计算表达式,效果一样好。
关于怎么知道哪个数字代表哪个产地,如果是自己设计的数据采集方式,你自己当然应当知道。如果使用了别人的数据集,应当仔细阅读数据的说明。这里就不多解释了。
我们还可以使用seaborn工具(第一篇中已经安装了)对数据做进一步分析,seaborn包含一组散列图绘制工具,可以更直观的揭示数据之间的关联:
>>> # 继续上面的交互操作
...
>>> import seaborn as sns
>>> import matplotlib.pyplot as plt
>>> sns.pairplot(dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
<seaborn.axisgrid.PairGrid object at 0x139405358>
>>> plt.show()
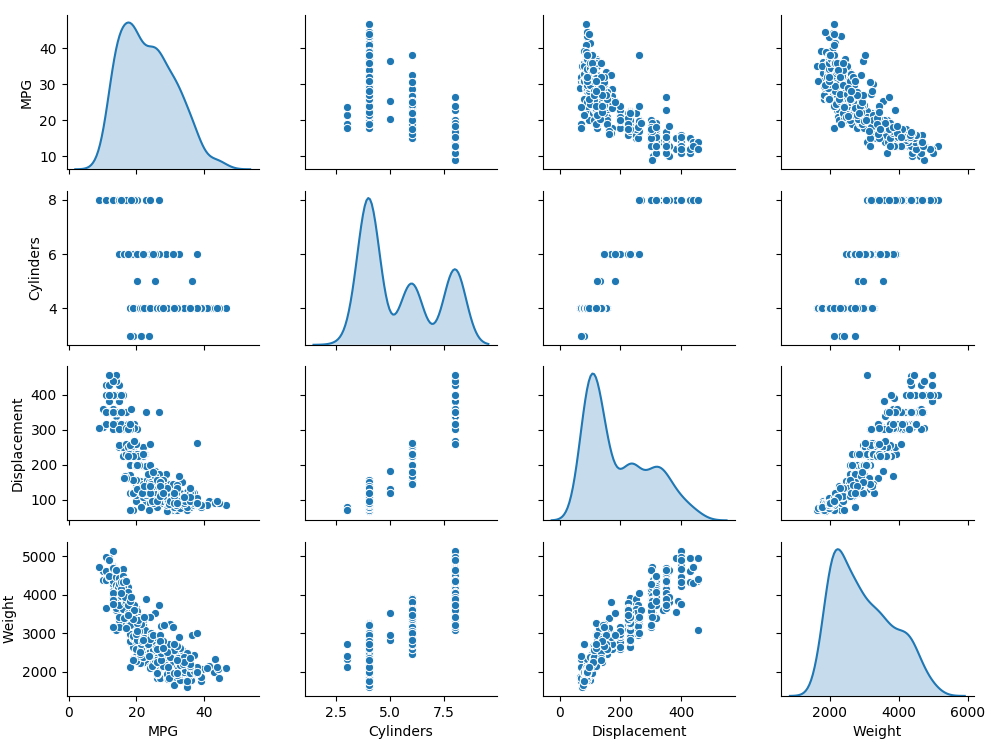
上图选取了MPG(油耗)、Cylinders(气缸数量)、Displacement(排气量)、Weight(车重)四项数据,做两两对比形成的散点图。
散点矩阵图(SPLOM:Scatterplot Matrix)可以用于粗略揭示数据中,不同列之间的相关性。可以粗略估计哪些变量是正相关的,哪些是负相关的,进而为下一步数据分析提供决策。当然这些图需要行业专家的理解和分析。然后为程序人员提供间接帮助。
数据规范化
从刚才的样本数据中,我们可以看出各列的数据,取值范围还是很不均衡的。在进入模型之前,我们需要做数据规范化。也就是将所有列的数据统一为在同一个取值范围的浮点数。
我们可以利用Pandas中对数据的统计结果做数据的规范化,这样可以省去自己写程序做数据统计。
>>> # 继续上面的交互操作
...
>>> data_stats=dataset.describe()
>>> data_stats
MPG Cylinders Displacement Horsepower ... Model Year USA Europe Japan
count 392.000000 392.000000 392.000000 392.000000 ... 392.000000 392.000000 392.000000 392.000000
mean 23.445918 5.471939 194.411990 104.469388 ... 75.979592 0.625000 0.173469 0.201531
std 7.805007 1.705783 104.644004 38.491160 ... 3.683737 0.484742 0.379136 0.401656
min 9.000000 3.000000 68.000000 46.000000 ... 70.000000 0.000000 0.000000 0.000000
25% 17.000000 4.000000 105.000000 75.000000 ... 73.000000 0.000000 0.000000 0.000000
50% 22.750000 4.000000 151.000000 93.500000 ... 76.000000 1.000000 0.000000 0.000000
75% 29.000000 8.000000 275.750000 126.000000 ... 79.000000 1.000000 0.000000 0.000000
max 46.600000 8.000000 455.000000 230.000000 ... 82.000000 1.000000 1.000000 1.000000
[8 rows x 10 columns]
>>>
对于每一列,Pandas都进行了记录总数、平均值、标准差、最小值等统计。我们做数据规范化,可以直接使用这些参数来进行。
>>> # 继续上面的交互操作
...
>>> data_stats=data_stats.transpose()
>>> data_stats
count mean std min 25% 50% 75% max
MPG 392.0 23.445918 7.805007 9.0 17.000 22.75 29.000 46.6
Cylinders 392.0 5.471939 1.705783 3.0 4.000 4.00 8.000 8.0
Displacement 392.0 194.411990 104.644004 68.0 105.000 151.00 275.750 455.0
Horsepower 392.0 104.469388 38.491160 46.0 75.000 93.50 126.000 230.0
Weight 392.0 2977.584184 849.402560 1613.0 2225.250 2803.50 3614.750 5140.0
Acceleration 392.0 15.541327 2.758864 8.0 13.775 15.50 17.025 24.8
Model Year 392.0 75.979592 3.683737 70.0 73.000 76.00 79.000 82.0
USA 392.0 0.625000 0.484742 0.0 0.000 1.00 1.000 1.0
Europe 392.0 0.173469 0.379136 0.0 0.000 0.00 0.000 1.0
Japan 392.0 0.201531 0.401656 0.0 0.000 0.00 0.000 1.0
>>> norm_data = (dataset - data_stats['mean'])/data_stats['std']
>>> norm_data.tail()
MPG Cylinders Displacement Horsepower Weight Acceleration Model Year USA Europe Japan
393 0.455359 -0.862911 -0.519972 -0.479835 -0.220842 0.021267 1.634321 0.773608 -0.457538 -0.501749
394 2.633448 -0.862911 -0.930889 -1.363154 -0.997859 3.283479 1.634321 -1.289347 2.180035 -0.501749
395 1.095974 -0.862911 -0.567753 -0.531795 -0.803605 -1.428605 1.634321 0.773608 -0.457538 -0.501749
396 0.583482 -0.862911 -0.711097 -0.661694 -0.415097 1.108671 1.634321 0.773608 -0.457538 -0.501749
397 0.967851 -0.862911 -0.720653 -0.583754 -0.303253 1.398646 1.634321 0.773608 -0.457538 -0.501749
>>>
初步的程序
有了上面这些尝试,开始着手编程,主要有以下几步工作:
- 将样本数据集分为训练集和测试集两部分
- 将数据集中的MPG(百英里油耗数)去掉,单独出来作为数据集的标注结果,达成监督学习
- 构建模型,编译模型
- 使用训练集数据对模型进行训练
- 使用测试集样本进行数据预测,评估模型效果
我们使用附带注释的源码来代替讲解:
#!/usr/bin/env python3
from __future__ import absolute_import, division, print_function
# 引入各项扩展库
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 下载样本数据
dataset_path = keras.utils.get_file("auto-mpg.data", "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
# 样本中所需要的列名称
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
# 从样本文件中读取指定列的数据
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values="?", comment='\t',
sep=" ", skipinitialspace=True)
# 复制一份数据做后续操作
dataset = raw_dataset.copy()
# 数据清洗,去掉无意义的数据
dataset = dataset.dropna()
# 将Origin数据做one-hot编码,相当于转换成3个产地字段
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
# 随机分配80%的数据作为训练集
# frac是保留80%的数据
# random_state相当于随机数的种子,在这里固定一个值是为了每次运行,随机分配得到的样本集是相同的
train_dataset = dataset.sample(frac=0.8, random_state=0)
# 训练集的数据去除掉,剩下的是20%,作为测试集
test_dataset = dataset.drop(train_dataset.index)
# 获取数据集的统计信息
train_stats = train_dataset.describe()
# MPG是训练模型要求的结果,也就是标注字段,没有意义,从统计中去除
train_stats.pop("MPG")
# 对统计结果做行列转置,方便将统计结果作为下面做数据规范化的参数
train_stats = train_stats.transpose()
# 训练集和测试集的数据集都去掉MPG列,单独取出作为标注
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
# 定义一个数据规范化函数帮助简化操作
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
# 训练集和测试集数据规范化
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
# 构建回归模型
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1) # 回归的主要区别就是最后不需要激活函数,从而保证最后是一个连续值
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['acc'])
return model
model = build_model()
# 显示构造的模型
model.summary()
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split=0.2, verbose=1)
# 使用测试集预测数据
test_result = model.predict(normed_test_data)
# 显示预测结果
print('===================\ntest_result:', test_result)
使用的模型非常简单,训练和预测也没有什么特别之处,无需再讲解。执行程序的输出大致如下:
$ ./mpg1.py
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 640
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
_________________________________________________________________
Train on 251 samples, validate on 63 samples
Epoch 1/1000
251/251 [==============================] - 0s 2ms/sample - loss: 582.3197 - acc: 0.0000e+00 - val_loss: 582.2971 - val_acc: 0.0000e+00
Epoch 2/1000
251/251 [==============================] - 0s 67us/sample - loss: 542.1007 - acc: 0.0000e+00 - val_loss: 541.7508 - val_acc: 0.0000e+00
......
Epoch 1000/1000
251/251 [==============================] - 0s 58us/sample - loss: 2.7232 - acc: 0.0000e+00 - val_loss: 9.4673 - val_acc: 0.0000e+00
===================
test_result: [[16.366997 ]
[ 8.665408 ]
[ 8.548 ]
[25.14063 ]
[18.678812 ]
......
输出的数据中,一开始是所使用的模型信息,这是model.summary()输出的结果。如果有时间,翻翻前面vgg-19和resnet50网络的模型,也试用一下,保证你得到一个惊讶的结果:)
随后是1000次迭代的训练输出。最后是预测的结果。
如果你细心的话,可能已经发现了问题,从第一个训练周期开始,一直到第1000次,虽然损失loss在降低,但正确率acc一直为0,这是为什么?
其实看看最后的预测结果就知道了。对于这种连续输出值的回归问题,结果不是有限的分类,而是很精确的浮点数。这样的结果,只能保证大体比例上,同标注集是吻合的,不可能做到一一对应的相等。这是所有的正确率结果为0的原因,也是我们没有跟前面的例子一样,使用model.evaluate对模型进行评估的原因。
由此可见,我们在模型编译的时候选取评价指标参数为’acc’(正确率)就是不合理的。替代的,我们可以使用MAE(Mean Abs Error)平均绝对误差或者MSE(Mean Square Error)均方根误差/标准误差。
此外你可能看到了,程序数据集简单、模型也简单,所以训练速度很快。1000次的迭代训练,信息输出本身占用的时间甚至多过了训练所需的时间。
model.fit()训练函数中可以指定verbose=0来屏蔽输出,但完全没有输出也是很不友好的。我们可以使用前面用过的回调函数机制,来显示自定义的输出内容。比如我们可以在每个训练循环中输出一个“.”来显示训练的进展。
来改进一下程序,用以下程序段来替代上面代码中,”构建回归模型”之后所有的内容。
# 替代前面代码中,构建回归模型以下内容
# 构建回归模型
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1) # 回归的主要区别就是最后不需要激活函数,从而保证最后是一个连续值
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
# 自定义一个类,实现keras的回调,在训练过程中显示“.”
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0:
print('')
print('.', end='')
model = build_model()
# 显示构造的模型
model.summary()
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split=0.2, verbose=0,
callbacks=[PrintDot()])
# 使用测试集评估模型
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=0)
# 显示评估结果
print("\nTesting set Mean Abs Error: {:5.2f} MPG".format(mae))
再次执行,输出结果看起来干净多了:
$ ./mpg2.py
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 640
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
_________________________________________________________________
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
Testing set Mean Abs Error: 1.98 MPG
最后我们也敢使用model.evaluate对模型进行评估了,得到的MAE是1.98。
但是MAE、MSE的数据,重点的是看训练过程中的动态值,根据趋势调整我们的程序,才谈得上优化。只有最终一个值其实意义并不大。
我们继续为程序增加功能,用图形绘制出训练过程的指标变化情况。前面的程序中,我们已经使用history变量保存了训练过程的输出信息,下面就是使用matplotlib将数值绘出。
# 接着上面的代码,在最后添加以下内容:
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
# plt.figure()
plt.figure('MAE --- MSE', figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(
hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(
hist['epoch'], hist['val_mae'],
label='Val Error')
plt.ylim([0, 5])
plt.legend()
plt.subplot(1, 2, 2)
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(
hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(
hist['epoch'], hist['val_mse'],
label='Val Error')
plt.ylim([0, 20])
plt.legend()
plt.show()
plot_history(history)
执行程序,可以得到下图的结果:
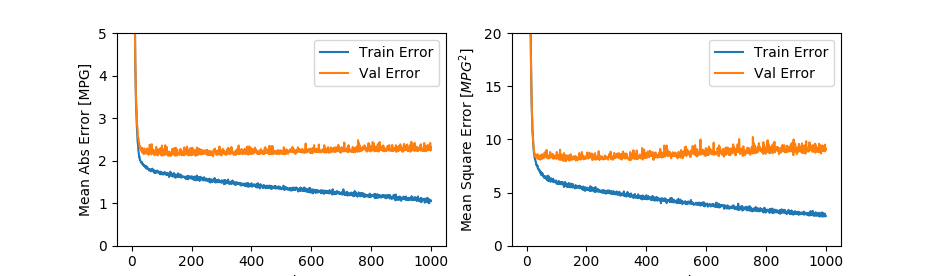 从图中可以看出,虽然随着迭代次数的增加,训练错误率在降低,但大致从100次迭代之后,验证的错误率就基本稳定不变了。限于样本集数量及维度选取、模型设计等方面的原因,对这个结果的满意度先放在一边。这个模型在100次迭代之后就长时间无效的训练显然是一个可优化的点。
从图中可以看出,虽然随着迭代次数的增加,训练错误率在降低,但大致从100次迭代之后,验证的错误率就基本稳定不变了。限于样本集数量及维度选取、模型设计等方面的原因,对这个结果的满意度先放在一边。这个模型在100次迭代之后就长时间无效的训练显然是一个可优化的点。
TensorFlow/Keras提供了EarlyStopping机制来应对这种问题,EarlyStopping也是一个回调函数,请看我们实现的代码:
# 以下代码添加到前面代码的最后
# 设置EarlyStopping回调函数,监控val_loss指标
# 当该指标在10次迭代中均不变化后退出
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
# 再次训练模型
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
# 绘制本次训练的指标曲线
plot_history(history)
执行后,这次得到的结果令人满意了,大致在60次迭代之后,就得到了同前面1000次迭代基本相似的结果:
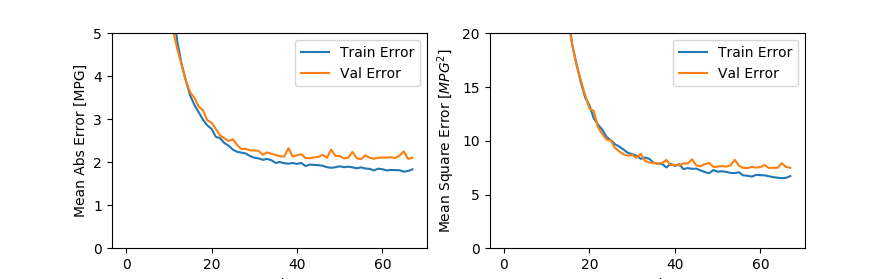 既然训练完成,虽然我们使用模型预测的结果无法跟原标注一对一比较,我们可以用图形的方式来比较一下两组值,并做一下预测错误统计:
既然训练完成,虽然我们使用模型预测的结果无法跟原标注一对一比较,我们可以用图形的方式来比较一下两组值,并做一下预测错误统计:
# 继续在最后增加如下代码
# 使用测试集数据用模型进行预测
test_predictions = model.predict(normed_test_data).flatten()
# 绘制同标注的对比图和两者误差分布的直方图
plt.figure('Prediction & TrueValues --- Error', figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0, plt.xlim()[1]])
plt.ylim([0, plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
error = test_predictions - test_labels
plt.subplot(1, 2, 2)
plt.hist(error, bins=25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")
plt.show()
程序得到结果图如下:
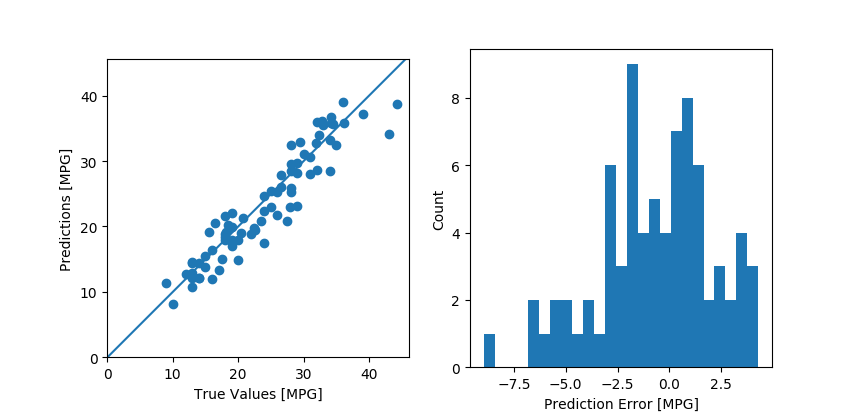 左边的图中,如果预测结果同标注结果完全一致,蓝色的点将落在主对角线上,偏离对角线则代表预测误差。从图中可以看出,所有的点大致是落在主对角线周边的。这表示预测结果同标注值基本吻合。
左边的图中,如果预测结果同标注结果完全一致,蓝色的点将落在主对角线上,偏离对角线则代表预测误差。从图中可以看出,所有的点大致是落在主对角线周边的。这表示预测结果同标注值基本吻合。
右边的图是两者之差的范围统计结果,可以理解为左图逆时针逆时针旋转45度后所有点统计的直方图,对角线就是误差为0的位置。图中能看出误差基本符合正态分布,代表预测数值偏大、偏小的数量和比例基本相似,模型是可信的。
当然限于样本数量过少的问题,模型的优化余地还是很大的。
(待续…)
