TensorFlow从1到2(八)
过拟合和欠拟合的优化
![]()
《从锅炉工到AI专家(6)》一文中,我们把神经网络模型降维,简单的在二维空间中介绍了过拟合和欠拟合的现象和解决方法。但是因为条件所限,在该文中我们只介绍了理论,并没有实际观察现象和应对。
现在有了TensorFLow 2.0 / Keras的支持,可以非常容易的构建模型。我们可以方便的人工模拟过拟合的情形,实际来操作监控、调整模型,从而显著改善模型指标。
从图中识别过拟合和欠拟合
先借用上一篇的两组图:
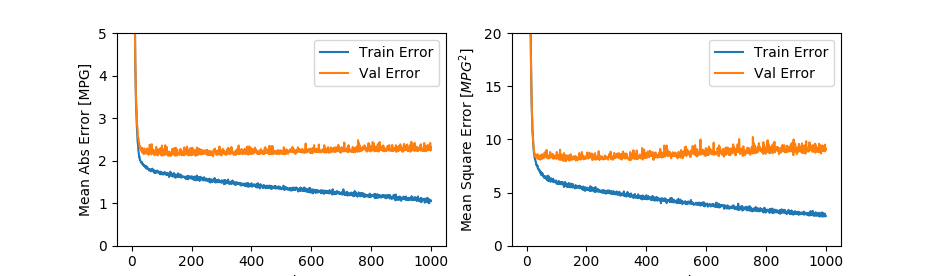
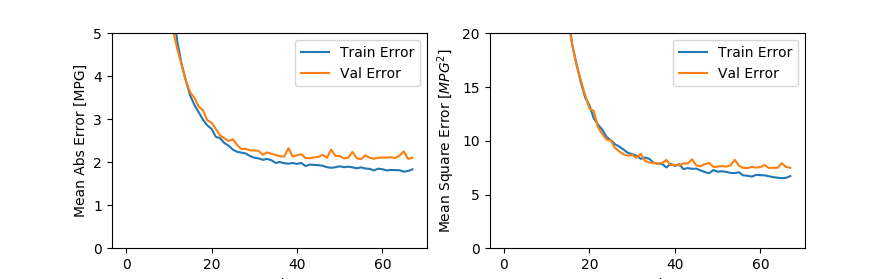 先看上边的一组图,随着训练迭代次数的增加,预测的错误率迅速下降。
先看上边的一组图,随着训练迭代次数的增加,预测的错误率迅速下降。
我们上一篇中讲,达到一定迭代次数之后,验证的错误率就稳定不变了。实际上你仔细观察,训练集的错误率在稳定下降,但验证集的错误率还会略有上升。两者之间的差异越来越大,图中的两条曲线,显著分离了,并且分离的趋势还在增加。这就是过拟合的典型特征。
这表示,模型过分适应了当前的训练集数据,对于训练集数据有了较好表现。对于之外的数据,反而不适应,从而效果很差。
这通常都是由于较小的数据样本造成的。如果数据集足够大,较多的训练通常都能让模型表现的更好。过拟合对于生产环境伤害是比较大的,因为生产中大多接收到的都是新数据,而过拟合无法对这些新数据达成较好表现。
所以如果数据集不够的情况下,采用适当的迭代次数可能是更好的选择。这也是上一节我们采用EarlyStopping机制的原因之一。最终的表现是上边下面一组图的样子。
欠拟合与此相反,表示模型还有较大改善空间。上面两组图中,左侧下降沿的曲线都可以认为是欠拟合。表现特征是无论测试集还是验证集,都没有足够的正确率。当然也因此,测试集和验证集表现类似,拟合非常紧密。
欠拟合的情况,除了训练不足之外,模型不够强大或者或者模型不适合业务情况都是可能的原因。
实验模拟过拟合
我们使用IMDB影评样本库来做这个实验。实验程序主要部分来自于本系列第五篇中第二个例子,当然有较大的修改。
程序主要分为几个部分:
- 下载IMDB影评库(仅第一次),载入内存,并做单词向量化。
- 单词向量化编码使用了multi-hot-sequences,这种编码跟one-hot类似,但一句话中有多个单词,因此会有多个’1’。一个影评就是一个0、1序列。这种编码模型非常有用,但在本例中,数据歧义会更多,更容易出现过拟合。
- 定义baseline/small/big三个不同规模的神经网络模型,并分别编译训练,训练时保存过程数据。
- 使用三组过程数据绘制曲线图,指标是binary_crossentropy,这是我们经常当做损失函数使用的指征,这个值在正常训练的时候收敛到越小越好。
程序中,文本的编码方式、模型都并不是很合理,因为我们不是想得到一个最优的模型,而是想演示过拟合的场景。
#!/usr/bin/env python3
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
NUM_WORDS = 10000
# 载入IMDB样本数据
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
# 将单词数字化,转化为multi-hot序列编码方式
def multi_hot_sequences(sequences, dimension):
# 建立一个空矩阵保存结果
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0 # 出现过的词设置为1.0
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
# 建立baseline模型,并编译训练
baseline_model = keras.Sequential([
# 指定`input_shape`以保证下面的.summary()可以执行,
# 否则在模型结构无法确定
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
# 小模型定义、编译、训练
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
smaller_model.summary()
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
# 大模型定义、编译、训练
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
# 绘图函数
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(
history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(
history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plt.show()
# 绘制三个模型的三组曲线
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
程序在命令行的输出就不贴出来了,除了输出的训练迭代过程,在之前还输出了每个模型的summary()。这里主要看最后的binary_crossentropy曲线图。
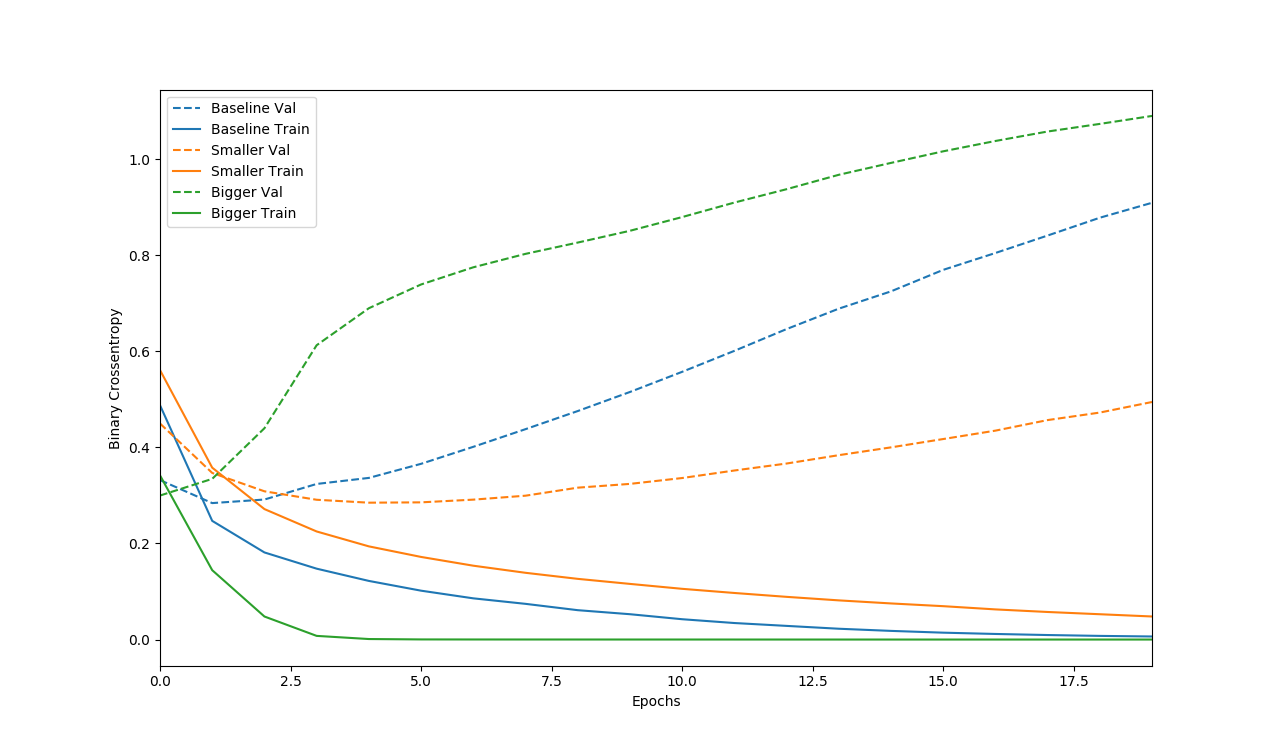
图中的虚线都是验证集数据的表现,实线是训练集数据的表现。三个模型的训练数据和测试数据交叉熵曲线都出现了较大的分离,代表出现了过拟合。尤其是bigger模型的两条绿线,几乎是一开始就出现了较大的背离。
优化过拟合
优化过拟合首先要知道过拟合产生的原因,我们借用一张前一系列讲解过拟合时候用过的图,是吴恩达老师课程的笔记:
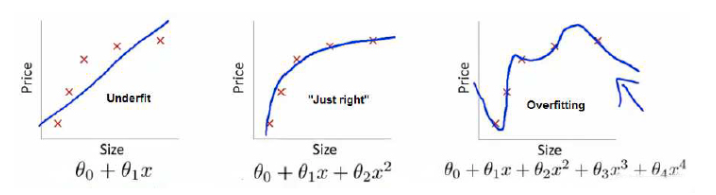 如果一个模型产生过拟合,那这个模型的总体效果就可能是一个非常复杂的非线性方程。方程非常努力的学习所有“可见”数据,导致了复杂的权重值,使得曲线弯来弯去,变得极为复杂。多层网络更加剧了这种复杂度,最终的复杂曲线绕开了可行的区域,只对局部的可见数据有效,对于实际数据命中率低。所以从我们程序跑的结果图来看,也是越复杂的网络模型,过拟合现象反而越严重。
如果一个模型产生过拟合,那这个模型的总体效果就可能是一个非常复杂的非线性方程。方程非常努力的学习所有“可见”数据,导致了复杂的权重值,使得曲线弯来弯去,变得极为复杂。多层网络更加剧了这种复杂度,最终的复杂曲线绕开了可行的区域,只对局部的可见数据有效,对于实际数据命中率低。所以从我们程序跑的结果图来看,也是越复杂的网络模型,过拟合现象反而越严重。
这么说简单的模型就好喽?并非如此,太简单的模型往往无法表达复杂的逻辑,从而产生欠拟合。其实看看成熟的那些模型比如ResNet50,都是非常复杂的结构。
过拟合既然产生的主要原因是在权重值上,我们在这方面做工作即可。
增加权重的规范化
通常有两种方法,称为L1规范化和L2规范化。前者为代价值增加一定比例的权重值的绝对值。后者增加一定比例权重值的平方值。具体的实现来源于公式,有兴趣的可以参考一下这篇文章《L1 and L2 Regularization》。
我们删除掉上面源码中的bigger模型和small模型的部分,包括模型的构建、编译和训练,添加下面的代码:
# 构建一个L2规范化的模型
l2_model = keras.models.Sequential([
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model_history = l2_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
这个模型的逻辑结构同baseline的模型完全一致,只是在前两层中增加了L2规范化的设置参数。
先不着急运行,我们继续另外一种方法。
添加DropOut
DropOut是我们在上个系列中已经讲过的方法,应用的很广泛也非常有效。
其机理非常简单,就是在一层网络中,“丢弃”一定比例的输出(设置为数值0)给下一层。丢弃的比例通常设置为0.2至0.5。这个过程只在训练过程中有效,一般会在预测过程中关闭这个机制。
我们继续在上面代码中,添加一组采用DropOut机制的模型,模型的基本结构依然同baseline相同:
dpt_model = keras.models.Sequential([
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dropout(0.5),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation='sigmoid')
])
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
dpt_model_history = dpt_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
....
# 最后的绘图函数不变,绘图语句修改如下:
plot_history([
('baseline', baseline_history),
('l2', l2_model_history),
('dropout', dpt_model_history)])
现在可以执行程序了。
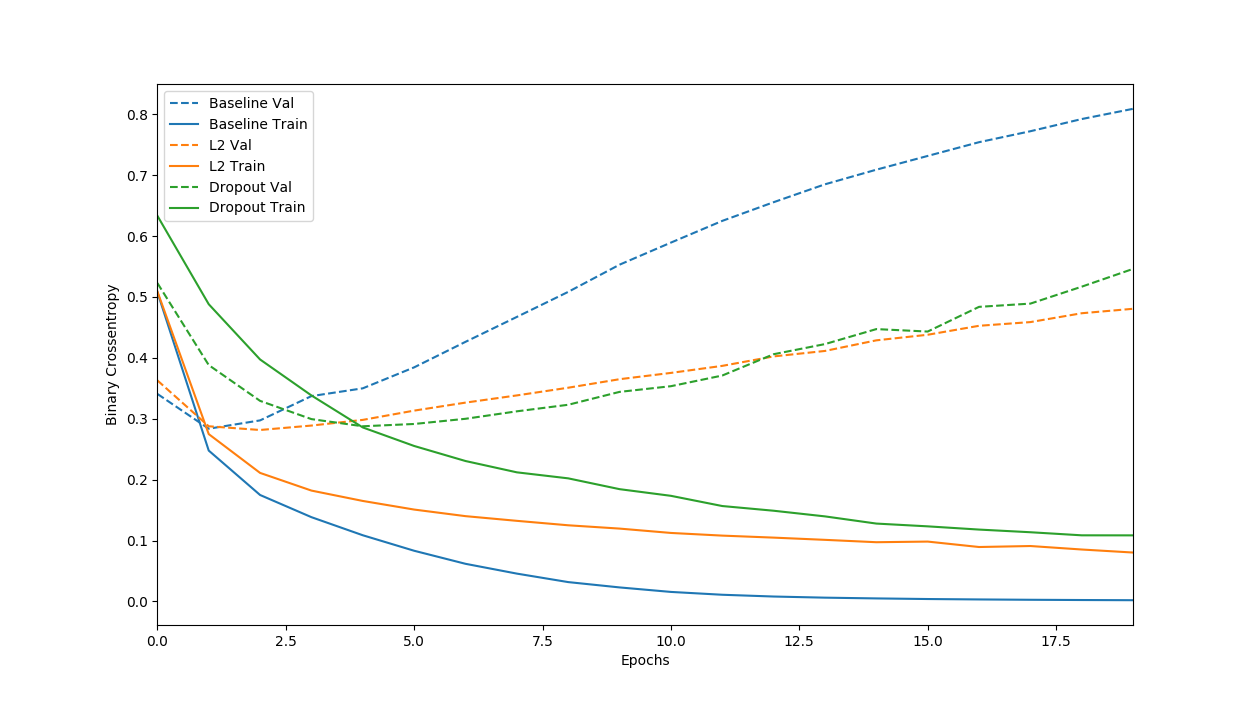
程序获得的曲线图如下,图中可见,我们在不降低模型的复杂度的情况下,L2规范化(黄色曲线)和DropOut(绿色曲线)都有效的改善了模型的过拟合问题。
(待续…)
